django优化和扩展(一)
mysql优化基础
进行django产品开发或上线之前,有必要了解一下mysql的基础知识,orm太过抽象,导致很多朋友对于mysql了解得太少,而且orm不像sqlalchemy那样可以跟mysql走的那么近!如果要设计出合理的表结构(在orm中就是model类),显然把一个ip设置成64个字符是大大地浪费。本文结合mysql手册,做一些建表优化。
一、尽可能地使用最有效(最小)的数据类型
class Customer(models.Model):
qq = models.CharField(u"QQ号",max_length=64,unique=True)
name = models.CharField(u"姓名",max_length=32,blank=True,null=True)
phone = models.BigIntegerField(u'手机号',blank=True,null=True)
stu_id = models.CharField(u"学号",blank=True,null=True,max_length=64)
上面这个类从优化角度显然是不合理的,一个qq号占64个字符,姓名32个字符,手机号用的bigint,学号64位,一行数据得占多大空间,下面两张图写明了主要数据类型的区别!
(一)、整形列的应用
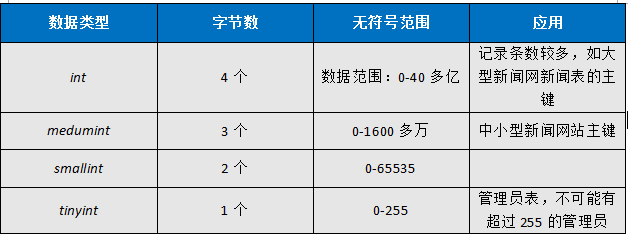
整形列的选择要慎重,一定要坚持最小化的原则,而且一定要选择无符号的整数,在orm无符号的声明如下:
class cj_user(models.Model):
cjid = models.PositiveIntegerField() # Positive 开头一般都是无符号
# 在声明非主键字段时可以如上应用,如果优化主键,必须重写AutoField,因为orm默认生成的是int类型,且是有符号的,优化方法可以参照我最后写的
(二)、char、varchar、text的区别
讲之前问2个问题:
1,char(5)和varchar(5) 能不能存下'abcdefg'?
2,char(5)和varchar(20)同样存'abcd'各占几个字符?几个字节?
()中的数字都是字符数,如果要算字节数必须utf-8*3 gbk*2,但varchar是变长,内容多少就占多少,他有一点比较特殊,varchar(20)存'abc'的时候占4个字符,因为在末尾加\0
在工作中应尽量使用定长,如char和上面的整形列 都是定长,有利加速,变长通常用一对一的形式存在附加表中,也可以综合应用,但最佳的优化还是分表存储!手机,身份证、姓名、密码都是比较固定的字段,如密码,无论设几位,最后都会被加密成32位字符串!以下是我的用户表( FixCharField是我自定义的char,因为在orm中不支持char,CharField生成的是varchar变长类型。在本文的最后我会讲一下,如何自定义!)
class hwj_user(models.Model):
xm = FixCharField(max_length=4)
tel = FixCharField(max_length=11)
sfz = FixCharField(max_length=18)
pwd = FixCharField(max_length=32)
注:varchar(max)的单位是字节即最多存65535个字节,以utf-8为例,约2万多个汉字!
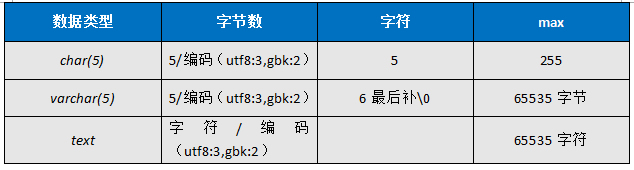
(三)主键和非空字段要用not null
手册上说:如果可能,声明列为NOT NULL。它使任何事情更快而且每列可以节省一位。这点orm中已经默认这么干了,当然这里也建议你不要把
null=True写上去
二、慎用索引
索引是会加快速度,但我觉除了主键、多对多的表无法避免外,其他都要慎用,因为索引会加快查询速度,却会降低写入速度,如果你的表有类似频繁写入的功能,如抢购等,那你就不要使用,像唯一这种都属于索引,尽量在业务中去判断他是否存在。
三、多设默认值
默认值的设置也是优化的一方面,也能使数据层避免产生错误,即便是not null的列,也应该给他设上default='',数值类型default=0等等!
四、随机排序的实现
由于orm不支持随机排序,如果要实现数据的随机排机,只能借助于python(也可以重写oder_by但太复杂了)
ids = models.Tk.objects.filter(eid_id=exam_data.id).all().values('id')
rand_id=[]
for id in ids:
rand_id.append(id["id"])
rand_num = random.sample(rand_id,5)
print(rand_num)
tks = models.Tk.objects.filter(eid_id=exam_data.id,id__in=rand_num).all()
1,先取出所有的id,把他们放到列表
2,利用random.sample 在列中随机选择5个id
3,利用orm的id__in过滤出id所在行的记录
五、自定义数据类型
class FixCharField(models.Field):
def __init__(self, *args, **kwargs):
super(FixCharField, self).__init__(*args, **kwargs) def db_type(self, connection):
return 'char(%s)' % self.max_length class hwj(models.Model):
my_field = FixCharField(max_length=25)
只是重写了,具体可看django源码
六、模板中的计数 上层循环计数
有的时候要输出上层循环的计数值,在相关书籍上也只看到当前循环{{ forloop.counter }},看了底层才知道还有forloop.parentloop.counter
以向是我模板中用反向查找实现了在题目下显示题目的方法,用嵌套循环实现的!
{% for o in tks %}
<div class="panel panel-info">
<!-- Default panel contents -->
<div class="panel-heading" name="ks{{ o.attr }}">{{ forloop.counter }}、{{ o.subject }}</div>
<div class="panel-body">
{% for i in o.op_set.all %}
<p><input type="radio" name="dx{{ forloop.parentloop.counter }}" title="{{o.answer}}" class="option-input radio" value="{{i.opstr}}"> {{i.opstr}} {{i.opname}}</p>
<p style="padding:0; margin:0; height:5px;"></p>
{% endfor %}
马上开会了,今天就写到这里。
django优化和扩展(一)的更多相关文章
- Django 优化杂谈
Django 优化杂谈 Apr 21 2017 总结下最近看过的一些文章,然后想到的一些优化点,整理一下. 数据库连接池 http://mt.dbanotes.net/arch/instagram.h ...
- Python学习---Django的request扩展[获取用户设备信息]
关于Django的request扩展[获取用户设备信息] settings.py INSTALLED_APPS = [ ... 'app01', # 注册app ] STATICFILES_DIRS ...
- Flume FileChannel优化(扩展)实践指南
本文系微博运维数据平台(DIP)在Flume方面的优化扩展经验总结,在使用Flume FileChannel的场景下将吞吐率由10M/s~20M/s提升至80M/s~90M/s,分为四个部分进行介绍: ...
- 谱聚类算法(Spectral Clustering)优化与扩展
谱聚类(Spectral Clustering, SC)在前面的博文中已经详述,是一种基于图论的聚类方法,简单形象且理论基础充分,在社交网络中广泛应用.本文将讲述进一步扩展其应用场景:首先是User- ...
- django用户信息扩展
Django封装了好多东西,拿来用就可以了,帮我们封装类用户的登录认证,用户的表 所以Django自带有用户表,当扩展用户表后一些表就会被替换 用户认证相关的 功能放在django.contri ...
- PostgreSQL 欺骗优化器之扩展统计信息
一.什么是扩展统计 扩展统计对象, 追踪指定表.外部表或物化视图的数据. 目前支持的种类: 启用n-distinct统计的 ndistinct. 启用功能依赖性统计的dependencies. 启用最 ...
- 优化与扩展Mybatis的SqlMapper解析
接上一篇博文,这一篇来讲述怎么实现SchemaSqlMapperParserDelegate——解析SqlMapper配置文件. 要想实现SqlMapper文件的解析,还需要仔细分析一下mybatis ...
- ecshop二次开发系统缓存优化之扩展数据缓存的必要性与方法
1.扩展数据缓存的必要性 大家都知道ecshop系统使用的是静态模板缓存,在后台可以设置静态模板的缓存时间,只要缓存不过期,用户访问页面就相当于访问静态页面,速度可想而知,看似非常完美,但是ecsho ...
- django优化--ORM查询
ORM提供了两个方法用来优化查询效率 1. select_related 有两张表:表结构如下: class Scheme(models.Model): """ 套餐类 ...
随机推荐
- RecyclerView 实现横向滚动效果
我相信很久以前,大家在谈横向图片轮播是时候,优先会选择具有HorizontalScrollView效果和ViewPager来做,不过自从Google大会之后,系统为我们提供了另一个控件Recycler ...
- nginx 的编译参数详解
内容有些多,一眼看来难免头昏脑胀,但坚持看完,相信你一定会有所收获. nginx参数: --prefix= 指向安装目录 --sbin-path 指向(执行)程序文件(nginx) --conf-pa ...
- Java集合之Map
Map架构: 如上图: (1)Map是映射接口,Map中存储的内容是键值对(key-value) (2)AbstractMap是继承于Map的抽象类,实现了Map中的大部分API. (3)Sorted ...
- 如何将sqlserver的windows验证模式改为SQL Server 和 Windows 混合身份验证模式
今天问同事拷贝了份虚拟机,里面已装好sqlserver2008,可是他装的时候选择的是windows身份验证,我需要将其改成SQL Server 和 Windows 混合身份验证模式,具体步骤如下: ...
- AngularJS进阶(十四)AngularJS灵异代码事件
AngularJS灵异代码事件 注:请点击此处进行充电! 事情原委 router_sys.js源代码如下: 自己在html路由跳转的代码如下: 但是在实际路由过程中,却路由到了下面的状态,相应的页面中 ...
- C++中的虚函数表是什么时期建立的?
虚函数表是在什么时期建立的? 最近参加阿里巴巴公司的内推,面试官问了“虚函数表是在什么时期建立的?”.因为以前对虚函数表的理解不够多,所以就根据程序构建(Build)的四个过程(预编译.编译.汇编和链 ...
- mysql清空表
清空某个mysql表中所有内容 delete from 表名; truncate table 表名; 不带where参数的delete语句可以删除mysql表中所有内容,使用truncate tabl ...
- DH密钥交换非对称加密
迪菲-赫尔曼密钥交换(Diffie–Hellman key exchange,简称"D–H") 是一种安全协议. 它可以让双方在完全没有对方任何预先信息的条件下通过不安全信道建立起 ...
- 机器人操作系统ROS(indigo)与三维仿真软件V-Rep(3.2.1)通信接口使用笔记
关键字:ROS(indigo),V-Rep(3.2.1), vrep_ros_bridge(lagadic). vrep_ros_bridge提供了V-Rep和ROS之间的通信接口,可以实现使用ROS ...
- python select.select模块通信全过程详解
要理解select.select模块其实主要就是要理解它的参数, 以及其三个返回值.select()方法接收并监控3个通信列表, 第一个是所有的输入的data,就是指外部发过来的数据,第2个是监控和接 ...