获取网站证书的两种方法(wireshark or firefox nightly)
一、使用Wireshark 截取数据包的方式
1. wireshark软件需要使用管理员权限运行,开始捕获后,按下ctrl + f,查找证书所在分组,从source 和destination 栏可以看到目标网站的IP和本机IP。
2. 在secure sockets layer找到证书,并复制为HEX流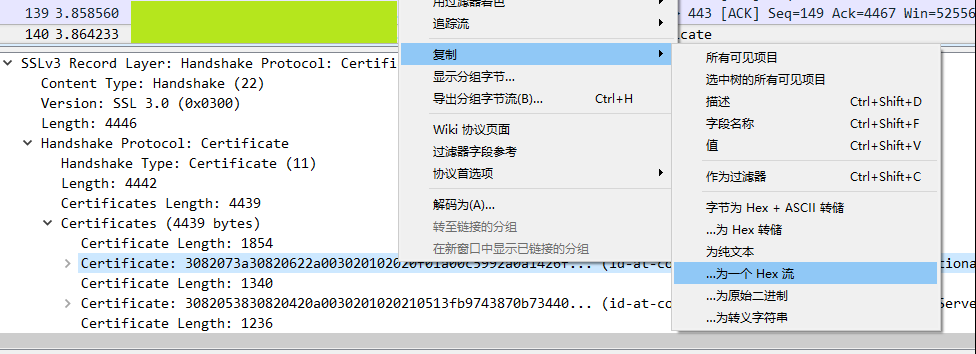
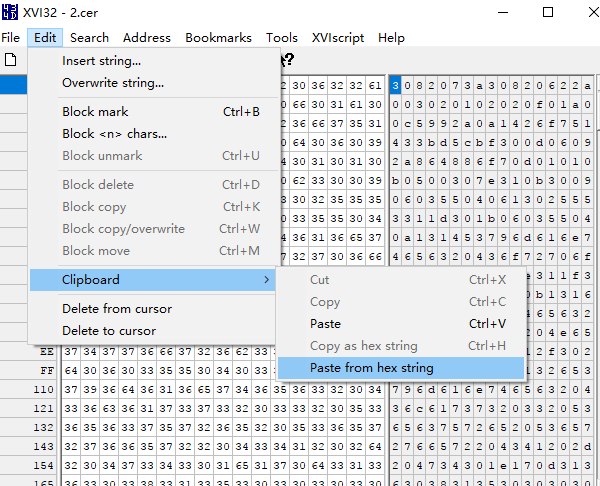
3. 使用XVI32新建文档,通过edit->clipboard->paste from hexstring 粘贴 证书,保存为cer或crt格式。
XVI32 下载地址:http ://www.chmaas.handshake.de/delphi/freeware/xvi32/xvi32.htm
二、一种更简单的方法,通过firefox 的nightly版本(其他版本未试过),直接export
/* 后经测试,IE浏览器也可以获取网站的证书,方法类似,但似乎有些不稳定,不适用于所有网站 ,例如 Bing 的搜索主页,若
选择国内版则无法获取,需要切换为国际版才可 */
1.打开目标网站,点击网址栏前面的绿色锁图标,点击扩展图标
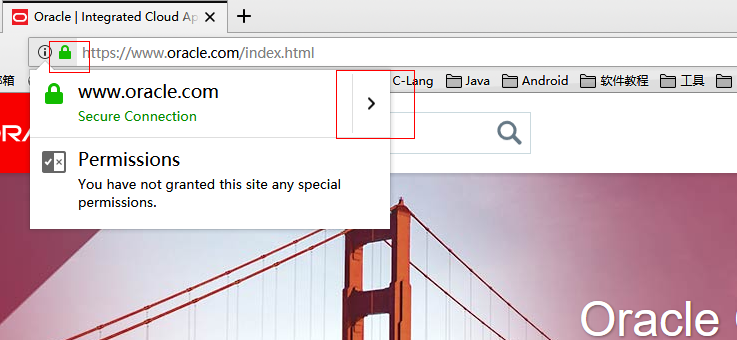
2.在弹出的窗口中选择 More Information

3. Security -> View Certificate
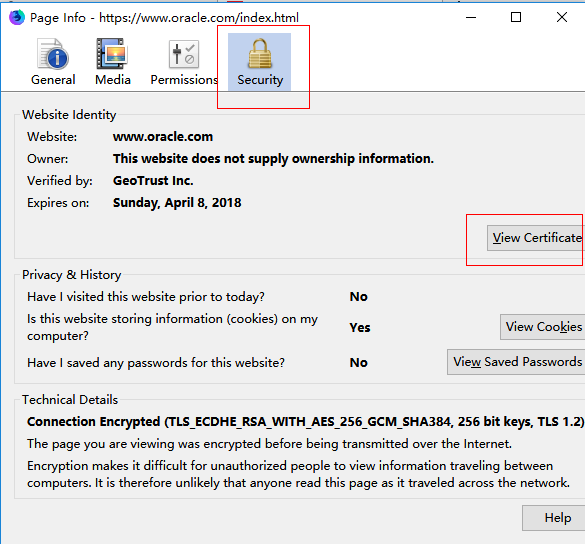
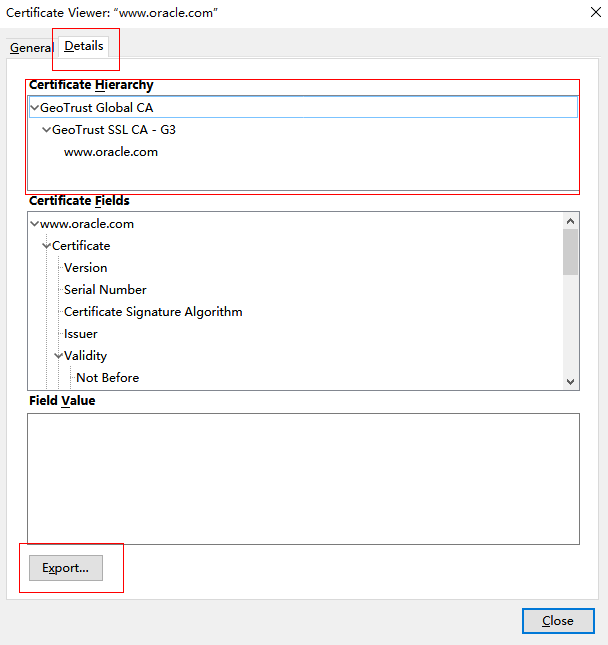
4. Details -> Export...,可以在 Certificate Hierarchy 处选择根证书或、中间证书或服务器证书。
获取网站证书的两种方法(wireshark or firefox nightly)的更多相关文章
- windows下获取IP地址的两种方法
windows下获取IP地址的两种方法: 一种可以获取IPv4和IPv6,但是需要WSAStartup: 一种只能取到IPv4,但是不需要WSAStartup: 如下: 方法一:(可以获取IPv4和I ...
- tensorflow中的函数获取Tensor维度的两种方法:
获取Tensor维度的两种方法: Tensor.get_shape() 返回TensorShape对象, 如果需要确定的数值而把TensorShape当作list使用,肯定是不行的. 需要调用Tens ...
- APP自动化测试获取包名的两种方法
获取包名的两种方法: 一.通过aapt获取 1.进入aapt.exe所在路径 2.在地址栏输入cmd回车,打开dos命令窗口. 3.在命令窗口输入 aapt dump badging 拖入apk 回车 ...
- 微信网页开发之获取用户unionID的两种方法--基于微信的多点登录用户识别
假设网站A有以下功能需求:1,pc端微信扫码登录:2,微信浏览器中的静默登录功能需求,这两种需求就需要用到用户的unionID,这样才能在多个登录点(终端)识别用户.那么这两种需求下用户的unionI ...
- docker inspect获取详细参数的两种方法
docker inspect xx 返回的是一个json格式的数据 以下为部分返回值 [ { "Id": "706813b0da107c4d43c61e3db9da908 ...
- thinkphp获取特定字段的两种方法
thinkphp getField( )和field( ) 2014年10月05日 ⁄ 综合 ⁄ 共 1509字 ⁄ 字号 小 中 大 ⁄ 评论关闭 做数据库查询的时候,比较经常用到这两个,总是查手册 ...
- js获取url参数的两种方法
js获取参数,在以前我都是用正在去拆分,然后获取,这种方式感觉是最简单的 方式1: function QueryString(item) { var sValue=location.search.ma ...
- Java获取当前类名的两种方法
适用于非静态方法:this.getClass().getName() 适用于静态方法:Thread.currentThread().getStackTrace()[1].getClassName() ...
- js+jquery动态设置/添加/删除/获取元素属性的两种方法集锦对照(动态onclick属性设置+动态title设置)
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0//EN" "http://www.w3.org/TR/REC-html140 ...
随机推荐
- Linux系统上安装JDK和Tomcat服务器
一.安装JDK 1.查看当前Linux系统是否已经安装java 输入命令: rpm -qa | grep java 2.卸载两个openJDK 输入命令:rpm -e --nodeps 3.上传j ...
- 阿里云部署SSL证书详解
http://mp.weixin.qq.com/s/NV7Zad4DVEgzG2GCHYJVLw 查找中间证书 为了确保兼容到所有浏览器,我们必须在阿里云上部署中间证书,如果不部署证书,虽然安装过程可 ...
- 怎么解决dede首页网址自动加上index.html
怎样去掉dedecms5.7(织梦)首页url后index.html有三种方法 1.去配置你的空间的默认首页地址.把index.html移到默认文本最前面.(确保你的默认文档里面有index.html ...
- redux学习日志:关于异步action
当我们在执行某个动作的时候,会直接dispatch(action),此时state会立即更新,但是如果这个动作是个异步的呢,我们要等结果出来了才能知道要更新什么样的state(比如ajax请求),那就 ...
- SuperSocket基础一
SuperSocket基础(一)——————基本概念 项目中之前一直使用TCP socket服务框架,但是不利于扩展.最近刚接触到开源的superSocket感觉很不错,特记录一下.官方开源地址:ht ...
- 进程间通信之利用CreateFilemapping()
这两天在复习进程间通信,复习一下记不住,复习一下记不住...就写个小博客献个丑,先来第一个内存映射 代码亲测通过 CreateFileMapping()的最后的一位用来做进程间通信 步骤: 1.Cre ...
- Mysql覆盖索引 covering index 或者 index coverage
组合索引 提到组合索引,大家都知道"最左前缀"原则.例如,创建索引 idx_name_age (name,age) ,通常情况下,where age=50 或者 where age ...
- Map排序与有序
排序: private static List<Map.Entry<String, Long>> sortHashMap(HashMap<String,Long> ...
- 布衣之路(一):VMware虚拟机+CentOS系统安装
前言:布衣博主乃苦逼的Java程序猿一枚,虽然工作中不会涉及系统运维,但是开发的项目总还是要部署到服务器做一些负载均衡.系统兼容性测试.系统集成等等骚操作,而这些测试性的操作不可能直接SSH远程运维的 ...
- 【转】Linux 服务器安全配置
第一部分:RedHat Linux篇1.概述 Linux服务器版本:RedHat Linux AS 2.1 对于开放式的操作系统---Linux,系统的安全设定包括系统服务最小化.限制远程存取.隐藏重 ...