Scrapyd发布爬虫的工具
Scrapyd
Scrapyd是部署和运行Scrapy.spider的应用程序。它使您能够使用JSON API部署(上传)您的项目并控制其spider。
Scrapyd-client
Scrapyd-client是一个专门用来发布scrapy爬虫的工具,安装该程序之后会自动在python目录\scripts安装一个名为scrapyd-deploy的工具
(其实打开该文件,可以发现它是一个类似setup.py的python脚本,所以可以通过python scrapyd-deploy的方式运行)
下载安装
pip install scrapyd-client
pip install enum-compat
pip install w3lib
pip install scrapyd
安装完成后检查
C:\Program Files\Python36\Scripts>dir sc*
驱动器 C 中的卷是 BOOTCAMP
卷的序列号是 D471-4F4D C:\Program Files\Python36\Scripts 的目录 2018/05/07 21:20 98,158 scrapy.exe
2018/05/25 21:17 9,901 scrapyd-deploy
2018/05/25 20:37 98,165 scrapyd.exe
4 个文件 216,128 字节
0 个目录 39,937,785,856 可用字节
scrapyd-deploy内容
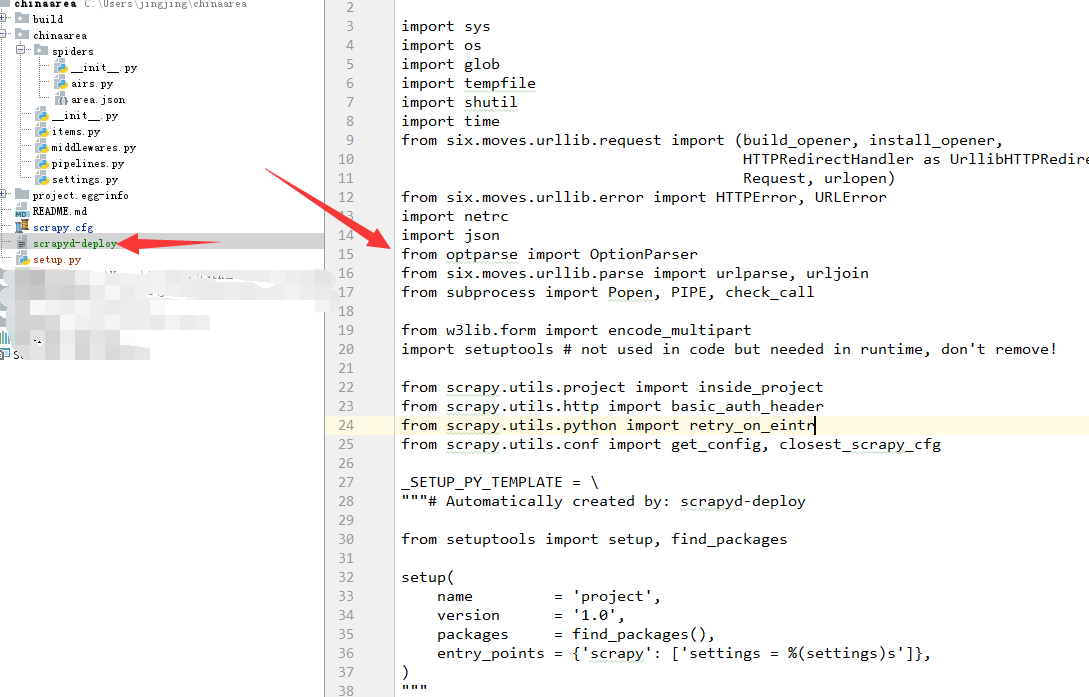
运行方法
1.运行scrapyd
C:\>scrapyd
2018-05-25T20:38:52+0800 [-] Loading c:\program files\python36\lib\site-packages
\scrapyd\txapp.py...
2018-05-25T20:38:54+0800 [-] Scrapyd web console available at http://127.0.0.1:6
800/
2018-05-25T20:38:54+0800 [-] Loaded.
2018-05-25T20:38:54+0800 [twisted.application.app.AppLogger#info] twistd 18.4.0
(c:\program files\python36\python.exe 3.6.1) starting up.
2018-05-25T20:38:54+0800 [twisted.application.app.AppLogger#info] reactor class:
twisted.internet.selectreactor.SelectReactor.
2018-05-25T20:38:54+0800 [-] Site starting on 6800
2018-05-25T20:38:54+0800 [twisted.web.server.Site#info] Starting factory <twiste
d.web.server.Site object at 0x0000000004BB8DA0>
2018-05-25T20:38:54+0800 [Launcher] Scrapyd 1.2.0 started: max_proc=32, runner='
scrapyd.runner'
2.拷贝scrapyd-deploy工具到爬虫目录下
C:\chinaarea 的目录 2018/05/25 21:19 <DIR> .
2018/05/25 21:19 <DIR> ..
2018/05/24 21:23 <DIR> .idea
2018/05/25 21:19 <DIR> build
2018/05/25 21:16 <DIR> chinaarea
2018/05/25 21:19 <DIR> project.egg-info
2018/05/23 20:38 74 README.md
2018/05/25 21:02 264 scrapy.cfg
2018/05/25 20:37 9,904 scrapyd-deploy
2018/05/25 21:19 266 setup.py
4 个文件 10,508 字节
6 个目录 39,973,642,240 可用字节
3.修改爬虫的scapy.cfg文件
首先去掉url前的注释符号,这里url就是你的scrapyd服务器的网址。
其次,deploy:100表示把爬虫发布到名为100的爬虫服务器上。
这个名叫target名字可以随意起,一般情况用在需要同时发布爬虫到多个目标服务器时,可以通过指定名字的方式发布到指定服务器。
其次,default=ccpmess.settings 中 ccpmess也是可以改的,貌似没啥用,默认还是用工程名字。
关键是scrapyd-deploy 所在目录,具体其实可以读下scrapyd-deploy 的代码。
# Automatically created by: scrapy startproject
#
# For more information about the [deploy] section see:
# https://scrapyd.readthedocs.io/en/latest/deploy.html [settings]
default = chinaarea.settings [deploy:]
url = http://localhost:6800/
project = chinaarea
4.查看配置
检查scrapy配置是否正确。
$python scrapyd-deploy -l
100 http://localhost:6800/
5.发布爬虫
scrapyd-deploy <target> -p <project> --version <version>
target就是前面配置文件里deploy后面的的target名字。
project 可以随意定义,跟爬虫的工程名字无关。
version自定义版本号,不写的话默认为当前时间戳。
注意,爬虫目录下不要放无关的py文件,放无关的py文件会导致发布失败,但是当爬虫发布成功后,会在当前目录生成一个setup.py文件,可以删除掉。
C:\chinaarea>python scrapyd-deploy 100 -p chinaarea --version ver20180525
Packing version ver20180525
Deploying to project "chinaarea" in http://localhost:6800/addversion.json
Server response (200):
{"node_name": "jingjing-PC", "status": "ok", "project": "chinaarea", "version":
"ver20180525", "spiders": 1}
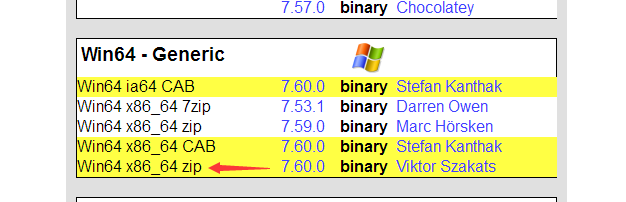
6.下载安装curl
下载地址:https://curl.haxx.se/download.html
根据电脑系统下载适合的版本
下载完成后会看到curl.exe文件
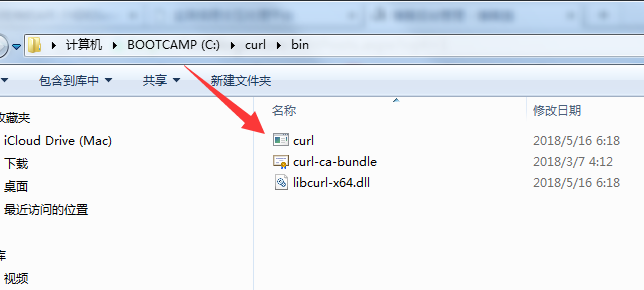
设置环境变量
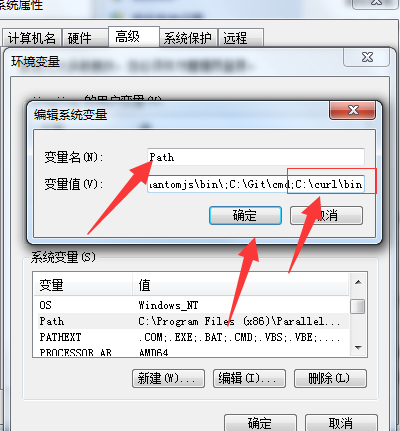
测试配置
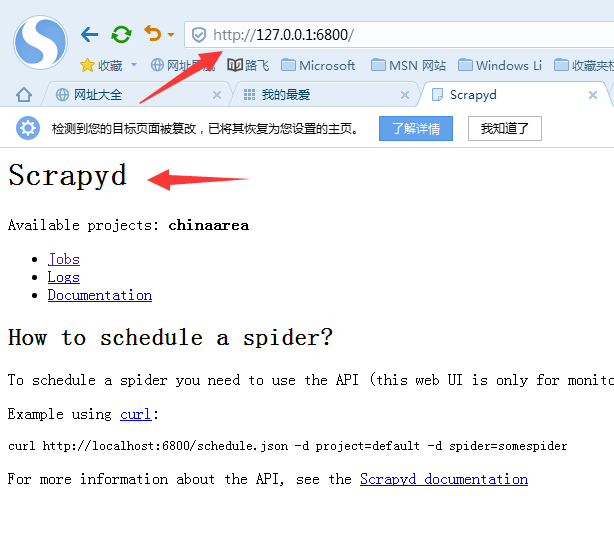
C:\curl\bin>curl localhost:6800 <html>
<head><title>Scrapyd</title></head>
<body>
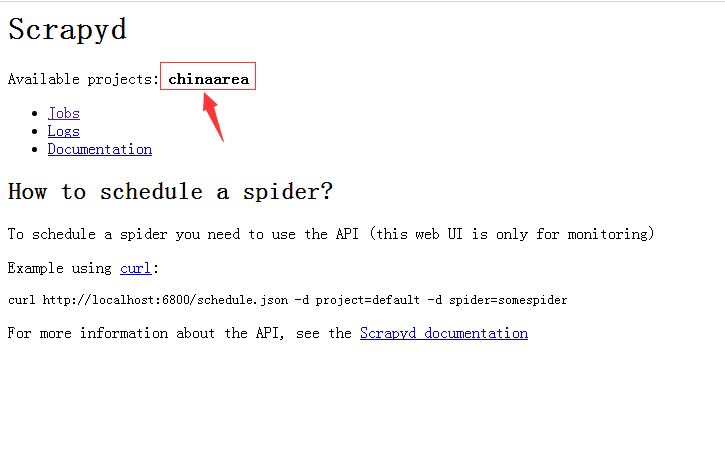
<h1>Scrapyd</h1>
<p>Available projects: <b>chinaarea</b></p>
<ul>
<li><a href="/jobs">Jobs</a></li> <li><a href="/logs/">Logs</a></li>
7.启动scrapyd服务器上myproject工程下的myspider爬虫
C:\curl\bin>curl http://localhost:6800/schedule.json -d project=chinaarea -d spider=airs
{"node_name": "jingjing-PC", "status": "ok", "jobid": "5895b858603611e8b3e160f81
dad89ef"}
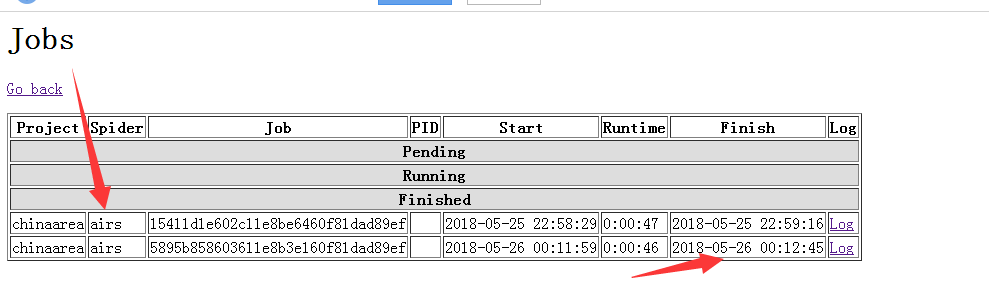
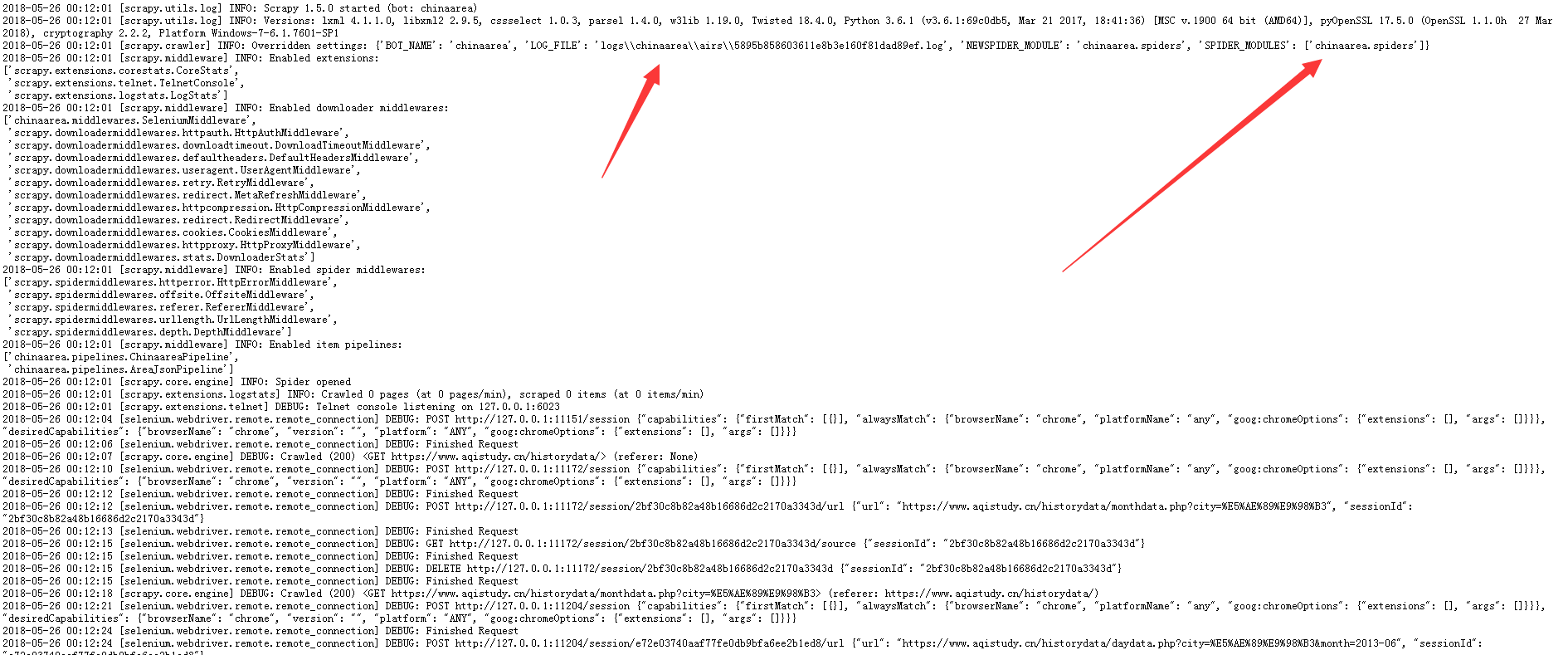
8.删除scrapyd服务器上myproject工程
C:\curl\bin>curl http://127.0.0.1:6800/delproject.json -d project=chinaarea
{"node_name": "jingjing-PC", "status": "ok"}
9.其他操作API
# -*- coding: utf-8 -*- import requests
import json baseUrl ='http://127.0.0.1:6800/'
daemUrl ='http://127.0.0.1:6800/daemonstatus.json'
listproUrl ='http://127.0.0.1:6800/listprojects.json'
listspdUrl ='http://127.0.0.1:6800/listspiders.json?project=%s'
listspdvUrl= 'http://127.0.0.1:6800/listversions.json?project=%s'
listjobUrl ='http://127.0.0.1:6800/listjobs.json?project=%s'
delspdvUrl= 'http://127.0.0.1:6800/delversion.json' #http://127.0.0.1:6800/daemonstatus.json
#查看scrapyd服务器运行状态
r= requests.get(daemUrl)
print '1.stats :\n %s \n\n' %r.text #http://127.0.0.1:6800/listprojects.json
#获取scrapyd服务器上已经发布的工程列表
r= requests.get(listproUrl)
print '1.1.listprojects : [%s]\n\n' %r.text
if len(json.loads(r.text)["projects"])>0 :
project = json.loads(r.text)["projects"][0] #http://127.0.0.1:6800/listspiders.json?project=myproject
#获取scrapyd服务器上名为myproject的工程下的爬虫清单
listspd=listspd % project
r= requests.get(listspdUrl)
print '2.listspiders : [%s]\n\n' %r.text
if json.loads(r.text).has_key("spiders")>0 :
spider =json.loads(r.text)["spiders"][0] #http://127.0.0.1:6800/listversions.json?project=myproject
##获取scrapyd服务器上名为myproject的工程下的各爬虫的版本
listspdvUrl=listspdvUrl % project
r = requests.get(listspdvUrl)
print '3.listversions : [%s]\n\n' %rtext
if len(json.loads(r.text)["versions"])>0 :
version = json.loads(r.text)["versions"][0] #http://127.0.0.1:6800/listjobs.json?project=myproject
#获取scrapyd服务器上的所有任务清单,包括已结束,正在运行的,准备启动的。
listjobUrl=listjobUrl % proName
r=requests.get(listjobUrl)
print '4.listjobs : [%s]\n\n' %r.text #schedule.json
#http://127.0.0.1:6800/schedule.json -d project=myproject -d spider=myspider
#启动scrapyd服务器上myproject工程下的myspider爬虫,使myspider立刻开始运行,注意必须以post方式
schUrl = baseurl + 'schedule.json'
dictdata ={ "project":project,"spider":spider}
r= reqeusts.post(schUrl, json= dictdata)
print '5.1.delversion : [%s]\n\n' %r.text #http://127.0.0.1:6800/delversion.json -d project=myproject -d version=r99'
#删除scrapyd服务器上myproject的工程下的版本名为version的爬虫,注意必须以post方式
delverUrl = baseurl + 'delversion.json'
dictdata={"project":project ,"version": version }
r= reqeusts.post(delverUrl, json= dictdata)
print '6.1.delversion : [%s]\n\n' %r.text #http://127.0.0.1:6800/delproject.json -d project=myproject
#删除scrapyd服务器上myproject工程,注意该命令会自动删除该工程下所有的spider,注意必须以post方式
delProUrl = baseurl + 'delproject.json'
dictdata={"project":project }
r= reqeusts.post(delverUrl, json= dictdata)
print '6.2.delproject : [%s]\n\n' %r.text
10.总结
1、获取状态
http://127.0.0.1:6800/daemonstatus.json
2、获取项目列表
http://127.0.0.1:6800/listprojects.json
3、获取项目下已发布的爬虫列表
http://127.0.0.1:6800/listspiders.json?project=myproject
4、获取项目下已发布的爬虫版本列表
http://127.0.0.1:6800/listversions.json?project=myproject
5、获取爬虫运行状态
http://127.0.0.1:6800/listjobs.json?project=myproject
6、启动服务器上某一爬虫(必须是已发布到服务器的爬虫)
http://localhost:6800/schedule.json (post方式,data={"project":myproject,"spider":myspider})
7、删除某一版本爬虫
http://127.0.0.1:6800/delversion.json (post方式,data={"project":myproject,"version":myversion})
8、删除某一工程,包括该工程下的各版本爬虫
http://127.0.0.1:6800/delproject.json(post方式,data={"project":myproject})
到此,基于scrapyd的爬虫发布教程就写完了。
可能有人会说,我直接用scrapy cwal 命令也可以执行爬虫,个人理解用scrapyd服务器管理爬虫,至少有以下几个优势:
1、可以避免爬虫源码被看到。
2、有版本控制。
3、可以远程启动、停止、删除,正是因为这一点,所以scrapyd也是分布式爬虫的解决方案之一
Scrapyd发布爬虫的工具的更多相关文章
- 爬虫部署 --- scrapyd部署爬虫 + Gerapy 管理界面 scrapyd+gerapy部署流程
---------scrapyd部署爬虫---------------1.编写爬虫2.部署环境pip install scrapyd pip install scrapyd-client 启动scra ...
- 简单的抓取淘宝关键字信息、图片的Python爬虫|Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇)
Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇) 淘宝改字段,Bugfix,查看https://github.com/hunterhug/taobaoscrapy.git 由于Gith ...
- 发布《Linux工具快速教程》
发布<Linux工具快速教程> 阶段性的完成了这本书开源书籍,发布出来给有需要的朋友,同时也欢迎更多的朋友加入进来,完善这本书: 本书Github地址:https://github.com ...
- Scrapyd部署爬虫
Scrapyd部署爬虫 准备工作 安装scrapyd: pip install scrapyd 安装scrapyd-client : pip install scrapyd-client 安装curl ...
- 火眼发布Windows攻击工具集
导读 渗透测试员的喜讯:安全公司火眼发布Windows攻击工具集--足足包含140个程序. Kali Linux 已成为攻击型安全专家的标配工具,但对需要原生Windows功能的渗透测试员来说,维护良 ...
- Python 爬虫的工具列表 附Github代码下载链接
Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门 https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6E ...
- Python 爬虫的工具列表大全
Python 爬虫的工具列表大全 这个列表包含与网页抓取和数据处理的Python库.网络 通用 urllib -网络库(stdlib). requests -网络库. grab – 网络库(基于pyc ...
- ios 程序发布使用xcode工具Application Loader 正在通过ITUNES STORE进行鉴定错误
ios 程序发布使用xcode工具Application Loader 正在通过ITUNES STORE进行鉴定错误 一:此错误会导致上传程序,一直停留在验证阶段,而没有一点上传进度:结果会苦等半天, ...
- Python 爬虫的工具列表
Python 爬虫的工具列表 这个列表包含与网页抓取和数据处理的Python库 网络 通用 urllib -网络库(stdlib). requests -网络库. grab – 网络库(基于pycur ...
随机推荐
- APP测试重点罗列
1.安装和卸载 应用是否可以在IOS不同系统版本或android不同系统版本上安装(有的系统版本过低,应用不能适配) 软件安装后是否可以正常运行,安装后的文件夹及文件是否可以写到指定的目录里. 安装过 ...
- vue 移动端添加 时间日期选择器
效果: index.vue <template> <div class="user-wrap" style="padding-bottom: 0;tex ...
- 端到端文本识别CRNN论文解读
CRNN 论文: An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Applica ...
- TensorBoard 实践 1
从新查看图的时候,删除旧的logs/下面的文件 tf.scalar_summary('loss',self.loss) AttributeError: 'module' object has no a ...
- for (Sms sms : smsLists){}
for (Sms sms : smsLists){ } //类似下面的for循环 :Smslists[i]!=NULL;i++) { Sms sms=Smslists[i]; } /*其实就是把Sms ...
- URAL - 1397:Points Game (博弈,贪心)
Two students are playing the following game. There are 2· n points on the plane, given with their co ...
- 原生JS 的cookie和jq的cookie,
COOKIE基础及应用:1.什么是COOKIE==>页面用来保存信息,比如:自动登录,记住用户名2.COOKIE的特性: --同一个网站中,所有的页面共享同一套cookie --数量,大小有 ...
- UVA 156:Ananagrams (vector+map+sort)
题意:一大堆单词中间有空格隔开,以'#'结束输出,问只出现一次的的单词有哪些(如果两个具有相同的长度,相同的字母也算是相同的,不区分大小写,如:noel和lone属于一个单词出现两次).最后按照字典序 ...
- CTF-练习平台-Misc之 细心的大象
十五.细心的大象 打开图片属性 发现备注里有短信息,看着也不像flag,仔细观察里面只有只有大小写字母和数字应该是base64编码,解密后得到:MSDS456ASD123zz 好像也不是flag,题目 ...
- M端计算rem方法
(function(){var a=document.documentElement.clientWidth||document.body.clientWidth;if(a>460){a=460 ...