【爬虫】Python2 爬虫初学笔记
爬虫,个人理解就是:利用模拟“操作浏览器”的过程,自动获取我们想要的数据(或者说信息,比如图片啊)
为何要学爬虫:爬取数据,为我所用(相当于可以把一类数据整合起来)
一.简单静态网页爬虫架构:
1.Background Knowledge:URL(统一资源定位符,能帮助我们定位到网页在网络中的位置,URI 是统一资源标志符),HTTP协议
2.构架:
需要一个爬虫调度器管理下面的程序,涉及多线程管理等(比如说申请网页的阻塞时间可以用来建立新的申请,这些资源分配由操作系统完成)
URL管理器,防止URL重复使用,获取URL,未爬取和已爬取的管理
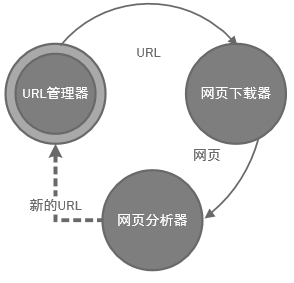
3.工作流程:
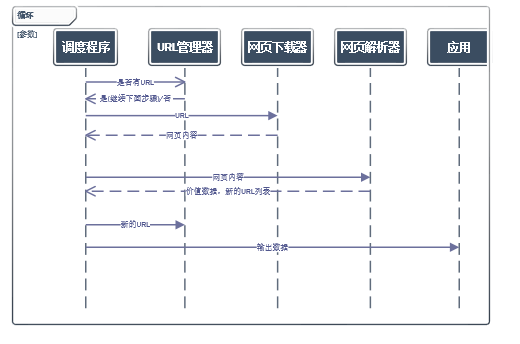
4.URL管理器实现方式:
a.存储在内存(set)
b.关系数据库(可永久保存)
c.缓存数据库(大部分公司使用这种方式)
5.网页下载器:
以HTML形式保存网页,可以使用urllib和urllib2实现下载
实现方法:
a.简单的使用urllib2.open(url)
b.添加Request方法,发送包头,伪装成浏览器
c.添加cookiejar cookie 容器
# coding=utf-8
import urllib2
import cookielib
url = "http://www.baidu.com"
print '方法1'
#请确保url 的合法性
response1 = urllib2.urlopen(url)
if response1.getcode()==200:
print ' 读取网页成功'
print ' Length:',
print len(response1.read())
else:
print ' 读取网页失败' print 'Method2:'
request = urllib2.Request(url)
request.add_header("usr_agent","Mozilla/6.0")
response2 = urllib2.urlopen(request)
if response2.getcode()==200:
print ' 读取网页成功'
print ' Length:',
print len(response2.read())
else:
print ' 读取网页失败' print 'Method3:'
cj = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
urllib2.install_opener(opener)
response3 = urllib2.urlopen(url)
if response3.getcode()==200:
print ' 读取网页成功'
print ' Length:',
print len(response3.read())
print cj
print response3.read()
else:
print ' 读取网页失败'
6.网页解析器:
以下载好的HTML当成字符串,查找出
1.正则表达式匹配
2.html.parser
3.lxml解析器
4.BeautifulSoup
以DOM(Document Object Model) 结构化解析,下面是其语法
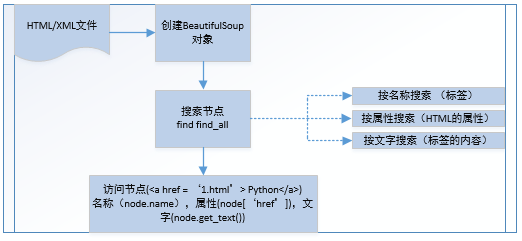
# coding=utf-8
import re from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacied" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p> <p class="story">...</p>
"""
#创建
ccsSoup = BeautifulSoup(html_doc,'html.parser',from_encoding='utf8')
#获取所有链接
links= ccsSoup.find_all('a')
for link in links:
print link.name,link['href'],link.get_text()
print ccsSoup.p('class') print '正则匹配'
link_node = ccsSoup.find('a',href= re.compile(r"h"),class_='sister')
print link_node
link_node = ccsSoup.find('a',href= re.compile(r"d"))
print link_node
5.调度程序
参考:
http://www.imooc.com/video/10686
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
正则表达式:
http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
PyCharm:使用教程
http://blog.csdn.net/pipisorry/article/details/39909057
【爬虫】Python2 爬虫初学笔记的更多相关文章
- python3爬虫--反爬虫应对机制
python3爬虫--反爬虫应对机制 内容来源于: Python3网络爬虫开发实战: 网络爬虫教程(python2): 前言: 反爬虫更多是一种攻防战,针对网站的反爬虫处理来采取对应的应对机制,一般需 ...
- Python 爬虫1——爬虫简述
Python除了可以用来开发Python Web之后,其实还可以用来编写一些爬虫小工具,可能还有人不知道什么是爬虫的. 一.爬虫的定义: 爬虫——网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区 ...
- C++ STL初学笔记
C++ STL初学笔记 更系统的版本见徐本柱的PPT set 在这儿:http://www.cnblogs.com/pdev/p/4035020.html #include <vector&g ...
- 【java爬虫】---爬虫+基于接口的网络爬虫
爬虫+基于接口的网络爬虫 上一篇讲了[java爬虫]---爬虫+jsoup轻松爬博客,该方式有个很大的局限性,就是你通过jsoup爬虫只适合爬静态网页,所以只能爬当前页面的所有新闻.如果需要爬一个网站 ...
- Spring 初学笔记
Spring 初学笔记: https://blog.csdn.net/weixin_35909255/article/category/7470388
- [爬虫]Python爬虫基础
一.什么是爬虫,爬虫能做什么 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.比如它在抓取一个网 ...
- (Pyhton爬虫03)爬虫初识
原本的想法是这样的:博客整理知识学习的同时,也记录点心情...集中式学习就没这么多好记录的了! 要学习一门技术,首先要简单认识一下爬虫!其实可以参考爬虫第一章! 整体上介绍该技术包含技能,具体能做什么 ...
- laravel 5.6初学笔记
laravel 5.6初学笔记 http://note.youdao.com/noteshare?id=bf4b701b49dd035564e7145ba2d978b4 框架简介 laravel文档齐 ...
- csapp网络编程初学笔记
csapp网络编程初学笔记 客户端-服务器编程模型 每个网络应用都是基于客户端-服务器模型,服务器管理某种资源,并且通过操作来为它的客户提供某种服务 客户端-服务器模型中的基本操作是transacti ...
- PYTHON爬虫实战_垃圾佬闲鱼爬虫转转爬虫数据整合自用二手急速响应捡垃圾平台_3(附源码持续更新)
说明 文章首发于HURUWO的博客小站,本平台做同步备份发布. 如有浏览或访问异常图片加载失败或者相关疑问可前往原博客下评论浏览. 原文链接 PYTHON爬虫实战_垃圾佬闲鱼爬虫转转爬虫数据整合自用二 ...
随机推荐
- SVN部署和使用
一.SVN介绍 svn(subversion)是近年来崛起的版本管理工具,是cvs的接班人.目前,绝大多数开源软件都使用svn作为代码版本管理软件. 二.服务器端和客户端 1.服务器端软件Subver ...
- 网络第三节——NSURLSession
有的程序员老了,还没听过NSURLSession有的程序员还嫩,没用过NSURLConnection有的程序员很单纯,他只知道AFN. NSURLConnection在iOS9被宣布弃用,NSURLS ...
- NDK笔记(二)-在Android Studio中使用ndk-build
前面一篇我们接触了CMake,这一篇写写关于ndk-build的使用过程.刚刚用到,想到哪儿写哪儿. 环境背景 Android开发IDE版本:AndroidStudio 2.2以上版本(目前已经升级到 ...
- windows安装redis
下载安装包,由于redis不提供windows版本,但是通过官网了解,如下: The Redis project does not officially support Windows. Howeve ...
- 推荐eclipse插件Properties Editor
需求:一般我们在做"国际化"功能时,我们需要properties中文表示方式用unicode表示.eclipse默认properties文件编辑器不方便查看,需要我们查看常常查找u ...
- angularjs向后台传递数据,与后端进行交互
angularjs之数据交互 function loadLeftFirstNodes (){ $http.get(sourceUrl,{ params:{ mpId: mpId, visits: ce ...
- SDN/NFV运营商商业化部署
三大运营商发布未来网络架构,并逐步加快SDN/NFV商业化部署的步伐.中国联通发布其新一代网络架构<CUBE-Net 2.0白皮书>,并与20多家合作伙伴共同启动了“新一代网络”合作研发计 ...
- C语言 活动安排问题
有若干个活动,第i个开始时间和结束时间是[Si,fi),只有一个教室,活动之间不能交叠,求最多安排多少个活动? #include <stdio.h> #include <stdlib ...
- Redis学习手册(主从复制)
一.Redis的Replication: 这里首先需要说明的是,在Redis中配置Master-Slave模式真是太简单了.相信在阅读完这篇Blog之后你也可以轻松做到.这里我们还是先列出一些理 ...
- Python 之旅
Python2 之旅: https://funhacks.net/explore-python/ <Python Cookbook>第三版 PYTHON3 http://pyt ...