LRU算法 缓存淘汰策略
四种实现方式
LRU
1.1. 原理
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
1.2. 实现
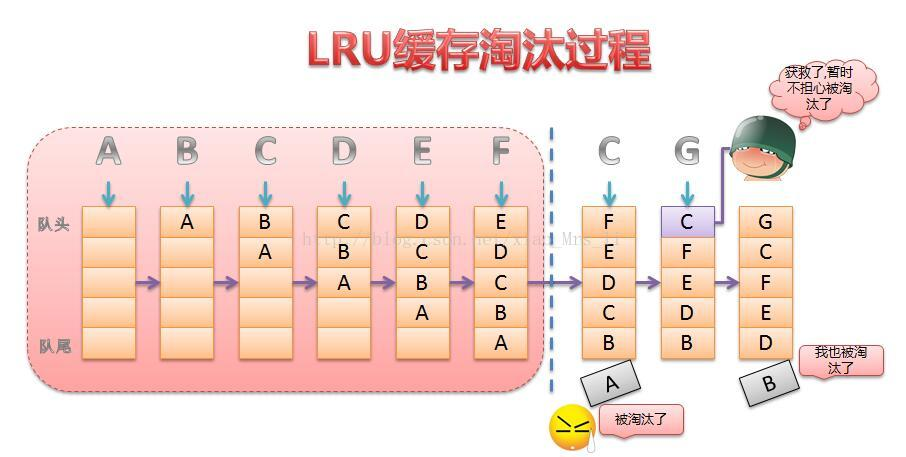
最常见的实现是使用一个链表保存缓存数据,详细算法实现如下:
1. 新数据插入到链表头部;
2. 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
3. 当链表满的时候,将链表尾部的数据丢弃。
1.3. 分析
【命中率】
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
【复杂度】
实现简单。
【代价】
命中时需要遍历链表,找到命中的数据块索引,然后需要将数据移到头部。
LRU-K
2.1. 原理
LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。LRU-K的主要目的是为了解决LRU算法“缓存污染”的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。
2.2. 实现
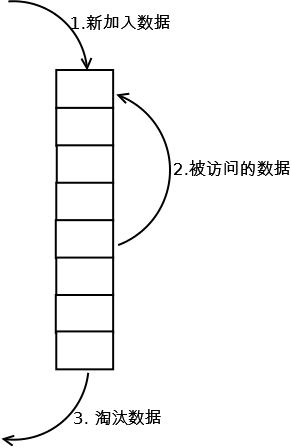
相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。只有当数据的访问次数达到K次的时候,才将数据放入缓存。当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。详细实现如下:
1. 数据第一次被访问,加入到访问历史列表;
2. 如果数据在访问历史列表里后没有达到K次访问,则按照一定规则(FIFO,LRU)淘汰;
3. 当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;
4. 缓存数据队列中被再次访问后,重新排序;
5. 需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
LRU-K具有LRU的优点,同时能够避免LRU的缺点,实际应用中LRU-2是综合各种因素后最优的选择,LRU-3或者更大的K值命中率会高,但适应性差,需要大量的数据访问才能将历史访问记录清除掉。
2.3. 分析
【命中率】
LRU-K降低了“缓存污染”带来的问题,命中率比LRU要高。
【复杂度】
LRU-K队列是一个优先级队列,算法复杂度和代价比较高。
【代价】
由于LRU-K还需要记录那些被访问过、但还没有放入缓存的对象,因此内存消耗会比LRU要多;当数据量很大的时候,内存消耗会比较可观。
LRU-K需要基于时间进行排序(可以需要淘汰时再排序,也可以即时排序),CPU消耗比LRU要高。
Two queues(2Q)
3.1. 原理
Two queues(以下使用2Q代替)算法类似于LRU-2,不同点在于2Q将LRU-2算法中的访问历史队列(注意这不是缓存数据的)改为一个FIFO缓存队列,即:2Q算法有两个缓存队列,一个是FIFO队列,一个是LRU队列。
3.2. 实现
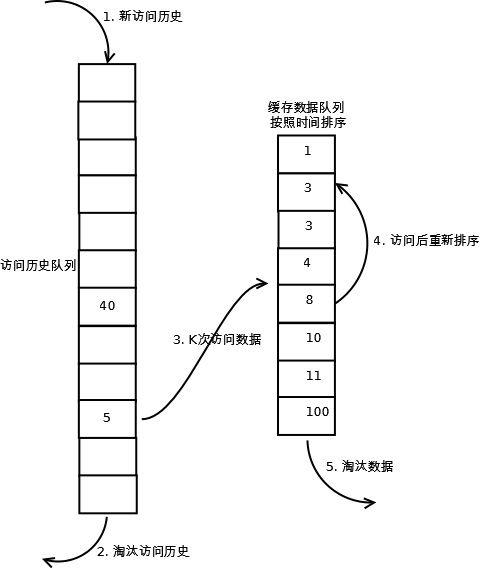
当数据第一次访问时,2Q算法将数据缓存在FIFO队列里面,当数据第二次被访问时,则将数据从FIFO队列移到LRU队列里面,两个队列各自按照自己的方法淘汰数据。详细实现如下:
1. 新访问的数据插入到FIFO队列;
2. 如果数据在FIFO队列中一直没有被再次访问,则最终按照FIFO规则淘汰;
3. 如果数据在FIFO队列中被再次访问,则将数据移到LRU队列头部;
4. 如果数据在LRU队列再次被访问,则将数据移到LRU队列头部;
5. LRU队列淘汰末尾的数据。
注:上图中FIFO队列比LRU队列短,但并不代表这是算法要求,实际应用中两者比例没有硬性规定。
3.3. 分析
【命中率】
2Q算法的命中率要高于LRU。
【复杂度】
需要两个队列,但两个队列本身都比较简单。
【代价】
FIFO和LRU的代价之和。
2Q算法和LRU-2算法命中率类似,内存消耗也比较接近,但对于最后缓存的数据来说,2Q会减少一次从原始存储读取数据或者计算数据的操作。
Multi Queue(MQ)
4.1. 原理
MQ算法根据访问频率将数据划分为多个队列,不同的队列具有不同的访问优先级,其核心思想是:优先缓存访问次数多的数据。
4.2. 实现
MQ算法将缓存划分为多个LRU队列,每个队列对应不同的访问优先级。访问优先级是根据访问次数计算出来的,例如
详细的算法结构图如下,Q0,Q1....Qk代表不同的优先级队列,Q-history代表从缓存中淘汰数据,但记录了数据的索引和引用次数的队列:
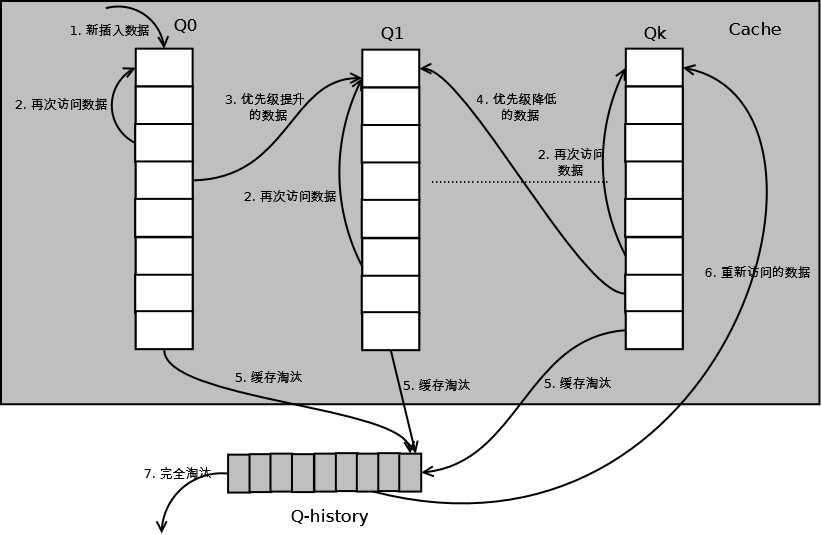
如上图,算法详细描述如下:
1. 新插入的数据放入Q0;
2. 每个队列按照LRU管理数据;
3. 当数据的访问次数达到一定次数,需要提升优先级时,将数据从当前队列删除,加入到高一级队列的头部;
4. 为了防止高优先级数据永远不被淘汰,当数据在指定的时间里访问没有被访问时,需要降低优先级,将数据从当前队列删除,加入到低一级的队列头部;
5. 需要淘汰数据时,从最低一级队列开始按照LRU淘汰;每个队列淘汰数据时,将数据从缓存中删除,将数据索引加入Q-history头部;
6. 如果数据在Q-history中被重新访问,则重新计算其优先级,移到目标队列的头部;
7. Q-history按照LRU淘汰数据的索引。
4.3. 分析
【命中率】
MQ降低了“缓存污染”带来的问题,命中率比LRU要高。
【复杂度】
MQ需要维护多个队列,且需要维护每个数据的访问时间,复杂度比LRU高。
【代价】
MQ需要记录每个数据的访问时间,需要定时扫描所有队列,代价比LRU要高。
注:虽然MQ的队列看起来数量比较多,但由于所有队列之和受限于缓存容量的大小,因此这里多个队列长度之和和一个LRU队列是一样的,因此队列扫描性能也相近。
LRU类算法对比
由于不同的访问模型导致命中率变化较大,此处对比仅基于理论定性分析,不做定量分析。
|
对比点 |
对比 |
|
命中率 |
LRU-2 > MQ(2) > 2Q > LRU |
|
复杂度 |
LRU-2 > MQ(2) > 2Q > LRU |
|
代价 |
LRU-2 > MQ(2) > 2Q > LRU |
实际应用中需要根据业务的需求和对数据的访问情况进行选择,并不是命中率越高越好。例如:虽然LRU看起来命中率会低一些,且存在”缓存污染“的问题,但由于其简单和代价小,实际应用中反而应用更多。
LRU缓存实现(Java)
LRU算法 缓存淘汰策略的更多相关文章
- Go -- LRU算法(缓存淘汰算法)(转)
1. LRU1.1. 原理 LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”. ...
- LRU算法---缓存淘汰算法
计算机中的缓存大小是有限的,如果对所有数据都缓存,肯定是不现实的,所以需要有一种淘汰机制,用于将一些暂时没有用的数据给淘汰掉,以换入新鲜的数据进来,这样可以提高缓存的命中率,减少磁盘访问的次数. LR ...
- 动手实现 LRU 算法,以及 Caffeine 和 Redis 中的缓存淘汰策略
我是风筝,公众号「古时的风筝」. 文章会收录在 JavaNewBee 中,更有 Java 后端知识图谱,从小白到大牛要走的路都在里面. 那天我在 LeetCode 上刷到一道 LRU 缓存机制的问题, ...
- redis数据结构、持久化、缓存淘汰策略
Redis 单线程高性能,它所有的数据都在内存中,所有的运算都是内存级别的运算,而且单线程避免了多线程的切换性能损耗问题.redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,依次放 ...
- Redis 键的过期删除策略及缓存淘汰策略
前言 Redis缓存淘汰策略与Redis键的过期删除策略并不完全相同,前者是在Redis内存使用超过一定值的时候(一般这个值可以配置)使用的淘汰策略:而后者是通过定期删除+惰性删除两者结合的方式进行内 ...
- mybatis PageHelper分页插件 和 LRU算法缓存读取数据
分页: PageHelper的优点是,分页和Mapper.xml完全解耦.实现方式是以插件的形式,对Mybatis执行的流程进行了强化,添加了总数count和limit查询.属于物理分页. 一.首先注 ...
- 借助LinkedHashMap实现基于LRU算法缓存
一.LRU算法介绍 LRU(Least Recently Used)最近最少使用算法,是用在操作系统中的页面置换算法,因为内存空间是有限的,不可能把所有东西都放进来,所以就必须要有所取舍,我们应该把什 ...
- 缓存淘汰策略之LRU
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”. 1. 新数据插入到链表头部: ...
- Redis数据缓存淘汰策略【FIFO 、LRU、LFU】
FIFO.LFU.LRU FIFO:先进先出算法 FIFO(First in First out),先进先出.在FIFO Cache设计中,核心原则就是:如果一个数据最先进入缓存中,则应该最早淘汰掉. ...
随机推荐
- CDN的那些细枝末节
起源: 原本打算系统看看关于axios的介绍,无意中就看见一句"Using cdn",于是百度一下,"cdn"是什么? 名词解释:CDN CDN的全称是Cont ...
- opencv3——ANN算法的使用
最近刚转用opencv3,使用ANN算法时遇到了一些问题,记录下来. 训练神经网络的代码如下: //创建ANN Ptr<ANN_MLP> bp = ANN_MLP::create(); 设 ...
- php pear包打包方法
一)首先下载工具onion 浏览器打开,服务器上wget测试无法正常下载 地址:https://raw.github.com/c9s/Onion/master/onion 二)在临时目录下,建立相关目 ...
- epoll实现机制分析
本文只介绍epoll的主要流程而不是分析源代码,如果需要了解更多的细节可以自己翻阅相关的内核源代码. 相关内核代码: fs/eventpoll.c 判断一个tcp套接字上是否有激活事件:net/ipv ...
- redis基本结构
redis数据结构string(字符串)1->12->23->3 list(列表)key->(1->2->3->4->5) hash(散列)1-> ...
- Apache Server Status详解
Apache的日志如果靠分析日志或者查看服务器进程来监视Apache运行状态的话,比较繁冗.不过在Apache 1.3.2及以后的版本中就自带一个查看Apache状态的功能模块server-statu ...
- CMOS构成的常见电路
CMOS门电路 以MOS(Metal-Oxide Semiconductor)管作为开关元件的门电路称为MOS门电路.由于MOS型集成门电路具有制造工艺简单.集成度高.功耗小以及抗干扰能力强等优点,因 ...
- 通过Intent Flags ,从桌面返回到App最后Activity
extends:http://bbs.csdn.net/topics/350269396,http://blog.csdn.net/moreevan/article/details/6788048 最 ...
- Office2010安装需要MSXML版本6.10.1129.0的方法
今天给朋友装Office2010,由于朋友之前使用的是绿化版的0ffice2007,所以卸载后安装Office遇到了若要安装Office2010,需要在计算机上安装MSXML版本6.10.1129.0 ...
- Css控制网页变灰
兼容IE chrome Firefox..... html{ filter:grayscale(%); -moz-filter:grayscale(%); -o-filter:grayscale(%) ...