java转pdf(html转为pdf),解决中文乱码,标签不规范等问题
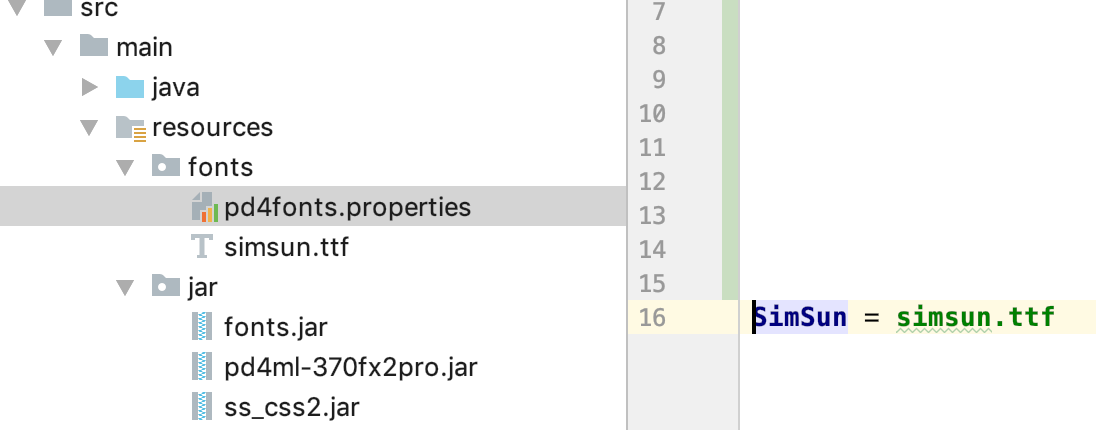
第一步,下载jar包以及建对应的文件夹。注意pd4ml的jar要选择pro版本。然后建一个pd4fonts.properties
里面对应的字体。
SimSun = simsun.ttf 前面为变量名,后面要对应你下载好的字体。网上都有各种字体下载。相应步骤做完了,做完后的文件夹如图格式都有了!
注意要引入图片中对应的jar下面的三个jar包到项目中去。
以下为从文件读取到数据再作导出功能。
import java.awt.Insets;
import java.io.BufferedInputStream;
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.StringReader;
import java.net.MalformedURLException;
import java.security.InvalidParameterException; import org.zefer.pd4ml.PD4Constants;
import org.zefer.pd4ml.PD4ML; public class Test {
protected int topValue = 10;
protected int leftValue = 20;
protected int rightValue = 10;
protected int bottomValue = 10;
protected int userSpaceWidth = 1300; /**
* @param args
*/
public static void main(String[] args) {
try {
Test jt = new Test();
//此处填写你的html文件
String html = readFile("/Users/wangchen/Desktop/370fx2.html", "UTF-8");
//此处填写你下载的地方
jt.doConversion2(html, "/Users/wangchen/Desktop/370fx2.pdf");
} catch (Exception e) {
e.printStackTrace();
}
} public void doConversion2(String htmlDocument, String outputPath)
throws InvalidParameterException, MalformedURLException,
IOException {
PD4ML pd4ml = new PD4ML();
pd4ml.enableDebugInfo();
pd4ml.setHtmlWidth(userSpaceWidth);
pd4ml.setPageSize(pd4ml.changePageOrientation(PD4Constants.A4));
pd4ml.setPageInsetsMM(new Insets(topValue, leftValue, bottomValue,
rightValue));
//此处的classPath注意一定要获取到你放fonts的文件夹。他需要获取到你下载的字体
String classPath = Test.class.getResource("/")+"fonts";
pd4ml.useTTF(classPath, true);
pd4ml.setDefaultTTFs("SimSun", "SimSun", "SimSun");
ByteArrayOutputStream baos = new ByteArrayOutputStream();
pd4ml.render(new StringReader(htmlDocument), baos);
baos.close();
File output = new File(outputPath);
java.io.FileOutputStream fos = new java.io.FileOutputStream(output);
fos.write(baos.toByteArray());
fos.close();
} private final static String readFile(String path, String encoding)
throws IOException {
File f = new File(path);
FileInputStream is = new FileInputStream(f);
BufferedInputStream bis = new BufferedInputStream(is);
ByteArrayOutputStream fos = new ByteArrayOutputStream();
byte buffer[] = new byte[2048];
int read;
do {
read = is.read(buffer, 0, buffer.length);
if (read > 0) {
fos.write(buffer, 0, read);
}
} while (read > -1);
fos.close();
bis.close();
is.close();
return fos.toString(encoding);
}
}
如上你就可以下载将html转为pdf了。任意文本也可以转为pdf,经测试,可用
附件如下:https://pan.baidu.com/s/1wSvBM6Kti4IpI9IlDaycew
以下为浏览器下载pdf的工具类。直接调用红色的方法即可。htmlDocument 为你要导出的数据,response为该次请求的响应体,fileName为下载的名字
package com.ccb.common.utils; import org.apache.commons.io.output.ByteArrayOutputStream;
import org.apache.commons.lang3.StringUtils; import javax.servlet.http.HttpServletResponse;
import java.awt.*;
import java.io.*;
import java.security.InvalidParameterException;
import org.zefer.pd4ml.PD4Constants;
import org.zefer.pd4ml.PD4ML; /**
* @author caihong
* @time 2019/1/28
*/
public class PDFUtil {
private static String PDF_TYPE="application/pdf"; private static String classpath=PDFUtil.class.getResource("/").getPath(); protected static int topValue = 10;
protected static int leftValue = 20;
protected static int rightValue = 10;
protected static int bottomValue = 10;
protected static int userSpaceWidth = 1300; public static void pdf4htmlToPdf(String htmlDocument,HttpServletResponse response, String filename)throws InvalidParameterException,
IOException {
PD4ML pd4ml = new PD4ML();
pd4ml.enableDebugInfo();
pd4ml.setHtmlWidth(userSpaceWidth);
pd4ml.setPageSize(pd4ml.changePageOrientation(PD4Constants.A4));
pd4ml.setPageInsetsMM(new Insets(topValue, leftValue, bottomValue,rightValue));
pd4ml.useTTF(classpath+"fonts", true);
pd4ml.setDefaultTTFs("SimSun", "SimSun", "SimSun");
ByteArrayOutputStream baos = new ByteArrayOutputStream();
pd4ml.render(new StringReader(htmlDocument), baos);
baos.close();
renderPdf(response,baos.toByteArray(),filename);
} public static void renderPdf(HttpServletResponse response, final byte[] bytes, final String filename) {
initResponseHeader(response, PDF_TYPE);
setFileDownloadHeader(response, filename, ".pdf");
if (null != bytes) {
try {
response.getOutputStream().write(bytes);
response.getOutputStream().flush();
} catch (IOException e) {
throw new IllegalArgumentException(e);
}
}
} /**
* 分析并设置contentType与headers.
*/
private static HttpServletResponse initResponseHeader(HttpServletResponse response, final String contentType, final String... headers) {
// 分析headers参数
String encoding = "utf-8";
boolean noCache = true;
for (String header : headers) {
String headerName = StringUtils.substringBefore(header, ":");
String headerValue = StringUtils.substringAfter(header, ":");
if (StringUtils.equalsIgnoreCase(headerName, "utf-8")) {
encoding = headerValue;
} else if (StringUtils.equalsIgnoreCase(headerName, "no-cache")) {
noCache = Boolean.parseBoolean(headerValue);
} else {
throw new IllegalArgumentException(headerName + "不是一个合法的header类型");
}
}
// 设置headers参数
String fullContentType = contentType + ";charset=" + encoding;
response.setContentType(fullContentType);
if (noCache) {
// Http 1.0 header
response.setDateHeader("Expires", 0);
response.addHeader("Pragma", "no-cache");
// Http 1.1 header
response.setHeader("Cache-Control", "no-cache");
}
return response;
} /**
* 设置让浏览器弹出下载对话框的Header.
* @param
*/
public static void setFileDownloadHeader(HttpServletResponse response, String fileName, String fileType) {
try {
// 中文文件名支持
String encodedfileName = new String(fileName.getBytes("GBK"), "ISO8859-1");
response.setHeader("Content-Disposition", "attachment; filename=\"" + encodedfileName + fileType + "\"");
} catch (UnsupportedEncodingException e) {
}
} private final static String readFile(String path, String encoding)
throws IOException {
File f = new File(path);
FileInputStream is = new FileInputStream(f);
BufferedInputStream bis = new BufferedInputStream(is);
java.io.ByteArrayOutputStream fos = new java.io.ByteArrayOutputStream();
byte buffer[] = new byte[2048];
int read;
do {
read = is.read(buffer, 0, buffer.length);
if (read > 0) {
fos.write(buffer, 0, read);
}
} while (read > -1);
fos.close();
bis.close();
is.close();
return fos.toString(encoding);
}
}
自己完成controller,以及mapping映射后,注意要用get请求
http://localhost:8080/api/img/exportPdf?htmlDocument=12%E7%9A%84%E5%8F%91%E9%A1%BA%E4%B8%B0%E9%98%BF%E6%96%AF%E9%A1%BF%E5%8F%91%E9%80%81%E5%88%B0%E5%8F%91%E9%80%81%E5%A4%A7&fileName=123
便可以下载pdf了
java转pdf(html转为pdf),解决中文乱码,标签不规范等问题的更多相关文章
- java web过滤器实际应用(解决中文乱码 html标签转义功能 敏感字符过滤功能)
转载地址:http://www.cnblogs.com/xdp-gacl/p/3952405.html 在filter中可以得到代表用户请求和响应的request.response对象,因此在编程中可 ...
- Java HttpURLConnection模拟请求Rest接口解决中文乱码问题
转自:http://blog.csdn.net/hwj3747/article/details/53635539 在Java使用HttpURLConnection请求rest接口的时候出现了POST请 ...
- Java读写.properties文件实例,解决中文乱码问题
package com.lxk.propertyFileTest; import java.io.*; import java.util.Properties; /** * 读写properties文 ...
- JAVA File方法文本复制读写-解决中文乱码
import java.io.*; public class TextFile { public static void main(String[] args) throws Exception { ...
- jquery插件导出excel和pdf(解决中文乱码问题)
参考文件:http://jackyrong.iteye.com/blog/2169683 https://my.oschina.net/aruan/blog/418980 https://segmen ...
- java web 中有效解决中文乱码问题-pageEncoding与charset区别, response和request的setCharacterEncoding 区别
这里先写几个大家容易搞混的编码设置代码: 在jsp代码中的头部往往有这两行代码 pageEncoding是jsp文件本身的编码contentType的charset是指服务器发送给客户端时的内容编码J ...
- Java ZIP压缩和解压缩文件(解决中文文件名乱码问题)
Java ZIP压缩和解压缩文件(解决中文文件名乱码问题) 学习了:http://www.tuicool.com/articles/V7BBvy 引用原文: JDK中自带的ZipOutputStrea ...
- java解压多目录Zip文件(解决中文乱码问题)--转载
原文地址:http://zhangyongbo.iteye.com/blog/1749439 import java.io.BufferedOutputStream; import java.io.F ...
- Debian 6解决中文乱码
DEBIAN下中文显示 一.首先检查LOCALE情况 说明:DEBIAN因为基于GNU所以,对不同地域进行了不同的包支持,以LOCALE形式存在. 1.挂载ISO文件包,前8个ISO包就可以(这里不在 ...
- 04_过滤器Filter_02_Filter解决中文乱码问题
[过滤器解决中文乱码问题实例] [工程截图] [web.xml] <?xml version="1.0" encoding="UTF-8"?> &l ...
随机推荐
- 浏览器透明设置例子,qt5.6才支持
用simpleBrowser例子的基础上,在BrowserWindow构造函数修改如下 BrowserWindow::BrowserWindow(QWidget *parent, Qt::Window ...
- vs2015 debugger,unable to attach to application iisexpress.exe
vs2015 unable to attach to application iisexpress.exe,没有可用的数据了 搞了一天也没解决...
- 编写高质量代码改善C#程序的157个建议——建议98:用params减少重复参数
建议98:用params减少重复参数 如果方法的参数数目不定,且参数类型一致,则可以使用params关键字减少重复参数声明. void Method1(string str, object a){} ...
- 编写高质量代码改善C#程序的157个建议——建议74:警惕线程的IsBackground
建议74:警惕线程的IsBackground 在CLR中,线程分为前台线程和后台线程,即每个线程都有一个IsBackground属性.两者在表现形式上的唯一区别是:如果前台线程不退出,应用程序的进程就 ...
- js调试工具Console命令详解——转
一.显示信息的命令 <!DOCTYPE html> <html> <head> <title>常用console命令</title> < ...
- MyBatis 一级缓存避坑
MyBatis 一级缓存(MyBaits 称其为 Local Cache)无法关闭,但是有两种级别可选: package org.apache.ibatis.session; /** * @autho ...
- [LeetCode 题解]: Valid Parentheses
Given a string containing just the characters '(', ')', '{', '}', '[' and ']', determine if the inpu ...
- Transaction And Lock--事务中使用return会回滚事务吗?
事务中使用return会回滚事务吗? 答案:不会,如果在事务中没有显示提交或回滚事务边return,事务不会被提交或回滚,在C#中,如果没有使用连接池,则事务在连接断开和销毁时被强制回滚,如果使用连接 ...
- Backup--完整备份会打破现有的日志备份链么?
--问题描述: --对数据库有一个周期性数据库备份和事务日志备份的维护计划,在维护计划外有工作人员对数据库进行完整备份,该备份会打乱现有的日志备份链么? --===================== ...
- BP神经网络研究(一)
本随笔参考文章:<BP神经网络详解与实例>(链接: https://pan.baidu.com/s/1e2niIvD9KtLXEqwXtgdXxw 密码: vb8d) 本随笔原创,转发请注 ...