Lloyd’s 算法 和 K-Means算法
在讲Lloyd’s 算法之前先介绍Voronoi图
在数学中,Voronoi图是基于到平面的特定子集中的点的距离将平面划分成区域。预先指定一组点(称为种子,站点或生成器),并且对于每个种子,存在相应的区域,该区域由更接近该种子的所有点组成,而不是任何其他点。这些区域称为Voronoi细胞。

在最简单的情况下,如图所示,我们在欧几里德平面上给出了一组有限的点{p1,...,pn}。在这种情况下每个站点pk只是一个点,其相应的Voronoi单元Rk由欧几里德平面中的每个点组成,其与pk的距离小于或等于其与任何其他pk的距离。每个这样的单元是从半空间的交点获得的,因此它是凸多边形。 Voronoi图的边界是平面中与两个最近的站点等距的所有点。 Voronoi顶点(节点)是与三个(或更多)站点等距的点。
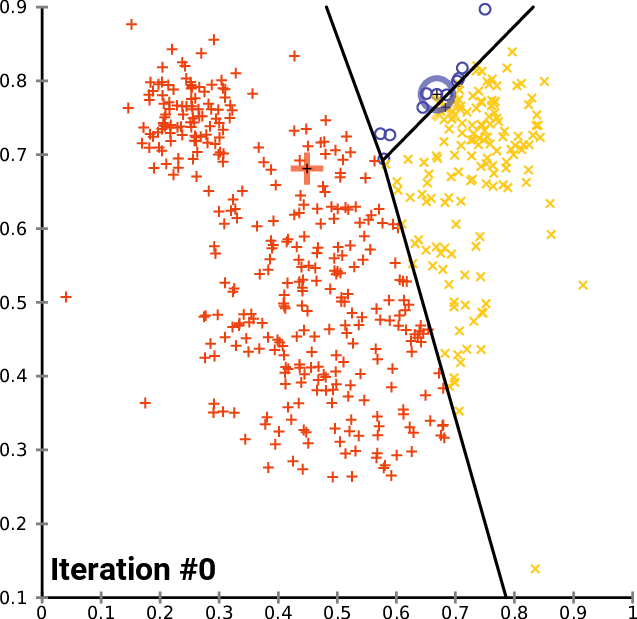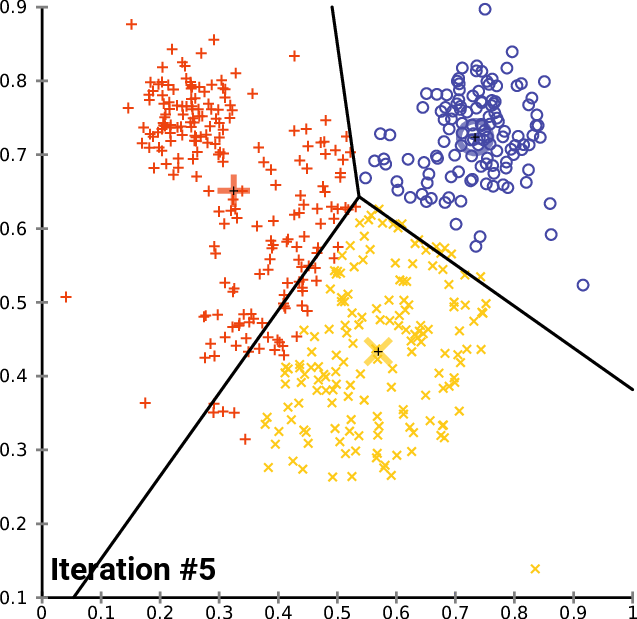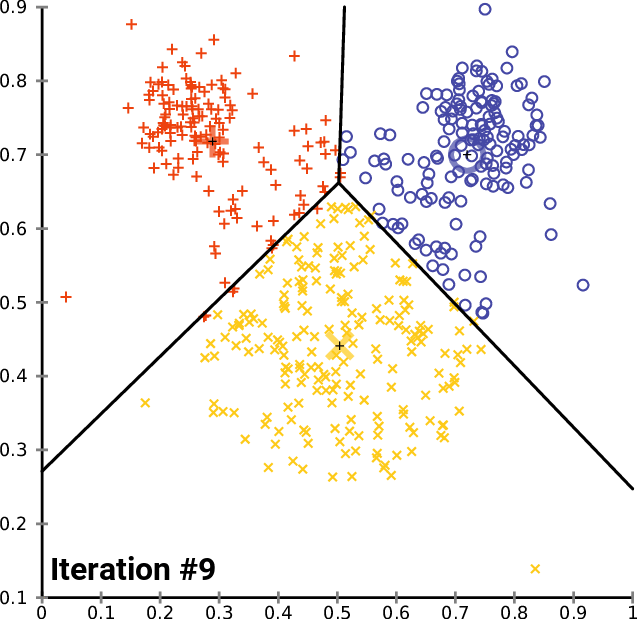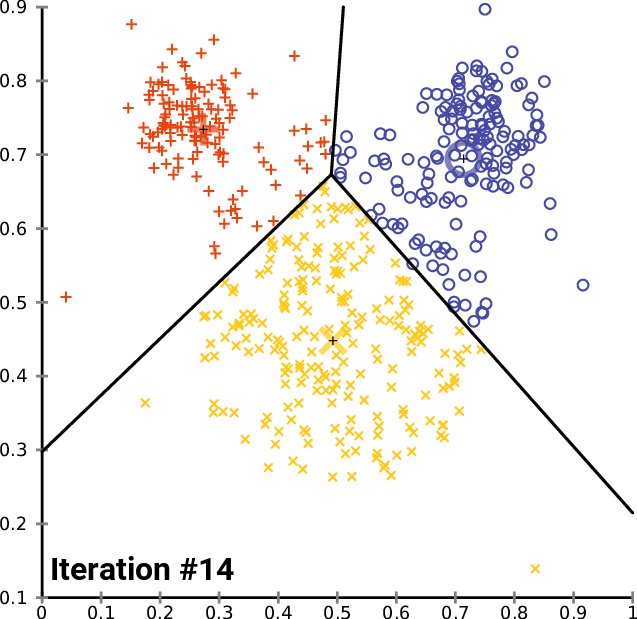
Lloyd’s algorithm 过程:
(1)首先在数据集中随机选定k个初始点
(2) 计算k个站点的Voronoi图。
(3)整合Voronoi图的每个单元格,并计算质心。
(4)然后将每个站点(k)移动到其Voronoi单元的质心。
如下图迭代过程
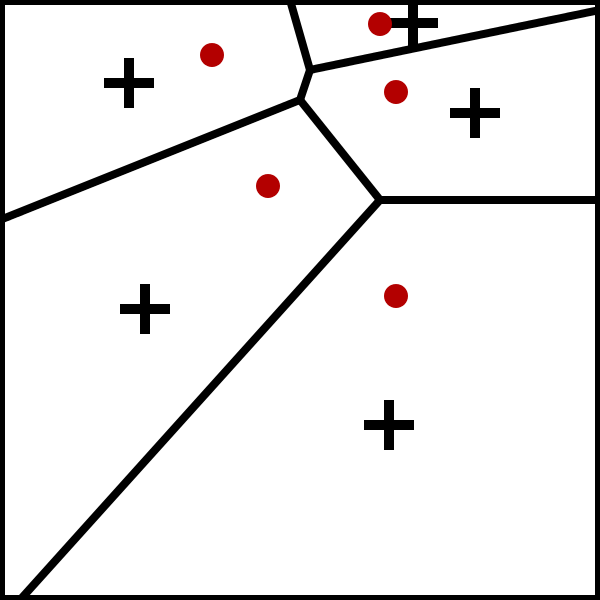
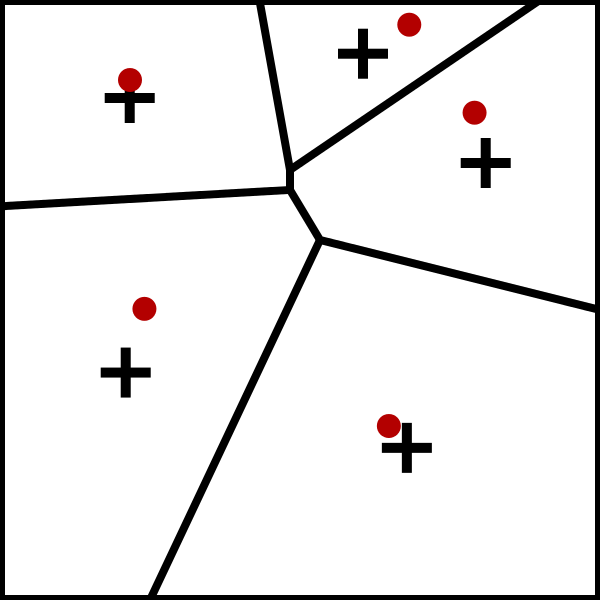
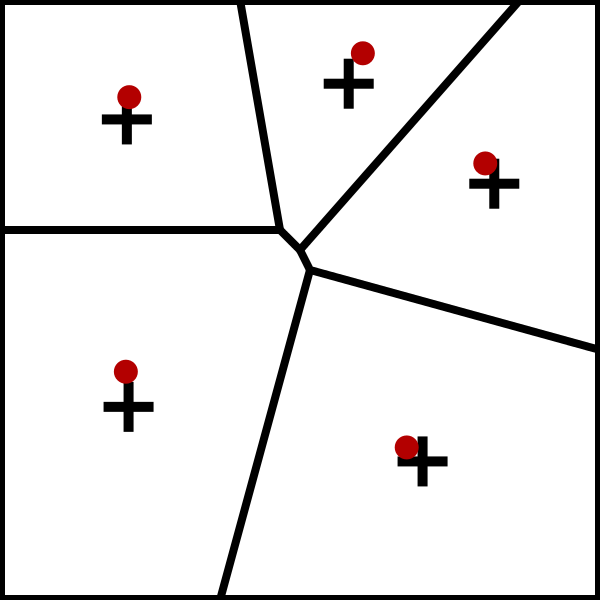
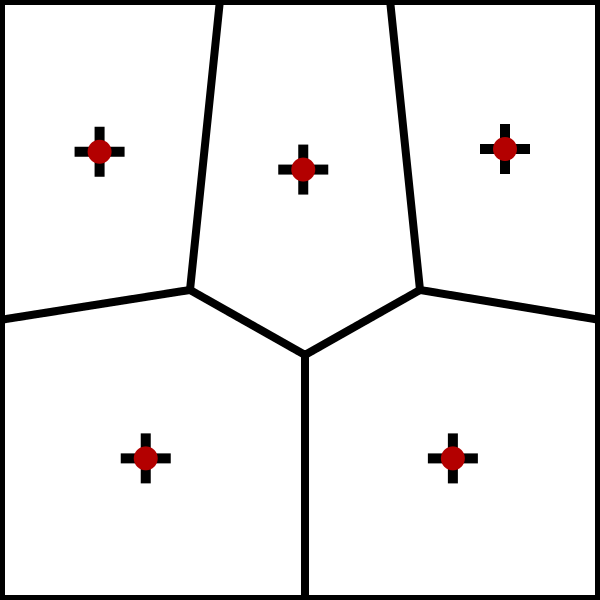
K-Means算法过程:
(1)随机初始化k个聚类中心的位置
(2)计算每一个点到聚类中心的距离,选取最小值分配给k(i)
(3)移动聚类中心(其实就是对所属它的样本点求平均值,就是它移动是位置)
(4)重复(2),(3)直到损失函数(也就是所有样本点到其所归属的样本中心的距离的和最小)
最后整体分类格局会变得稳定。
如下图
通过对比,可以发现这两个算法之间有许多相似之处,都是迭代的寻找聚族中心的位置。
然而,Lloyd’s算法与k均值聚类的不同之处在于,Lloyd’s的输入是一个连续的几何区域,而不是一组离散的点。
因此,当重新划分输入时,劳埃德算法使用Voronoi图而不是像k-means算法那样简单地确定每个有限点集的最近中心。
Lloyd’s 算法 和 K-Means算法的更多相关文章
- 机器学习算法之Kmeans算法(K均值算法)
Kmeans算法(K均值算法) KMeans算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑 ...
- 机器学习——KNN算法(k近邻算法)
一 KNN算法 1. KNN算法简介 KNN(K-Nearest Neighbor)工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分 ...
- 【算法】K最近邻算法(K-NEAREST NEIGHBOURS,KNN)
K最近邻算法(k-nearest neighbours,KNN) 算法 对一个元素进行分类 查看它k个最近的邻居 在这些邻居中,哪个种类多,这个元素有更大概率是这个种类 使用 使用KNN来做两项基本工 ...
- 机器学习(Machine Learning)算法总结-K临近算法
一.算法详解 1.什么是K临近算法 Cover 和 Hart在1968年提出了最初的临近算法 属于分类(classification)算法 邻近算法,或者说K最近邻(kNN,k-NearestNeig ...
- 图说十大数据挖掘算法(一)K最近邻算法
如果你之前没有学习过K最近邻算法,那今天几张图,让你明白什么是K最近邻算法. 先来一张图,请分辨它是什么水果 很多同学不假思索,直接回答:“菠萝”!!! 仔细看看同学们,这是菠萝么?那再看下边这这张图 ...
- 机器学习算法之K近邻算法
0x00 概述 K近邻算法是机器学习中非常重要的分类算法.可利用K近邻基于不同的特征提取方式来检测异常操作,比如使用K近邻检测Rootkit,使用K近邻检测webshell等. 0x01 原理 ...
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- Python实现机器学习算法:K近邻算法
''' 数据集:Mnist 训练集数量:60000 测试集数量:10000(实际使用:200) ''' import numpy as np import time def loadData(file ...
- 数据挖掘十大算法--K-均值聚类算法
一.相异度计算 在正式讨论聚类前,我们要先弄清楚一个问题:怎样定量计算两个可比較元素间的相异度.用通俗的话说.相异度就是两个东西区别有多大.比如人类与章鱼的相异度明显大于人类与黑猩猩的相异度,这是能 ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
随机推荐
- Android,View转换bitmap,bitmap转换drawable
Android View转换Bitmap,Bitmap转换Drawable //测试设置bitmap View view1 = ViewGroup.inflate(context, R.layout. ...
- Linux - 微软无线鼠标滚动过快问题
Linux - 微软无线鼠标滚动过快问题 使用了一段时间的 Manjaro , 感觉相当不错, 但有一个蛋疼的地方就是每次滚动鼠标滚轮, 都会切换一页以上的页面, 总是有一部分看不到. 之前以为是 L ...
- IPV6地址中的%号什么意思
在我配置ipv6 网络中,会发现ipv6地址后有%号,这表示什么呢? IPv6地址中的百分号是网卡interface标识.这个表示该地址仅限于标号为21的网络接口(一般指网卡或者虚拟网卡).而在其他网 ...
- scrapy 命令行基本用法
1.创建一个新项目: scrapy startproject myproject 2.在新项目中创建一个新的spider文件: scrapy genspider mydomain mydomain.c ...
- libgdx学习记录2——文字显示BitmapFont
libgdx对中文支持不是太好,主要通过Hireo和ttf字库两种方式实现.本文简单介绍最基本的bitmapfont的用法. 代码如下: package com.fxb.newtest; import ...
- css简单的一些基础知识
css层叠样式表(英文全称:Cascading Style Sheets)是一种用来表现HTML(标准通用标记语言的一个应用)或XML(标准通用标记语言的一个子集)等文件样式的计算机语言.CSS不仅可 ...
- React 精要面试题讲解(二) 组件间通信详解
单向数据流与组件间通信 上文我们已经讲述过,react 单向数据流的原理和简单模拟实现.结合上文中的代码,我们来进行这节面试题的讲解: react中的组件间通信. 那么,首先我们把看上文中的原生js代 ...
- MySQL函数--(1)
/*函数与存储过程的区别1.存储过程:可以有0个返回值,可以有多个返回值函数:有且仅有一个返回值*/ #创建语法create FUNCTION 函数名(参数列表) return 返回类型BEGIN函数 ...
- MTK刷机快捷键
彻底关机后按住音量下键,连接电脑 无法关机的情况下按住音量上+电源键,手机黑屏后松开电源键,连接电脑,出现进度条后松开音量上键
- H5软键盘兼容方案
前言 最近一段时间在做 H5 聊天项目,踩过其中一大坑:输入框获取焦点,软键盘弹起,要求输入框吸附(或顶)在输入法框上.需求很明确,看似很简单,其实不然.从实验过一些机型上看,发现主要存在以下问题: ...