【小知识】神经网络中的SGD优化器和MSE损失函数
今天来讲下之前发的一篇极其简单的搭建网络的博客里的一些细节
(前文传送门)
之前的那个文章中,用Pytorch搭建优化器的代码如下:
# 设置优化器
optimzer = torch.optim.SGD(myNet.parameters(), lr=0.05)
loss_func = nn.MSELoss()
一、SGD方法
我们要想训练我们的神经网络,就必须要有一种训练方法。就像你要训练你的肌肉,你的健身教练就会给你指定一套训练的计划也可以叫方法,那么SGD就是这样一种训练方法,而训练方法并不只有这一个,因为给你的训练计划可以使很多种,但是我们今天就介绍这一种方法。SGD方法是怎样的一种方法呢?从全称来看:随机梯度下降方法(Stochastic gradient descent),我们可以直观地感受到一个关键的动作——随机
没错,SGD方法就是让我们的神经网络在进行梯度下降的时候,不再死板的选择所有的样本进行梯度计算,而是在样本集中随机选择一个样本进行梯度计算,这一次的梯度下降可以用这样的公式来表示: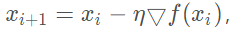 其中iii反向传播传播到了第几层,然后▽f(xi)就是代表对误差求梯度。那么通过这个梯度在乘以学习率η,就可以用来更新我们网络的权值了。
其中iii反向传播传播到了第几层,然后▽f(xi)就是代表对误差求梯度。那么通过这个梯度在乘以学习率η,就可以用来更新我们网络的权值了。
由于每次做的梯度计算只是选取一个样本进行的,所以采用SGD方法的神经网络的学习速度将会特别快,意思也就是能够将损失函数很快的收敛到最小(或者近似最小)。而这里的快并不是说直接沿着最短的路径收敛,因为它并不是对整个样本进行梯度计算,所以SGD并不能直接找到一条最快的路径。就像下面这样:

图中那个歪歪扭扭的线就是采用SGD方法的损失函数收敛的路径,可以说是一段冒险的曲折的探索。而红线就是对所有的样本进行梯度计算的收敛路径。
看到这里你可能会问,那为什么采用SGD的方法训练的神经网络会比直接对所有样本进行梯度下降的速度快呢?图中明显是曲折的探索路径更长。但是事实确实是如此的,因为SGD求梯度的速度很快,每次只需要对一个样本求梯度即可,当你的样本集特别特别大的时候,SGD的优势将会非常的明显。
但是也存在着一定弊端,当然也很好理解,因为选取的样本少,所以可能一不小心我们训练的神经网络的损失函数就陷入了局部的最优解,就像下面的这个图: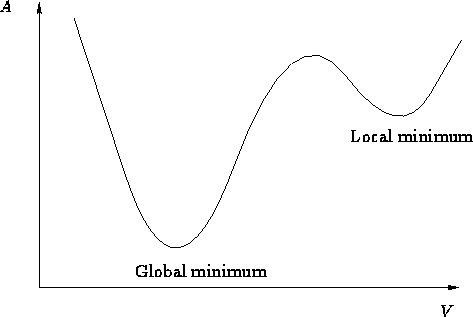
你可以把这张图当做那个曲折探索的一个小的部分,Local minimum就是局部的最小值,其实并不是真正的最小值,所以如果陷入其中,这段曲折的探索可能就会提前宣告失败,我们网络的性能也有可能会因此变得很差。当然,如果你把这个看成曲折探索的一小部分,那么Global minimum也可能只是这一小部分的局部最小值,而我们想得到的是整段曲折探索的最小值,也就是曲折探索的终点。
如何解决这样的问题呢?其实,你完全可以采用一种其他的学习方法,你的方法可能会对于你所解决的具体问题来说性能更好,在之后的文章里我们再来学习一些其他的方法。不过需要注意的是,SGD方法现在并没有被许多人抛弃,因为大量的实验研究已经证明,它在解决某些问题上的“性价比”还是挺高的。
二、MSE损失函数
用了挺大的篇幅讲完了SGD方法,接着我们来放松下,了解一下什么是MSE。 在上面讲到的SGD方法的内容中,我们已经提到了损失函数这一概念,你可以简单的把损失函数理解成误差,就是你网络的实际输出和你期望的输出之间的误差。你给你的网络一个猫的照片,他输出了个狗,那么这个误差就是:狗-猫,当然这么简单地计算误差,是不会达到好的学习效果的,所以一般我们都会有一个函数来计算误差,比如:f(狗-猫)。
MSE就是这样一个函数,他的表达式为: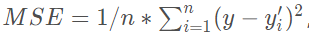
其中n代表样本的数量,y代表你期望的输出,而y′是指网络实际的输出,这样我们通过MSE损失函数求梯度(求导)就可以进行梯度下降对网络进行训练了。
它是如何进行反向传播的呢?这就超出了本文叙述的范围,我将会在后面的文章里进行详细的陈述。
当然和学习方法一样,损失函数也不只这一个,通常来讲,在解决回归问题时,我们大多采用MSE,而在解决分类问题时,交叉熵函数就闪亮登场了。所以损失函数的选择,也是决定你网络性能好坏的一个重要因素。
【小知识】神经网络中的SGD优化器和MSE损失函数的更多相关文章
- keras channels_last、preprocess_input、全连接层Dense、SGD优化器、模型及编译
channels_last 和 channels_first keras中 channels_last 和 channels_first 用来设定数据的维度顺序(image_data_format). ...
- MVC中学到的小知识(MVC中的跳转,传参)
1.mvc中视图中的href="XXX",这个XXX是控制器地址,不是另一个视图.(这里的href语句只能转向控制器,不能直接转向视图),如果要实现转向视图,可以先转到控制器,然后 ...
- Tensorflow 2.0 深度学习实战 —— 详细介绍损失函数、优化器、激活函数、多层感知机的实现原理
前言 AI 人工智能包含了机器学习与深度学习,在前几篇文章曾经介绍过机器学习的基础知识,包括了监督学习和无监督学习,有兴趣的朋友可以阅读< Python 机器学习实战 >.而深度学习开始只 ...
- Tensorflow-各种优化器总结与比较
优化器总结 机器学习中,有很多优化方法来试图寻找模型的最优解.比如神经网络中可以采取最基本的梯度下降法. 梯度下降法(Gradient Descent) 梯度下降法是最基本的一类优化器,目前主要分为三 ...
- [源码解析] PyTorch分布式优化器(1)----基石篇
[源码解析] PyTorch分布式优化器(1)----基石篇 目录 [源码解析] PyTorch分布式优化器(1)----基石篇 0x00 摘要 0x01 从问题出发 1.1 示例 1.2 问题点 0 ...
- [源码解析] PyTorch分布式优化器(3)---- 模型并行
[源码解析] PyTorch分布式优化器(3)---- 模型并行 目录 [源码解析] PyTorch分布式优化器(3)---- 模型并行 0x00 摘要 0x01 前文回顾 0x02 单机模型 2.1 ...
- Pytorch torch.optim优化器个性化使用
一.简化前馈网络LeNet 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 im ...
- (五) Keras Adam优化器以及CNN应用于手写识别
视频学习来源 https://www.bilibili.com/video/av40787141?from=search&seid=17003307842787199553 笔记 Adam,常 ...
- MySQL · 特性分析 · 优化器 MRR & BKA【转】
MySQL · 特性分析 · 优化器 MRR & BKA 上一篇文章咱们对 ICP 进行了一次全面的分析,本篇文章小编继续为大家分析优化器的另外两个选项: MRR & batched_ ...
随机推荐
- Rust <4>:所有权、借用、切片
tips:栈内存分配大小固定,访问时不需要额外的寻址动作,故其速度快于堆内存分配与访问. rust 所有权规则: 每一个值在任意时刻都有且只有唯一一个所有者 当所有者离开作用域时,这个值将被丢弃 所有 ...
- 现在就去100offer 参加互联网人才拍卖! 现在登录现在注册 为什么整个互联网行业都缺前端工程师?
现在,几乎整个互联网行业都缺前端工程师,不仅在刚起步的创业公司,上市公司乃至巨头,这个问题也一样存在.没错,优秀的前端工程师简直比大熊猫还稀少. 每天,100offer的HR群都有人在吐槽招不到前端工 ...
- Python中过滤HTML标签的函数
#用正则简单过滤html的<>标签 import re str = "<img /><a>srcd</a>hello</br>&l ...
- Spring整合Hibernate报错:annotatedClasses is not writable or has an invalid setter method
Spring 整合Hibernate时报错: org.springframework.beans.factory.BeanCreationException: Error creating bean ...
- 2018-8-10-WPF-DrawingVisual
title author date CreateTime categories WPF DrawingVisual lindexi 2018-08-10 19:16:53 +0800 2018-2-1 ...
- Codeforces 19E&BZOJ 4424 Fairy(好题)
日常自闭(菜鸡qaq).不过开心的是看了题解之后1A了.感觉这道题非常好,必须记录一下,一方面理清下思路,一方面感觉自己还没有完全领会到这道题的精髓先记下来以后回想. 题意:给定 n 个点,m 条边的 ...
- 配置文件--spring cloud Config
配置中心--Spring cloud Config 通过本次学习,我们应该掌握: Config Server 读取配置文 Config Server 从远程 Git 仓库读取配置文 搭建芮可用 Con ...
- Centos 更改语言设置为中文
说明 自己装系统时一般都可以自定义选择系统语言.可是云端服务器一般都是安装好的镜像,默认系统语言为英文,对于初学者可能还会有搞不懂的计算机词汇.这里简单说一下centos7怎么修改系统语言为中文. 修 ...
- CentOS7.6 部署asp.net core2.2 应用
1.安装.net Core SDK 在安装.NET之前,您需要注册Microsoft密钥,注册产品存储库并安装所需的依赖项.这只需要每台机器完成一次. 打开终端并运行以下命令: sudo rpm -U ...
- vue-cli 3.0版本,配置代理Proxy,不同环境不同target(生产环境,uat环境和本地环境的配置)
1.在项目的的根目录下新建vue.config.js 2.新建一个config包,里面存放不同的环境文件,里面包含:pro.env.js(生产环境配置),uat.env.js(测试环境配置),dev. ...