Storm概念学习系列之Spout数据源
不多说,直接上干货!
Spout 数据源
消息源Spout是Storm的Topology中的消息生产者(即Tuple的创造者)。
Spout 介绍
1. Spout 的结构
Spout 是 Storm 的核心组件之一,最源头的接口是 IComponent,如图 1所示,几个Spout接口都继承自IComponent。

图 1 Spout 类图
2. Spout 发出的消息
Spout从外部获取数据后,向Topology中发出的Tuple可以是可靠的,也可以是不可靠的。
注意:一个可靠的消息源可以重新发射一个Tuple(如果该 Tuple 没有被 Storm 成功处理),但是一个不可靠的消息源Spout 一旦发出,一个Tuple 就把它彻底“遗忘”,也就不可能再发了。
3.Spout 发射的流
Spout 可以发射多个流。要达到这样的效果,使用 OutputFieldsDeclarer.declareStream 来定义多个流(即定义多个 Stream),然后使用 SpoutOutputCollector 的emit来发射指定的流。
4.Spout 的重要方法
Spout 的重要方法是 nextTuple()。 nextTuple 方法发射一个新的元组到 Topology,如果没有新元组发射,则直接返回。注意任务 Spout 的 nextTuple 方法都不要实现成阻塞的,因为Storm 是在相同的线程中调用 Spout 的方法。 Spout 的另外两个重要方法是 ack ()和 fail() 方法。当 Spout 发射的元组被拓扑成功处理时,调用 ack 方法;当处理失败时,调用 fail 方法。 ack和 fail 方法仅被可靠的 Spout 调用。
5.Spout 的组件
Spout的最顶层抽象是ISpout接口。在通常情况下(Shell和事务型的除外),实现一个Spout,可以直接实现接口IRichSpout,如果不想写多余的代码,可以直接继承BaseRichSpout。

Spout 实例
下面通过创建一个实例RandomSpout来介绍Spout, 图1为RandomSpout继承自BasicRichSpout及其实现的原理图。
图2 列出了实例 RandomSpout 继承自 BaseRichSpout 中的几个重要方法。
下面对图2 中的方法进行详细介绍。
(1) open 方法
当一个 Task 被初始化时会调用此 open 方法。一般都会在此方法中初始化发送 Tuple 的对象 SpoutOutputCollector 和配置对象 TopologyContext。
代码示例如下:

public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
random = new Random();
}

图2 RandomSpout 类图

图 3-4 RandomSpout 类的主要方法
(2) declareOutputFields 方法
此方法用于声明当前 Spout 的 Tuple 发送流。流的定义是通过 OutputFieldsDeclare.declareStream方法完成的,其中的参数包括了发送的域 Fields。
示例代码如下:

public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("randomInt"));
}
(3) nextTuple 方法
这是 Spout 类中最重要的一个方法。发射一个 Tuple 到 Topology 都是通过该方法来实现的。
示例代码如下:
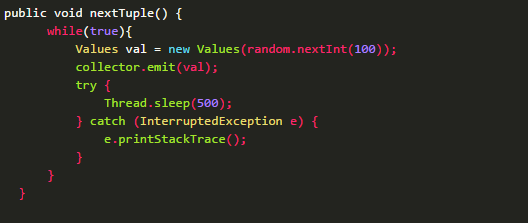
public void nextTuple() {
while(true){
Values val = new Values(random.nextInt());
collector.emit(val);
try {
Thread.sleep();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
以上代码从 100 以内的整数中随机生成一个数作为 Tuple 的值,然后通过_collector 发送到 Topology。
另外,除了上述几个方法之外,还有 getComponentConf iguration、ack、fail 和 close 方法等。 getComponentConfiguration 方法用于配置当前组件的参数, Storm 监测到一个 Tuple 被成功处理时调用 ack 方法,处理失败时调用 fail 方法,这两个方法在 BaseRichSpout 类中已经被隐式实现了。
Storm概念学习系列之Spout数据源的更多相关文章
- Storm概念学习系列之核心概念(Tuple、Spout、Blot、Stream、Stream Grouping、Worker、Task、Executor、Topology)(博主推荐)
不多说,直接上干货! 以下都是非常重要的storm概念知识. (Tuple元组数据载体 .Spout数据源.Blot消息处理者.Stream消息流 和 Stream Grouping 消息流组.Wor ...
- Storm概念学习系列之storm流程图
把stream当做一列火车, tuple当做车厢,spout当做始发站,bolt当做是中间站点!!! 见 Storm概念学习系列之Spout数据源 Storm概念学习系列之Topology拓扑 Sto ...
- Storm概念学习系列之Worker、Task、Executor三者之间的关系
不多说,直接上干货! Worker.Task.Executor三者之间的关系 Storm集群中的一个物理节点启动一个或者多个Worker进程,集群的Topology都是通过这些Worker进程运行的. ...
- Storm概念学习系列之storm的雪崩
不多说,直接上干货! Storm的雪崩问题的解决办法1: Storm概念学习系列之并行度与如何提高storm的并行度 Storm的雪崩问题的解决办法2:
- Storm概念学习系列之storm的特性
不多说,直接上干货! storm的特性 Storm 是一个开源的分布式实时计算系统,可以简单.可靠地处理大量的数据流. Storm支持水平扩展,具有高容错性,保证每个消息都会得到处理,而且处理速度很快 ...
- Storm概念学习系列 之数据流模型、Storm数据流模型
不多说,直接上干货! 数据流模型 数据流模型是由数据流.数据处理任务.数据节点.数据处理任务实例等构成的一种数据模型.本节将介绍的数据流模型如图1所示. 分布式流处理系统由多个数据处理节点(node) ...
- Storm概念学习系列之事务
不多说,直接上干货! 事务 这里的事务是专门针对Topology提出来的,是为了解决元组在处理失败重新发送后的一系列问题的.简而言之,事务拓扑(transactional topology)就是指St ...
- Storm概念学习系列之Stream消息流 和 Stream Grouping 消息流组
不多说,直接上干货! Stream消息流是Storm中最关键的抽象,是一个没有边界的Tuple序列. Stream Grouping 消息流组是用来定义一个流如何分配到Tuple到Bolt. Stre ...
- Storm概念学习系列之Topology拓扑
不多说,直接上干货! Hadoop 上运行的是 MapReduce 作业,而在 Storm 上运行的是拓扑 Topology,这两者之间是非常不同的.一个关键的区别是:一个MapReduce 作业 ...
随机推荐
- 问题:c# newtonsoft.json使用;结果:Newtonsoft.Json 用法
Newtonsoft.Json 用法 Newtonsoft.Json 是.NET 下开源的json格式序列号和反序列化的类库.官方网站: http://json.codeplex.com/ 使用方法 ...
- Java探索之旅(17)——多线程(1)
1.多线程 1.1线程 线程是程序运行的基本执行单元.指的是一段相对独立的代码,执行指定的计算或操作.多操作系统执行一个程序时会在系统中建立一个进程,而在这个进程中,必须至少建立一个线程(这个线程被 ...
- 基于OpenCV依次读取文件夹下的所有图像文件
//编程环境:VS2008+OpenCV1.1, //本程序首先挨个读取F://my face database//OnlyFace文件夹下的所有图 像 文件,之后,在项目文件夹下 //建立一 个名为 ...
- 具体问题:Spring 事务的隔离性,并说说每个隔离性的区别
使用步骤: 步骤一.在spring配置文件中引入<tx:>命名空间<beans xmlns="http://www.springframework.org/schema/b ...
- Hadoop-2.3.0-cdh5.0.1完全分布式环境搭建(NameNode,ResourceManager HA)
编写不易,转载请注明(http://shihlei.iteye.com/blog/2084711)! 说明 本文搭建Hadoop CDH5.0.1 分布式系统,包括NameNode ,Resource ...
- 使用 Chrome Timeline 来优化页面性能
使用 Chrome Timeline 来优化页面性能 有时候,我们就是会不由自主地写出一些低效的代码,严重影响页面运行的效率.或者我们接手的项目中,前人写出来的代码千奇百怪,比如为了一个 Canvas ...
- Storm在zookeeper上的目录结构
storm操作zookeeper的主要函数都定义在命名空间backtype.storm.cluster中(即cluster.clj文件中). backtype.storm.cluster定义了两个重要 ...
- 9. CTF综合靶机渗透(二)
靶机说明 Welcome to the world of Acid. Fairy tails uses secret keys to open the magical doors. 欢迎来到酸的世界. ...
- Cocos creator之javascript闭包
.什么是闭包? 闭包,官方对闭包的解释是:一个拥有许多变量和绑定了这些变量的环境的表达式(通常是一个函数),因而这些变量也是该表达式的一部分.闭包的特点: 1. 作为一个函数变量的一个引用,当函数返回 ...
- jquery事件之事件处理函数
一.事件处理 方法名 说明 语法 (events 事件类型,data数据,handler 事件处理函数,selector 选择器) Bind( 为每一个匹配元素的特定事件(像click)绑定一个事件处 ...