select,poll.epoll区别于联系
select,poll,epoll都是IO多路复用中的模型。再介绍他们特点时,先来看看多路复用的 模型。
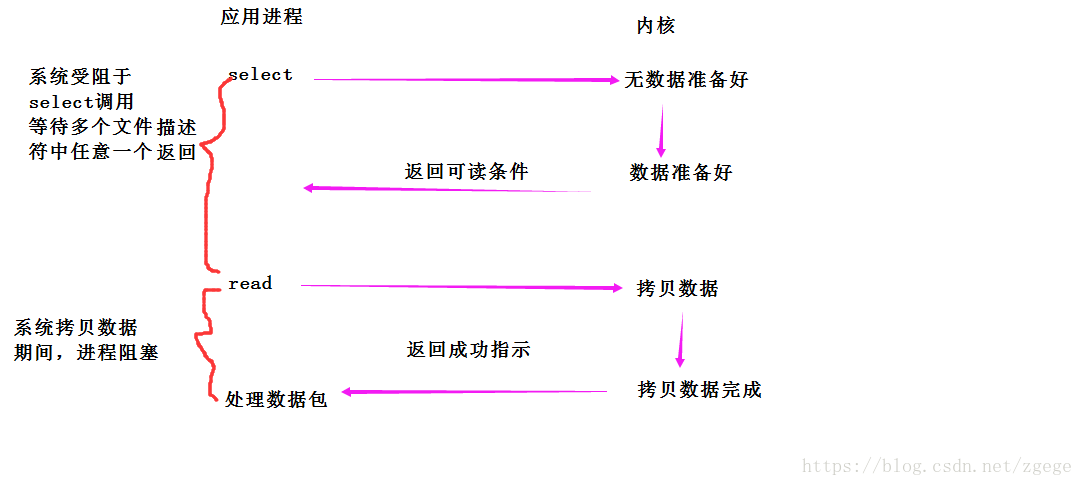
同其他IO的不同的是,IO多路复用一次可以等多个文件描述符。大大提高了等待数据准备好的时间的效率。为了完成等的效率,系统提供了三个系统调用:select,poll,epoll。这里不再讲述三者具体实现,只总结三者的优缺点。
select的缺点
1.单个进程监控的文件描述符有限,通常为1024*8个文件描述符。当然可以改进,由于select采用轮询方式扫描文件描述符。文件描述符数量越多,性能越差。
2.内核/用户数据拷贝频繁,操作复杂。select在调用之前,需要手动在应用程序里将要监控的文件描述符添加到fed_set集合中。然后加载到内核进行监控。用户为了检测时间是否发生,还需要在用户程序手动维护一个数组,存储监控文件描述符。当内核事件发生,在将fed_set集合中没有发生的文件描述符清空,然后拷贝到用户区,和数组中的文件描述符进行比对。再调用selecct也是如此。每次调用,都需要了来回拷贝。
3.轮回时间效率低。select返回的是整个数组的句柄。应用程序需要遍历整个数组才知道谁发生了变化。轮询代价大。
4、select是水平触发。应用程序如果没有完成对一个已经就绪的文件描述符进行IO操作。那么之后select调用还是会将这些文件描述符返回,通知进程。
poll特点
1.poll操作比select稍微简单点。select采用三个位图来表示fd_set,poll使用pollfd的指针,pollfd结构包含了要监视的event和发生的evevt,不再使用select传值的方法。更方便
2.select的缺点依然存在。拿select为例,加入我们的服务器需要支持100万的并发连接。则在FD_SETSIZE为1024的情况下,我们需要开辟100个并发的进程才能实现并发连接。除了进程上下调度的时间消耗外。从内核到用户空间的无脑拷贝,数组轮询等,也是系统难以接受的。因此,基于select实现一个百万级别的并发访问是很难实现的。
epoll模型
由于epoll和上面的实现机制完全不同,所以上面的问题将在epoll中不存在。在select/poll中,服务器进程每次调用select都需要把这100万个连接告诉操作系统(从用户态拷贝到内核态)。让操作系统检测这些套接字是否有时间发生。轮询完之后,再将这些句柄数据复制到操作系统中,让服务器进程轮询处理已发生的网络时间。这一过程耗时耗力,而epoll通过在linux申请一个建议的文件系统,把select调用分为了三部分。
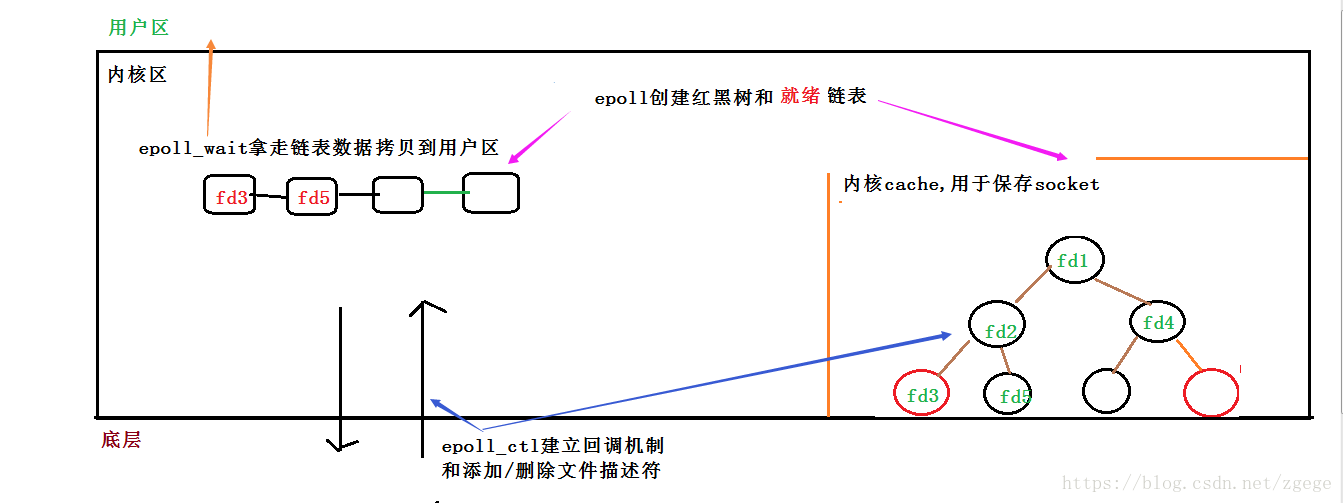
1)调用epoll_create建立一个epoll对象,这个对象包含了一个红黑树和一个双向链表。并与底层建立回调机制。
2)调用epoll_ctl向epoll对象中添加这100万个连接的套接字
3)调用epoll_wait收集发生事件的连接。
从上面的调用方式就可以看到epoll比select/poll的优越之处:因为后者每次调用时都要传递你所要监控的所有socket给select/poll系统调用,这意味着需要将用户态的socket列表copy到内核态,如果以万计的句柄会导致每次都要copy几十几百KB的内存到内核态,非常低效。而我们调用epoll_wait时就相当于以往调用select/poll,但是这时却不用传递socket句柄给内核,因为内核已经在epoll_ctl中拿到了要监控的句柄列表。
所以,实际上在你调用epoll_create后,内核就已经在内核态开始准备帮你存储要监控的句柄了,每次调用epoll_ctl只是在往内核的数据结构里塞入新的socket句柄。
在内核里,一切皆文件。所以,epoll向内核注册了一个文件系统,用于存储上述的被监控socket。当你调用epoll_create时,就会在这个虚拟的epoll文件系统里创建一个file结点。当然这个file不是普通文件,它只服务于epoll。
epoll在被内核初始化时(操作系统启动),同时会开辟出epoll自己的内核高速cache区,用于安置每一个我们想监控的socket,这些socket会以红黑树的形式保存在内核cache里,以支持快速的查找、插入、删除。这个内核高速cache区,就是建立连续的物理内存页,然后在之上建立slab层,简单的说,就是物理上分配好你想要的size的内存对象,每次使用时都是使用空闲的已分配好的对象。
epoll的高效
epoll的高效就在于,当我们调用epoll_ctl往里塞入百万个句柄时,epoll_wait仍然可以飞快的返回,并有效的将发生事件的句柄给我们用户。这是由于我们在调用epoll_create时,内核除了帮我们在epoll文件系统里建了个file结点,在内核cache里建了个红黑树用于存储以后epoll_ctl传来的socket外,还会再建立一个list链表,用于存储准备就绪的事件,当epoll_wait调用时,仅仅观察这个list链表里有没有数据即可。有数据就返回,没有数据就sleep,等到timeout时间到后即使链表没数据也返回。所以,epoll_wait非常高效。而且,通常情况下即使我们要监控百万计的句柄,大多一次也只返回很少量的准备就绪句柄而已,所以,epoll_wait仅需要从内核态copy少量的句柄到用户态而已,如何能不高效?!
就绪list链表维护
那么,这个准备就绪list链表是怎么维护的呢?当我们执行epoll_ctl时,除了把socket放到epoll文件系统里file对象对应的红黑树上之外,还会给内核中断处理程序注册一个回调函数,告诉内核,如果这个句柄的中断到了,就把它放到准备就绪list链表里。所以,当一个socket上有数据到了,内核在把网卡上的数据copy到内核中后就来把socket插入到准备就绪链表里了。
如此,一颗红黑树,一张准备就绪句柄链表,少量的内核cache,就帮我们解决了大并发下的socket处理问题。执行epoll_create时,创建了红黑树和就绪链表,执行epoll_ctl时,如果增加socket句柄,则检查在红黑树中是否存在,存在立即返回,不存在则添加到树干上,然后向内核注册回调函数,用于当中断事件来临时向准备就绪链表中插入数据。执行epoll_wait时立刻返回准备就绪链表里的数据即可。
两种模式LT和ET
最后看看epoll独有的两种模式LT和ET。无论是LT和ET模式,都适用于以上所说的流程。区别是,LT模式下,只要一个句柄上的事件一次没有处理完,会在以后调用epoll_wait时次次返回这个句柄,而ET模式仅在第一次返回。
这件事怎么做到的呢?当一个socket句柄上有事件时,内核会把该句柄插入上面所说的准备就绪list链表,这时我们调用epoll_wait,会把准备就绪的socket拷贝到用户态内存,然后清空准备就绪list链表,最后,epoll_wait干了件事,就是检查这些socket,如果不是ET模式(就是LT模式的句柄了),并且这些socket上确实有未处理的事件时,又把该句柄放回到刚刚清空的准备就绪链表了。所以,非ET的句柄,只要它上面还有事件,epoll_wait每次都会返回。而ET模式的句柄,除非有新中断到,即使socket上的事件没有处理完,也是不会次次从epoll_wait返回的。
其中涉及到的数据结构:
epoll用kmem_cache_create(slab分配器)分配内存用来存放struct epitem和struct eppoll_entry。
当向系统中添加一个fd时,就创建一个epitem结构体,这是内核管理epoll的基本数据结构:
struct epitem {
struct rb_node rbn; //用于主结构管理的红黑树
struct list_head rdllink; //事件就绪队列
struct epitem *next; //用于主结构体中的链表
struct epoll_filefd ffd; //这个结构体对应的被监听的文件描述符信息
int nwait; //poll操作中事件的个数
struct list_head pwqlist; //双向链表,保存着被监视文件的等待队列,功能类似于select/poll中的poll_table
struct eventpoll *ep; //该项属于哪个主结构体(多个epitm从属于一个eventpoll)
struct list_head fllink; //双向链表,用来链接被监视的文件描述符对应的struct file。因为file里有f_ep_link,用来保存所有监视这个文件的epoll节点
struct epoll_event event; //注册的感兴趣的事件,也就是用户空间的epoll_event
}
而每个epoll fd(epfd)对应的主要数据结构为:
struct eventpoll {
spin_lock_t lock; //对本数据结构的访问
struct mutex mtx; //防止使用时被删除
wait_queue_head_t wq; //sys_epoll_wait()使用的等待队列
wait_queue_head_t poll_wait; //file->poll()使用的等待队列
struct list_head rdllist; //事件满足条件的链表 /*双链表中则存放着将要通过epoll_wait返回给用户的满足条件的事件*/
struct rb_root rbr; //用于管理所有fd的红黑树(树根)/*红黑树的根节点,这颗树中存储着所有添加到epoll中的需要监控的事件*/
struct epitem *ovflist; //将事件到达的fd进行链接起来发送至用户空间
}
struct eventpoll在epoll_create时创建。
这样说来,内核中维护了一棵红黑树,大致的结构如下:

整体而言:
select,poll.epoll区别于联系的更多相关文章
- select,poll,epoll区别
select:忙轮询,一直在轮询,效率跟链接数成反比,资源限制 poll:轮询,不用一直轮询,有事件触发时轮询,资源限制 epoll:有事件触发时直接通知复杂度O(1)
- 哪5种IO模型?什么是select/poll/epoll?同步异步阻塞非阻塞有啥区别?全在这讲明白了!
系统中有哪5种IO模型?什么是 select/poll/epoll?同步异步阻塞非阻塞有啥区别? 本文地址http://yangjianyong.cn/?p=84转载无需经过作者本人授权 先解开第一个 ...
- select.poll,epoll的区别与应用
先讲讲同步I/O的五大模型 阻塞式I/O, 非阻塞式I/O, I/O复用,信号驱动I/O(SIGIO),异步I/O模型 而select/poll/epoll属于I/O复用模型 select函数 该函数 ...
- Python之路-python(Queue队列、进程、Gevent协程、Select\Poll\Epoll异步IO与事件驱动)
一.进程: 1.语法 2.进程间通讯 3.进程池 二.Gevent协程 三.Select\Poll\Epoll异步IO与事件驱动 一.进程: 1.语法 简单的启动线程语法 def run(name): ...
- select,poll,epoll的归纳总结区分
Select.Poll与Epoll比较 以下资料都是来自网上搜集整理.引用源详见文章末尾. 1 Select.Poll与Epoll简介 Select select本质上是通过设置或者检查存放fd标志位 ...
- select, poll, epoll的实现分析
select, poll, epoll都是Linux上的IO多路复用机制.知其然知其所以然,为了更好地理解其底层实现,这几天我阅读了这三个系统调用的源码. 以下源代码摘自Linux4.4.0内核. 预 ...
- 转--select/poll/epoll到底是什么一回事
面试题:说说select/poll/epoll的区别. 这是面试后台开发时的高频面试题,属于网络编程和IO那一块的知识.Android里面的Handler消息处理机制的底层实现就用到了epoll. 为 ...
- IO多路复用select/poll/epoll详解以及在Python中的应用
IO multiplexing(IO多路复用) IO多路复用,有些地方称之为event driven IO(事件驱动IO). 它的好处在于单个进程可以处理多个网络IO请求.select/epoll这两 ...
- python 套接字之select poll epoll
python下的select模块使用 以及epoll与select.poll的区别 先说epoll与select.poll的区别(总结) select, poll, epoll 都是I/O多路复用的具 ...
随机推荐
- gcc posix sjij for MSYS 9.2.1+
mingw gcc 32位 版本 9.2.1 以上的 以后都在 github 上发布 https://github.com/qq2225936589/gcc-i686-posix-sjlj-for-M ...
- 对于MVVM的理解
MVVM 是Model-View-ViewModel的缩写. Model 代表数据模型,也可以在model中定义数据修改和操作的业务逻辑. View 代表UI组件,负责姜黄素局模型转化成UI展现出来. ...
- [转载]Jupyter Notebook 的快捷键
原文:http://blog.csdn.net/lawme/article/details/51034543 Jupyter Notebook 的快捷键 Jupyter Notebook 有两种键盘输 ...
- 【Qt开发】【计算机视觉】OpenCV在Qt-MinGw下的编译库
最近电脑重装系统了,第一件事重装OpenCV.这次直接装最新版,2014-4-25日发布的OpenCV2.4.9版本,下载链接: http://sourceforge.NET/projects/ope ...
- 用grok拆分java日志
1.假设一行日志内容如下: [root@VM_0_92_centos opt]# cat error.log -- ::,[ERROR ajp-nio--exec-](cn.com.al1.compo ...
- MSSQL 索引
INCLUDE索引作用:减少 key lookup所带来的性能开销. 效率主要体现在覆盖查询(建的索引为覆盖索引),在查询时把SELECT显示列放在INCLUDE里作为非索引健列,不用于查询只显示在结 ...
- Js 执行上下文和作用域
1.执行上下文和执行栈 执行上下文就是当前 JavaScript 代码被解析和执行时所在环境的抽象概念, JavaScript 中运行任何的代码都是在执行上下文中运行. 执行上下文的生命周期包括三个阶 ...
- python函数 -- 作用域,异常处理
1.def语句和参数 python定义函数的关键词为def,格式如下: def 函数名([变元],[变元],....) #保存在变元中的值,在函数返回后该变元就会被销毁了. 2.返回 ...
- Java基础(七)
字符串String类 字符串的两个问题 构造方法 字符串池 字符串的内容不可变 比较方法 练习:模拟登陆 练习:模拟登陆(限制重试次数) 替换方法(敏感词过滤) 如果希望将字符串当中指定的部分进行替换 ...
- vue : 无法加载文件 C:\Users\lihongjie\AppData\Roaming\npm\vue.ps1,因为在此系统上禁止运行脚本。有关详细信息,请参阅 htt ps:/go.microsoft.com/fwlink/?LinkID=135170 中的 about_Execution_Policies。 所在位置 行:1 字符: 1 + vue init webpack vue_p
以管理员方式打开powershell 运行命令:set-ExecutionPolicy RemoteSigned 出现: 执行策略更改执行策略可帮助你防止执行不信任的脚本.更改执行策略可能会产生安全风 ...