nodejs爬虫笔记(五)---利用nightmare模拟点击下一页
目标
以腾讯滚动新闻为例,利用nightmare模拟点击下一页,爬取所有页面的信息。首先得感谢node社区godghdai的帮助,开始接触不太熟悉nightmare,感觉很高大上,自己写代码的时候问题也很多,多亏大神的指点。
一、选择模拟的原因
腾讯滚动新闻,是每六十秒更新一次,而且有下一页。要是直接获取页面的话得一页一页的获取,不太方便,又想到了找数据接口,然后通过请求得到数据,结果腾讯新闻的数据接口是加密的,这种想法又泡汤了。因而想到笔记(四)中模拟加载更多的模块,看利用nightmare这个模块模拟点击下一页,是不是就可以获取全部新闻的信息了呢。
二、分析页面
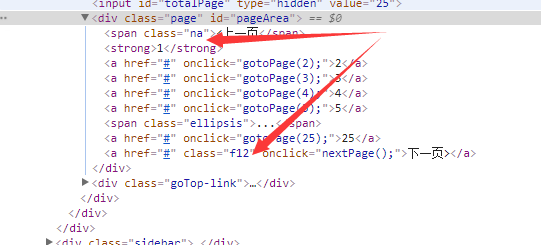
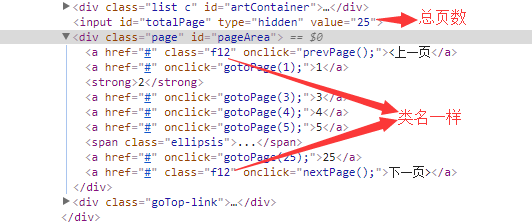
打开腾讯滚动新闻页面,通过浏览器点击检查,选择页码部分内容(如图),此时是第一页,上一页的类名是"na",下一页的类名是是"f12",再点击第二页的时候会发现上一页和下一页的类名都是"f12",要选择下一页,可以利用Jquery选择器中过滤元素的方法,如:$('#pageArea .f12:contains("下一页")'),这样就可以选择点击下一页了。从下图可以看到页面去还有页面总数,因此可以获取页面总数,然后通过页面总数做一个点击的判断,直到点击到最后一页。再点击到最后一页,会发现下一页的类名会变成"na",因此,我们也可以通过下一页的类名变化判断是否点击到了最后一页。
三、思路一(利用总页数)
1、在nightmare的wait方法里面等待页面加载完成。
2、之后获取总页数,没点击一次,总页数就减一,直到最后一页,点击完成,wait方法才返回true。
在文件目录下新建qqnightmare.js(需要安装相关模块),编辑如下代码:
var Nightmare = require('nightmare');
var nightmare = Nightmare({
show: true//显示electron窗口
});
nightmare
//加载页面
.goto('http://roll.news.qq.com/')
.wait(function() {
return document.querySelectorAll("#artContainer li").length>0;//通过新闻列表的长度,来判断页面是否加载完成
})
.inject('js','jquery.min.js')//插入jquery
.wait(function(){
if(window.qqNews === undefined){
//定义变量
window.qqNews={
page :$("#totalPage").val();,
arr : []
};
if(qqNews.page!==1){
$('#artContainer li').each(function(){
var title = $(this).find('a').text();
qqNews.arr.push(title);
});
$('#pageArea .f12:contains("下一页")').click();
qqNews.page -= 1;
return false;
}
if(qqNews.page===1){
$('#artContainer li').each(function(){
var title = $(this).find('a').text();
qqNews.arr.push(title);
});
return true;
}
}
return false;
})
.evaluate(function(){
return qqNews.arr;
})
.end()
.then(function(res){
console.log(res,res.length);
})
.catch(function (error) {
console.error('failed:', error);
});
在后台打开文件夹,运行node qqnightmare ,会发现wait方法等待超时。检查代码后发现wait方法一直没有返回true,因为每次判断qqNews.page!==1,会返回false,再次调用又会重新定义一个变量,因此一直会返回false,根本不会返回true。是不是可以添加一个wait用来定义变量,改写代码如下:
var Nightmare = require('nightmare');
var nightmare = Nightmare({
show: true//显示electron窗口
// waitTimeout : 5000
});
nightmare
//加载页面
.goto('http://roll.news.qq.com/')
.wait(function() {
return document.querySelectorAll("#artContainer li").length>0;
})
.inject('js','jquery.min.js')
.wait(function(){
window.qqNews=[];
page = $("#totalPage").val();
return true;
})
.wait(function(){
if(page!==1){
$('#artContainer li').each(function(){
var title = $(this).find('a').text();
qqNews.push(title);
});
$('#pageArea .f12:contains("下一页")').click();
page -= 1;
return false;
}
if(page===1){
$('#artContainer li').each(function(){
var title = $(this).find('a').text();
qqNews.push(title);
});
return true;
}
return false;
})
.evaluate(function(){
return qqNews;
})
.end()
.then(function(res){
console.log(res,res.length);
})
.catch(function (error) {
console.error('failed:', error);
});
再点击运行,会发现所有的新闻都打印出来了。
四、思路二(根据下一页类名判断)
var Nightmare = require('nightmare');
var nightmare = Nightmare({
show: true //显示electron窗口
});
nightmare
.goto('http://roll.news.qq.com/')
.wait(function() {
return !document.querySelector(".loading");
})
.wait(function() {
window._$qqNews = [];
return true;
})
.wait(function() {
//如果显示正在加载中……
if (document.querySelector(".loading")) return false;
var newslist = document.querySelectorAll("#artContainer li a");
for (var i = 0; i < newslist.length; i++) {
_$qqNews.push({
title: newslist[i].childNodes[0].data,
href: newslist[i].href
});
}
var next_page_button = document.querySelector("#pageArea .f12:last-child");
if (next_page_button) {
next_page_button.click();
return false;
}
return true;
})
.evaluate(function() {
return _$qqNews;
})
.end()
.then(function(res) {
console.log(res[res.length-1], res.length);
})
.catch(function(error) {
console.error('failed:', error);
});
运行后会发现所有新闻也都打印到后台了,另外大神还给出了另外一种方法,自己不太懂,也就不多说了,就放这存一下吧。
五、通过js文件获取全部新闻信息
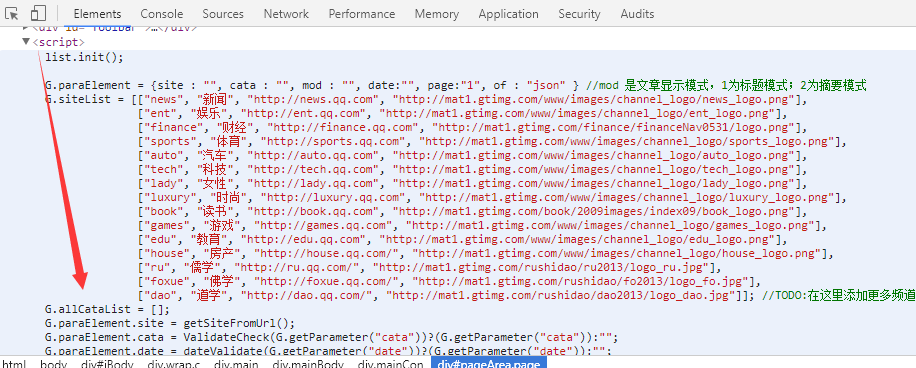
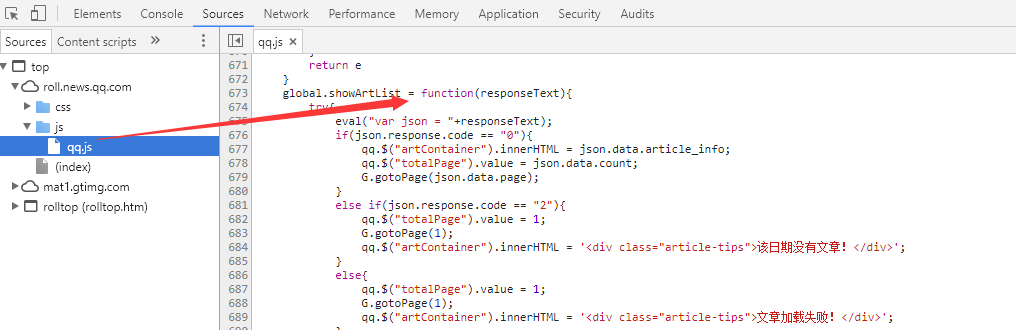
点击检查页面,会发现相应的js内容如下图,再点击sources查看js,会发现js文件夹下有qq.js文件,这个文件里面包含了所有的方法等信息。
大神给的代码:
var Nightmare = require('nightmare');
var nightmare = Nightmare({
show: true,
pollInterval: 1000
});
nightmare
.goto('http://roll.news.qq.com/')
.wait(function() {
return document.querySelectorAll("#artContainer li").length>0;
})
.wait(function() {
if (window._$qqNews == undefined) {
window._$qqNews = {
total: 0,
page: 0,
items: []
}
//停止自动刷新
AutoRefresh();
_$qqNews.total = qq.$("totalPage").value;
G.showArtList = function(responseText) {
try {
eval("var json = " + responseText);
if (json.response.code == "0") {
qq.$("artContainer").innerHTML = json.data.article_info;
//
var newslist = document.querySelectorAll("#artContainer li a");
for (var i = 0; i < newslist.length; i++) {
_$qqNews.items.push({
title: newslist[i].childNodes[0].data,
href: newslist[i].href
});
}
qq.$("totalPage").value = json.data.count;
if (_$qqNews.total > 1) {
_$qqNews.total -= 1;
nextPage();
}
} else if (json.response.code == "2") {
qq.$("totalPage").value = 1;
G.gotoPage(1);
qq.$("artContainer").innerHTML = '<div class="article-tips">该日期没有文章!</div>';
} else {
qq.$("totalPage").value = 1;
G.gotoPage(1);
qq.$("artContainer").innerHTML = '<div class="article-tips">文章加载失败!</div>';
}
} catch (e) {}
}
//加载第1页
Refresh();
return false;
}
if (_$qqNews.total == 1)
return true;
return false;
}).evaluate(function() {
return _$qqNews.items;
})
.end()
.then(function(result) {
console.log(result, result.length)
}).catch(function(error) {
console.log('错误是:' + error);
})
运行之后,会发现运行时间相对来讲要比前面两种快一些。
六、总结
通过一段时间的爬虫,发现静态页面可以直接通过request和cheerio等模块直接获取,但对于动态页面,尽量先找数据接口,如果数据接口加密或者解析不出来,再去考虑用模拟浏览器,因为模拟浏览器会耗时间,当数据量一大,运行时间就会很长。
nodejs爬虫笔记(五)---利用nightmare模拟点击下一页的更多相关文章
- nodejs爬虫笔记(四)---利用nightmare解决加载更多问题
目标: 解决页面加载更多问题.笔记三中,我们只爬取到网页的部分信息,而点击加载更多后的页面内容是没有提取到的.开始我的想法是找到加载更多的数据接口(可参照:http://www.jianshu.com ...
- nodejs爬虫笔记(三)---爬取YouTube网站上的视频信息
思路:通过笔记(二)中代理的设置,已经可以对YouTube的信息进行爬取了,这几天想着爬取网站下的视频信息.通过分析YouTube,发现可以从订阅号入手,先选择几个订阅号,然后爬取订阅号里面的视频分类 ...
- nodejs爬虫笔记(二)---代理设置
node爬虫代理设置 最近想爬取YouTube上面的视频信息,利用nodejs爬虫笔记(一)的方法,代码和错误如下 var request = require('request'); var chee ...
- PYTHON 爬虫笔记十:利用selenium+PyQuery实现淘宝美食数据搜集并保存至MongeDB(实战项目三)
利用selenium+PyQuery实现淘宝美食数据搜集并保存至MongeDB 目标站点分析 淘宝页面信息很复杂的,含有各种请求参数和加密参数,如果直接请求或者分析Ajax请求的话会很繁琐.所以我们可 ...
- PYTHON 爬虫笔记八:利用Requests+正则表达式爬取猫眼电影top100(实战项目一)
利用Requests+正则表达式爬取猫眼电影top100 目标站点分析 流程框架 爬虫实战 使用requests库获取top100首页: import requests def get_one_pag ...
- nodejs爬虫笔记(一)---request与cheerio等模块的应用
目标:爬取慕课网里面一个教程的视频信息,并将其存入mysql数据库.以http://www.imooc.com/learn/857为例. 一.工具 1.安装nodejs:(操作系统环境:WiN 7 6 ...
- PYTHON 爬虫笔记九:利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集(实战项目二)
利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集 目标站点分析 今日头条这类的网站制作,从数据形式,CSS样式都是通过数据接口的样式来决定的,所以它的抓取方法和其他网页的抓取方 ...
- Python爬虫笔记【一】模拟用户访问之设置请求头 (1)
学习的课本为<python网络数据采集>,大部分代码来此此书. 网络爬虫爬取数据首先就是要有爬取的权限,没有爬取的权限再好的代码也不能运行.所以首先要伪装自己的爬虫,让爬虫不像爬虫而是像人 ...
- Python爬虫笔记【一】模拟用户访问之Tesseract-ocr验证码训练(5)
验证码处理之后就需要对处理的验证码进行识别训练,这里用Tesseract-ocr工具进行识别,用jTessBoxeditor进行训练生成模板. 一,对图片进行处理 利用上一篇代码对图片进行降噪处理,得 ...
随机推荐
- windows 连接Linux
服务器:阿里云 ecs 从 Windows 环境远程登录 Linux 实例 远程登录软件的用法大同小异.本文档以 Putty 为例,介绍如何远程登录实例.Putty 操作简单.免费.免安装, 下载地址 ...
- Elastic-Job-一个分布式调度解决方案
注:Elastic-Job是一个分布式调度解决方案,由两个相互独立的子项目Elastic-Job-Lite和Elastic-Job-Cloud组成.Elastic-Job-Lite定位为轻量级无中心化 ...
- 【转】Java中super和this的几种用法与区别
1. 子类的构造函数如果要引用super的话,必须把super放在函数的首位. class Base { Base() { System.out.println("Base&qu ...
- javascript初识
1.什么是js 基于对象和事件驱动并且具有相对安全性的客户端脚本语言,由网景公司开发. 2.js数据类型 1.基本数据类型 undefined,null,number,boolean,st ...
- POJ 3264 Balanced Lineup【线段树区间查询求最大值和最小值】
Balanced Lineup Time Limit: 5000MS Memory Limit: 65536K Total Submissions: 53703 Accepted: 25237 ...
- Big Event in HDU(多重背包套用模板)
http://acm.hdu.edu.cn/showproblem.php?pid=1171 Big Event in HDU Time Limit: 10000/5000 MS (Java/Othe ...
- Windows系统下文件的概念及c语言对其的基本操作(丙)
- 我的第一个python web开发框架(20)——产品发布(部署到服务器)
首先按上一章节所讲述的,将服务器环境安装好以后,接下来就是按步骤将网站部署到服务器上了. 我们的站点是前后端分离的,所以需要部署两个站点.首先来发布前端站点. 部署前端站点 输入命令进入svn管理文件 ...
- UE4 custom depth 自定义深度
用途1: 半透明材质中实现遮挡Mesh自己其他部分的效果. 不遮挡效果如下: 遮挡后效果如下: 实现方法: 深度信息是越远值越大,使用两个Mesh,一个正常渲染,另一个渲染到custom depth ...
- phpstudy中的mysql
1.进入mysql命令台,执行 select version()即可 2status;