Kafka Producer Consumer
Producer API
org.apache.kafka.clients.producer.KafkaProducer
props.put("bootstrap.servers", "192.168.1.128:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<String, String>(props);
for (int i = 0; i < 10; i++) {
producer.send(new ProducerRecord<String, String>("foo", Integer.toString(i), Integer.toString(i)), new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (null != e) {
e.printStackTrace();
}else {
System.out.println("callback: " + recordMetadata.topic() + " " + recordMetadata.offset());
}
}
});
}
producer.close();
producer由一个缓冲池组成,这个缓冲池中维护着那些还没有被传送到服务器上的记录,而且有一个后台的I/O线程负责将这些记录转换为请求并将其传送到集群上去。
send()方法是异步的。当调用它以后就把记录放到buffer中并立即返回。这就允许生产者批量的发送记录。
acks配置项控制的是完成的标准,即什么样的请求被认为是完成了的。本例中其值设置的是"all"表示客户端会等待直到所有记录完全被提交,这是最慢的一种方式也是持久化最好的一种方式。
如果请求失败了,生产者可以自动重试。因为这里我们设置retries为0,所以它不重试。
生产者对每个分区都维护了一个buffers,其中放的是未被发送的记录。这些buffers的大小是通过batch.size配置项来控制的。
默认情况下,即使一个buffer还有未使用的空间(PS:buffer没满)也会立即发送。如果你想要减少请求的次数,你可以设置linger.ms为一个大于0的数。这个指令将告诉生产者在发送请求之前先等待多少毫秒,以希望能有更多的记录到达好填满buffer。在本例中,我们设置的是1毫秒,表示我们的请求将会延迟1毫秒发送,这样做是为了等待更多的记录到达,1毫秒之后即使buffer没有被填满,请求也会发送。(PS:稍微解释一下这段话,producer调用send()方法只是将记录放到buffer中,然后由一个后台线程将buffer中的记录传送到服务器上。这里所说的请求指的是从buffer到服务器。默认情况下记录被放到buffer以后立即被发送到服务器,为了减少请求服务器的次数,可以通过设置linger.ms,这个配置项表示等多少毫秒以后再发送,这样做是希望每次请求可以发送更多的记录,以此减少请求次数)
buffer.memory控制的是总的buffer内存数量
key.serializer 和 value.serializer表示怎样将key和value对象转成字节
从kafka 0.11开始,KafkaProducer支持两种模型:the idempotent producer and the transactional producer(幂等producer和事务producer)。幂等producer强调的是至少一次精确的投递。事务producer允许应用程序原子的发送消息到多个分区或者主题。
为了启用幂等性,必须将enable.idempotence这个配置的值设为true。如果你这样设置了,那么retries默认是Integer.MAX_VALUE,并且acks默认是all。为了利用幂等producer的优势,请避免应用程序级别的重新发送。
为了使用事务producer,你必须配置transactional.id。如果transactional.id被设置,幂等性自动被启用。
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.1.128:9092");
props.put("transactional.id", "my-transactional-id"); Producer<String, String> producer = new KafkaProducer<String, String>(props, new StringSerializer(), new StringSerializer()); producer.initTransactions(); try {
producer.beginTransaction(); for (int i = 11; i < 20; i++) {
producer.send(new ProducerRecord<String, String>("bar", Integer.toString(i), Integer.toString(i)));
}
// This method will flush any unsent records before actually committing the transaction
producer.commitTransaction();
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
producer.close();
} catch (KafkaException e) {
// By calling producer.abortTransaction() upon receiving a KafkaException we can ensure
// that any successful writes are marked as aborted, hence keeping the transactional guarantees.
producer.abortTransaction();
} producer.close();
Consumer API
org.apache.kafka.clients.consumer.KafkaConsumer
Offsets and Consumer Position
对于分区中的每条记录,kafka维护一个数值偏移量。这个偏移量是分区中一条记录的唯一标识,同时也是消费者在分区中的位置。例如,一个消费者在分区中的位置是5,表示它已经消费了偏移量从0到4的记录,并且接下来它将消费偏移量为5的记录。相对于消费者用户来说,这里实际上有两个位置的概念。
消费者的position表示下一条将要消费的记录的offset。每次消费者通过调用poll(long)接收消息的时候这个position会自动增加。
committed position表示已经被存储的最后一个偏移量。消费者可以自动的周期性提交offsets,也可以通过调用提交API(e.g. commitSync and commitAsync)手动的提交position。
Consumer Groups and Topic Subscriptions
Kafka用"consumer groups"(消费者组)的概念来允许一组进程分开处理和消费记录。这些处理在同一个机器上进行,也可以在不同的机器上。同一个消费者组中的消费者实例有相同的group.id
组中的每个消费者可以动态设置它们想要订阅的主题列表。Kafka给每个订阅的消费者组都投递一份消息。这归功于消费者组中所有成员之间的均衡分区,以至于每个分区都可以被指定到组中精确的一个消费者。假设一个主题有4个分区,一个组中有2个消费者,那么每个消费者将处理2个分区。
消费者组中的成员是动态维护的:如果一个消费者处理失败了,那么分配给它的分区将会被重新分给组中其它消费者。
在概念上,你可以把一个消费者组想象成一个单个的逻辑订阅者,并且每个逻辑订阅者由多个进程组成。作为一个多订阅系统,Kafka天生就支持对于给定的主题可以有任意数量的消费者组。
Automatic Offset Committing
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.1.128:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
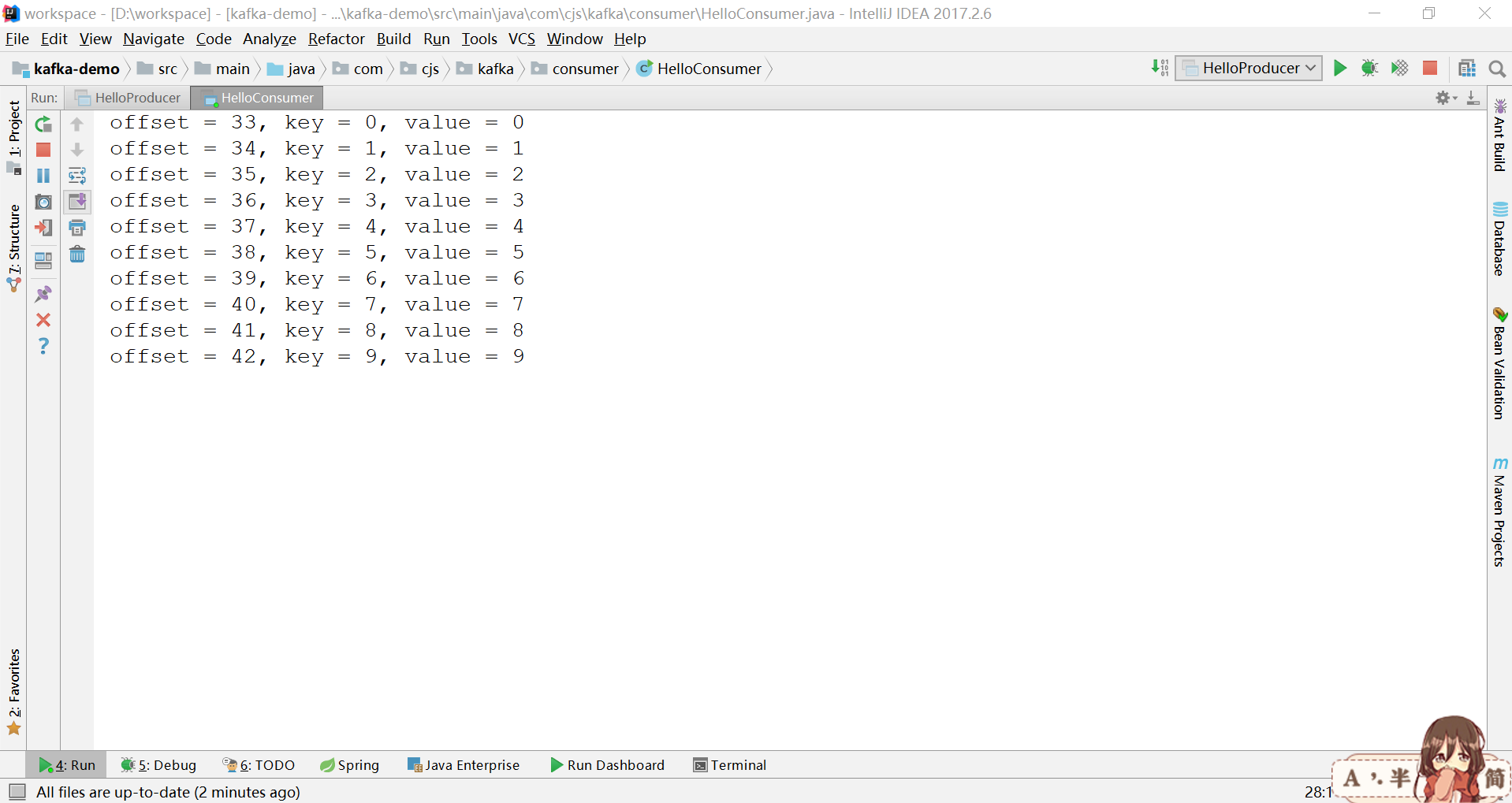
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
设置enable.auto.commit意味着自动提交已消费的记录的offset
Manual Offset Control
代替消费者周期性的提交已消费的offsets,用户可以控制什么时候记录被认为是已经消费并提交它们的offsets。
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "false");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
final int minBatchSize = 200;
List<ConsumerRecord<String, String>> buffer = new ArrayList<>();
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
buffer.add(record);
}
if (buffer.size() >= minBatchSize) {
insertIntoDb(buffer);
consumer.commitSync();
buffer.clear();
}
}
代码演示
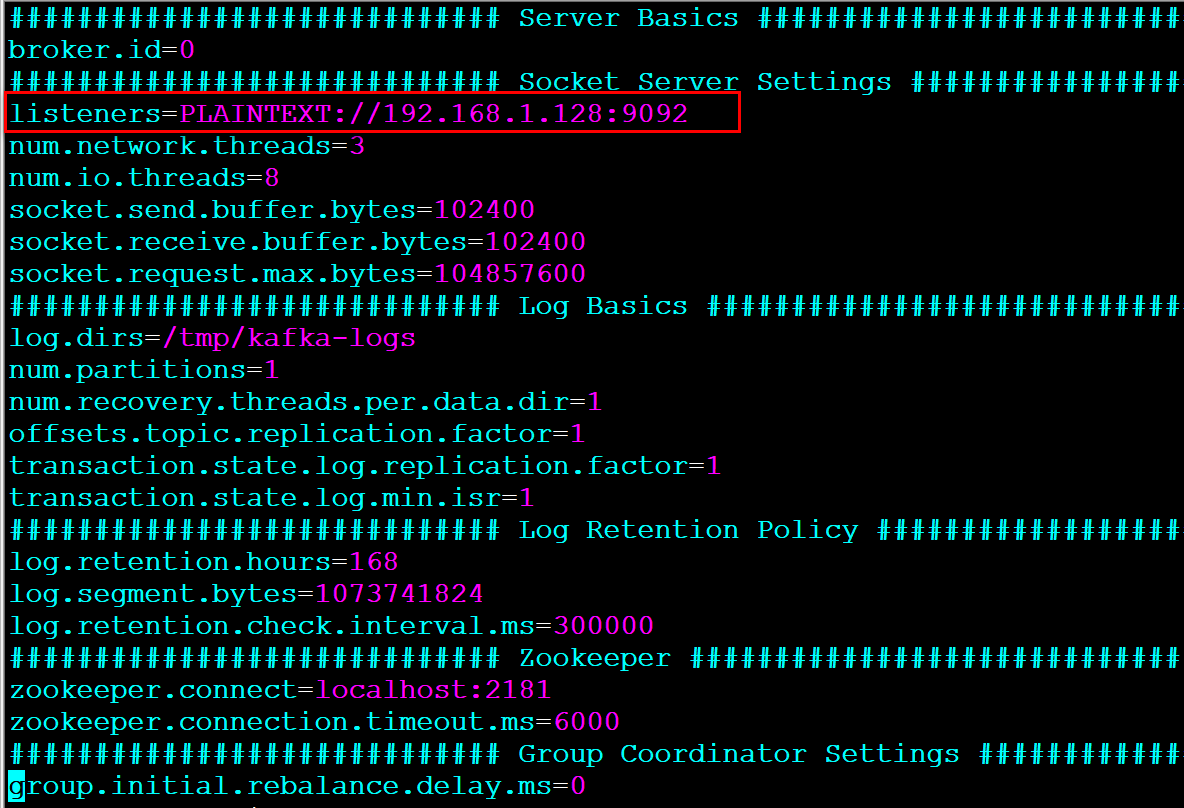
服务器端
客户端


参考
http://kafka.apache.org/10/javadoc/index.html?org/apache/kafka/clients/producer/KafkaProducer.html
http://kafka.apache.org/10/javadoc/index.html?org/apache/kafka/clients/consumer/KafkaConsumer.html
Kafka Producer Consumer的更多相关文章
- kafka producer consumer demo(三)
我们在前面把集群搭建起来了,也设置了kafka broker的配置,下面我们用代码来实现一下客户端向kafka发送消息,consumer端从kafka消费数据.大家先不要着急着了解 各种参数的配置,先 ...
- Kettle安装Kafka Consumer和Kafka Producer插件
1.从github上下载kettle的kafka插件,地址如下 Kafka Consumer地址: https://github.com/RuckusWirelessIL/pentaho-kafka- ...
- kafka producer自定义partitioner和consumer多线程
为了更好的实现负载均衡和消息的顺序性,Kafka Producer可以通过分发策略发送给指定的Partition.Kafka Java客户端有默认的Partitioner,平均的向目标topic的各个 ...
- Kafka 学习笔记之 Kafka0.11之producer/consumer(Scala)
Kafka0.11之producer/consumer(Scala): KafkaConsumer: import java.util.Properties import org.apache.kaf ...
- Kafka 学习笔记之 Producer/Consumer (Scala)
既然Kafka使用Scala写的,最近也在慢慢学习Scala的语法,虽然还比较生疏,但是还是想尝试下用Scala实现Producer和Consumer,并且用HashPartitioner实现消息根据 ...
- kafka producer源码
producer接口: /** * Licensed to the Apache Software Foundation (ASF) under one or more * contributor l ...
- 关于Kafka 的 consumer 消费者处理的一些见解
前言 在上一篇 Kafka使用Java实现数据的生产和消费demo 中介绍如何简单的使用kafka进行数据传输.本篇则重点介绍kafka中的 consumer 消费者的讲解. 应用场景 在上一篇kaf ...
- 关于Kafka java consumer管理TCP连接的讨论
本篇是<关于Kafka producer管理TCP连接的讨论>的续篇,主要讨论Kafka java consumer是如何管理TCP连接.实际上,这两篇大部分的内容是相同的,即consum ...
- Kafka producer介绍
Kafka 0.9版本正式使用Java版本的producer替换了原Scala版本的producer.本文着重讨论新版本producer的设计原理以及基本的使用方法. 新版本Producer 首先明确 ...
随机推荐
- BZOJ3109: [cqoi2013]新数独
题目:http://www.lydsy.com/JudgeOnline/problem.php?id=3109 搜索一遍.读入注意一下.. #include<cstring> #inclu ...
- Victor and World(spfa+状态压缩dp)
题目连接:http://acm.hdu.edu.cn/showproblem.php?pid=5418 Victor and World Time Limit: 4000/2000 MS (Java/ ...
- 一步一步从原理跟我学邮件收取及发送 3.telnet命令行发一封信
首先要感谢博客园管理员的及时回复,本系列的第二篇文章得以恢复到首页,这是对作者的莫大鼓励.说实在的本来我真的挺受打击的.好在管理员说只是排版上有些问题,要用代码块修饰下相关的信息.说来惭愧因为常年编码 ...
- c++(基数排序)
基数排序是另外一种比较有特色的排序方式,它是怎么排序的呢?我们可以按照下面的一组数字做出说明:12. 104. 13. 7. 9 (1)按个位数排序是12.13.104.7.9 (2)再根据十位排序1 ...
- js实现深拷贝和浅拷贝
浅拷贝: 思路----------把父对象的属性,全部拷贝给子对象,实现继承. 问题---------如果父对象的属性等于数组或另一个对象,那么实际上,子对象获得的只是一个内存地址,不会开辟新栈,不是 ...
- C++ enum用法小技巧
enum DeviceDataType :int { None = 0, SourceRGBA32 = 1, Keying = ...
- 邓_PPT
如何拯救一份丑到爆的PPT? "小邓,这是我做的PPT,你优化优化,明天早上给我,上午客户来要用." 领导,你这是PPT嘛,明明就是word嘛. "小张啊,你看看我这个P ...
- OKMX6Q LTIB编译
因为在16.04上编译有许多解决不了的错误,最后还是在飞凌的12.04虚拟机上编译的. 按照手册<OKMX6X-S2-LTIB编译手册-V1.1-2016-08-18>进行到第8步时,出现 ...
- 【开发技术】Eclipse设置软tab(用4个空格字符代替)及默认utf-8文件编码(unix)
Eclipse设置软tab(用4个空格字符代替)及默认utf-8文件编码(unix) 本文摘要: 1.如何配置Eclipse中编辑器支持softtab(用数个空格字符代替默认的tab缩进): 2.如何 ...
- NPM使用命令总结
NPM使用命令总结 npm是一个node包管理和分发工具,已经成为了非官方的发布node模块(包)的标准.有了npm,可以很快的找到特定服务要使用的包,进行下载.安装以及管理已经安装的包. 1.npm ...