数据分析之可反复与独立样本的T-Test分析
数据分析之独立样本的T-Test分析
比較两个独立样本数据之间是否有显著性差异,将实验数据与标准数据对照,查看
实验结果是否符合预期。T-Test在生物数据分析。实验数据效果验证中非经常见的数
据处理方法。http://www.statisticslectures.com/tables/ttable/ - T-table查找表
独立样本T-test条件:
1. 每一个样本相互独立没有影响
2. 样本大致符合正态分布曲线
3. 具有同方差异性
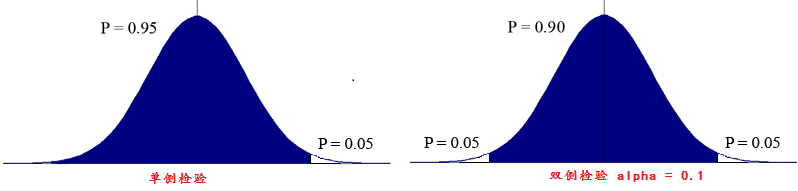
单側检验(one-tail Test)与双側检验(Two-Tail Test)
基本步骤:
1.双側检验, 条件声明 alpha值设置为0.05
依据t-table, alpha = 0.05, df = 38时, 对于t-table的值为2.0244
2. 计算自由度(Degree of Freedom)
Df = (样本1的总数 + 样本2的总数)- 2
3. 声明决策规则
假设计算出来的结果t-value的结果大于2.0244或者小于-2.0244则拒绝
4. 计算T-test统计值
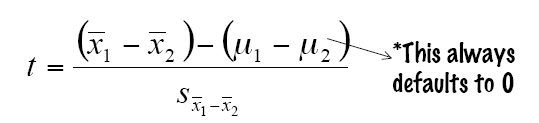
5. 得出结论
假设计算结果在双側区间之内,说明两组样本之间没有显著差异。
可反复样本的T-Test计算
相同一组数据在不同的条件下得到结果进行比对,发现是否有显著性差异,最常见
的对一个人在饮酒与不饮酒条件下驾驶车辆測试,非常easy得出酒精对驾驶员有显著
影响
算法实现:
对独立样本的T-Test计算最重要的是计算各自的方差与自由度df1与df2
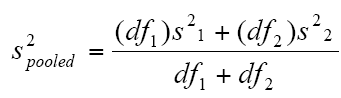
对可反复样本的对照t-test计算
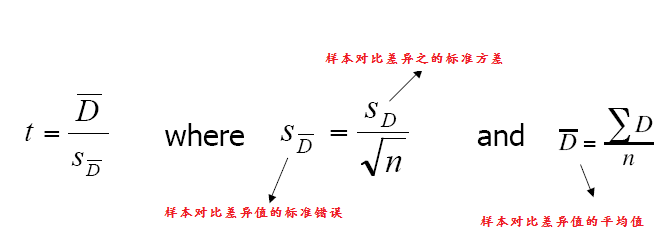
程序实现:
package com.gloomyfish.data.mining.analysis;
public class TTestAnalysisAlg {
private double alpahValue = 0.05; // default
private boolean dependency = false; // default
public TTestAnalysisAlg() {
System.out.println("t-test algorithm");
}
public double getAlpahValue() {
return alpahValue;
}
public void setAlpahValue(double alpahValue) {
this.alpahValue = alpahValue;
}
public boolean isDependency() {
return dependency;
}
public void setDependency(boolean dependency) {
this.dependency = dependency;
}
public double analysis(double[] data1, double[] data2) {
double tValue = 0;
if (dependency) {
// Repeated Measures T-test.
// Uses the same sample of subjects measured on two different
// occasions
double diffSum = 0.0;
double diffMean = 0.0;
int size = Math.min(data1.length, data2.length);
double[] diff = new double[size];
for(int i=0; i<size; i++)
{
diff[i] = data2[i] -data1[i];
diffSum += data2[i] -data1[i];
}
diffMean = diffSum / size;
diffSum = 0.0;
for(int i=0; i<size; i++)
{
diffSum += Math.pow((diff[i] -diffMean), 2);
}
double diffSD = Math.sqrt(diffSum / (size - 1.0));
double diffSE = diffSD / Math.sqrt(size);
tValue = diffMean / diffSE;
} else {
double means1 = 0;
double means2 = 0;
double sum1 = 0;
double sum2 = 0;
// calcuate means
for (int i = 0; i < data1.length; i++) {
sum1 += data1[i];
}
for (int i = 0; i < data2.length; i++) {
sum2 += data2[i];
}
means1 = sum1 / data1.length;
means2 = sum2 / data2.length;
// calculate SD (Standard Deviation)
sum1 = 0.0;
sum2 = 0.0;
for (int i = 0; i < data1.length; i++) {
sum1 += Math.pow((means1 - data1[i]), 2);
}
for (int i = 0; i < data2.length; i++) {
sum2 += Math.pow((means2 - data2[i]), 2);
}
double sd1 = Math.sqrt(sum1 / (data1.length - 1.0));
double sd2 = Math.sqrt(sum2 / (data2.length - 1.0));
// calculate SE (Standard Error)
double se1 = sd1 / Math.sqrt(data1.length);
double se2 = sd2 / Math.sqrt(data2.length);
System.out.println("Data Sample one - > Means :" + means1
+ " SD : " + sd1 + " SE : " + se1);
System.out.println("Data Sample two - > Means :" + means2
+ " SD : " + sd2 + " SE : " + se2);
// degree of freedom
double df1 = data1.length - 1;
double df2 = data2.length - 1;
// Calculate the estimated standard error of the difference
double spooled2 = (sd1 * sd1 * df1 + sd2 * sd2 * df2) / (df1 + df2);
double Sm12 = Math.sqrt((spooled2 / df1 + spooled2 / df2));
tValue = (means1 - means2) / Sm12;
}
System.out.println("t-test value : " + tValue);
return tValue;
}
public static void main(String[] args) {
int size = 10;
System.out.println(Math.sqrt(size));
}
}
測试程序:
package com.gloomyfish.dataming.study;
import com.gloomyfish.data.mining.analysis.TTestAnalysisAlg;
public class TTestDemo {
public static double[] data1 = new double[]{
35, 40, 12, 15, 21, 14, 46, 10, 28, 48, 16, 30, 32, 48, 31, 22, 12, 39, 19, 25
};
public static double[] data2 = new double[]{
2, 27, 38, 31, 1, 19, 1, 34, 3, 1, 2, 3, 2, 1, 2, 1, 3, 29, 37, 2
};
public static void main(String[] args)
{
TTestAnalysisAlg tTest = new TTestAnalysisAlg();
tTest.analysis(data1, data2);
tTest.setDependency(true);
double[] d1 = new double[]{2, 0, 4, 2, 3};
double[] d2 = new double[]{8, 4, 11, 5, 8};
// The critical value for a one-tailed t-test with
// df=4 and α=.05 is 2.132
double t = tTest.analysis(d1, d2);
if(t > 2.132 || t < -2.132)
{
System.err.println("Very Bad!!!!");
}
}
}数据分析之可反复与独立样本的T-Test分析的更多相关文章
- 数据分析 - 美国金融科技公司Prosper的风险评分分析
数据分析 - 美国金融科技公司Prosper的风险评分分析 今年Reinhard Hsu觉得最有意思的事情,是参加了拍拍贷第二届魔镜杯互联网金融数据应用大赛.通过"富爸爸队",认识 ...
- Android AbsListView子类反复调用getView()和getCount()问题分析
对于AbsListView子类,假设它的宽高是自适应的,你会发现getView()和getCount()会被疯狂的反复调用.即使在AbsListView子类设置完adapter后,getView()和 ...
- 【Pandas数据分析案例】2018年北京积分入户情况分析
据说,北京落户的难度比加入美国国籍还高.而北京2018年首次实行积分入户制,让我们来分析一下首批通过积分入户拿到北京户口的数据. 首先从北京积分落户官网下载公示名单: 根据表格中的信息,我们主要从以下 ...
- 吴裕雄--天生自然 python语言数据分析:开普勒系外行星搜索结果分析
import pandas as pd pd.DataFrame({'Yes': [50, 21], 'No': [131, 2]}) pd.DataFrame({'Bob': ['I liked i ...
- 如何利用Smartbi做数据分析:2018内5月热销乘用车分析报告
在2018年第一季度热销乘用车分析报告中,SUV以总体销量15.4%的同比增长率让人不可小觑,Smartbi刚得到5月分析的数据就迫不及待的来看看是否热度不减,结果在5月这个所谓汽车销售淡季,轿车以9 ...
- 探索性数据分析(Exploratory Data Analysis,EDA)
探索性数据分析(Exploratory Data Analysis,EDA)主要的工作是:对数据进行清洗,对数据进行描述(描述统计量,图表),查看数据的分布,比较数据之间的关系,培养对数据的直觉,对数 ...
- 如何选择数据分析工具?BI工具需要具备哪些功能?
数据分析使企业能够分析其所有数据(实时,历史,非结构化,结构化,定性),以识别模式并生成洞察力,以告知并在某些情况下使决策自动化,将数据情报与行动联系起来.当今最好的数据分析工具解决方案支持从访问.准 ...
- 【转】使用Apache Kylin搭建企业级开源大数据分析平台
http://www.thebigdata.cn/JieJueFangAn/30143.html 本篇文章整理自史少锋4月23日在『1024大数据技术峰会』上的分享实录:使用Apache Kylin搭 ...
- 零售业数据分析的媒介——BI工具
当你需要从一堆复杂庞大的数据中分析出有用的信息和结论的时,想必你一定觉得力不从心:数据的冗余使得你分析起来困难重重,怎么办呢?今天我们就来讲一下使数据分析变得简单有效的“手段”. 对于当今的中国零售行 ...
随机推荐
- SenCha Touch HTML 5 应用程序缓存
http://www.cnblogs.com/qidian10/p/3292876.html https://developer.mozilla.org/zh-CN/docs/HTML/Using_t ...
- WebIM技术---编写前端WebSocket组件
过去我们想要实现一个实时Web应用通常会考虑采用ajax轮循或者是long polling技术,但是因为频繁的建立http连接会带来多余的请求以及消息精准性的问题,让我们在实现实时Web应用时头疼不已 ...
- php 判断查询结果是否为空
select count(people) c from people where people='乐乐' 上面这条sql就是原理 php利用代码 <?php $p=$_POST['p']; $c ...
- GIMP 使用
在更改uboot启动logo的时候,需要P图,使用了linux的gimp.本文记录如何更改图片大小以及居中显示. 设置画布大小 在图片中右键 image -> Canvas Size 图片居中 ...
- 转载: crypto:start() 错误。
错误信息: Eshell V5.10.3 (abort with ^G)1> crypto:start().** exception error: undefined function cry ...
- Frameset 两页面互调控件技术案例
总共包含三个页面(Html),分别为Parent.Html.ChildA.Html.ChildB.Html Parent.Html页面代码 <frameset cols="50%,*& ...
- php队列算法[转]
<?php/*** php队列算法* * Create On 2010-6-4* Author Been* QQ:281443751* Email:binbin1129@126.com**/cl ...
- IOC和AOP的一些基本概念
IOC和AOP的一些基本概念介绍 IOC 介绍 IOC 一.什么是IOC IoC就是Inversion of Control,控制反转.在Java开发中,IoC意味着将你设计好的类交给系统去控制,而不 ...
- Spring_day04--HibernateTemplate介绍_整合其他方式_Spring分模块开发
HibernateTemplate介绍 1 HibernateTemplate对hibernate框架进行封装, 直接调用HibernateTemplate里面的方法实现功能 2 HibernateT ...
- swift - storyboard(故事版)的使用
iOS开发中,苹果公司提供了一种可视化的编程方式:即xib和storyboard,xib相对来说比较灵活,可以在纯代码的项目中使用, 也可以和storyboard配合使用,用法都差不多,下面来总结一下 ...