Spark SQL 读到的记录数与 hive 读到的不一致
问题:我用 sqoop 把 Mysql 中的数据导入到 hive,使用了--delete-target-dir --hive-import --hive-overwrite 等参数,执行了两次。 mysql 中只有 20 条记录。在 hive shell 中,查询导入到的表的记录,得到结果 20 条,是对的。

然而在 spark-shell 中,使用 spark sql 得到的结果却是 40 条。
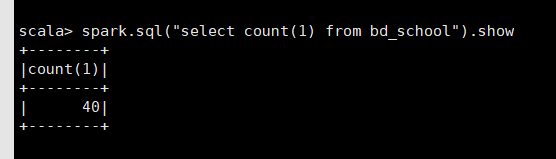
又执行了一次 sqoop 的导入,hive 中仍然查询到 20 条,而 spark shell 中却得到了 60 条!!
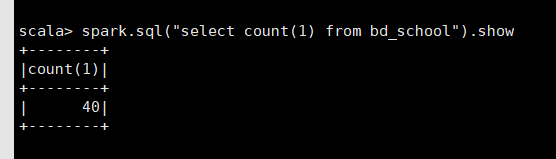
查了一下 HDFS 上,结果发现有 3 个文件
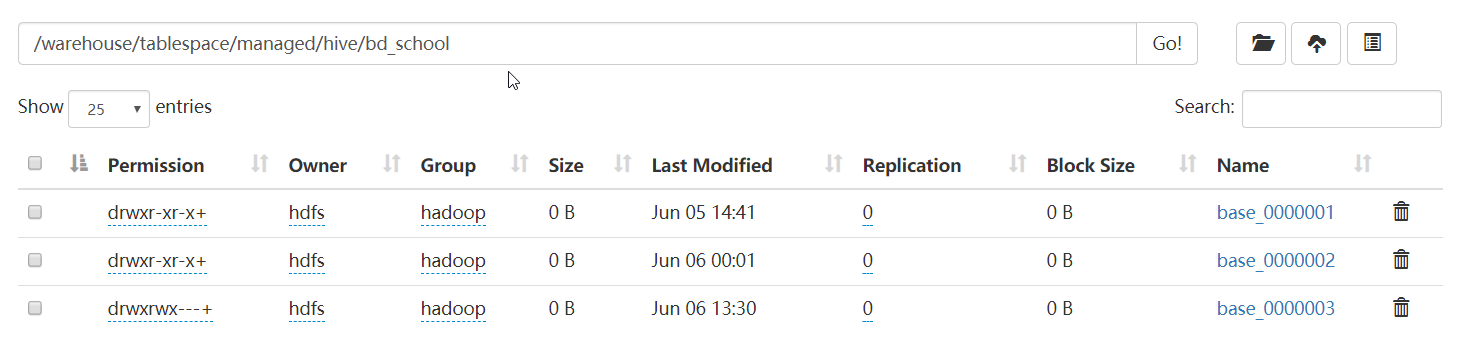
后来在网上看到有说 Hortonworks 中,用 Ambari 部署的 hive(V3.0),默认是开启 ACID 的,Spark 不支持 hive 的 ACID。更改 hive 的如下参数,关闭 ACID 功能。
hive.strict.managed.tables=false
hive.create.as.insert.only=false
metastore.create.as.acid=false
删除 hive 中的表,重新导入。
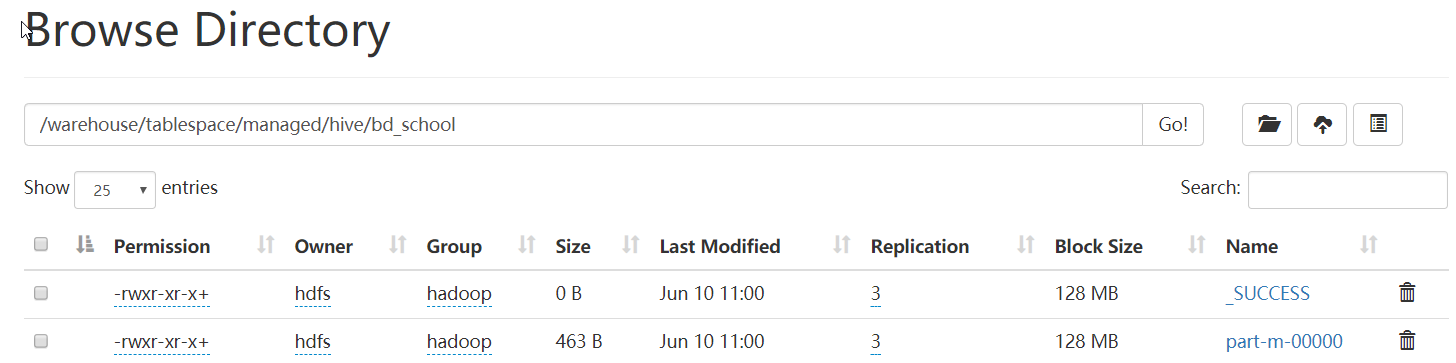
可以看到,表目录下的文件名变了,不是原来的 base_ 开头的了。
用 overwrite 的方式导入多次,也还是只有这两个文件,spark sql 读取的数据也没有出现翻倍的现象。
至此,问题算是解决了。但是不明白为什么 hive 开启 ACID 时,尽管表目录下有多个文件,但是 hive shell 能知道到底哪个是正确的,而 spark 则不知道。估计只有研究源码才能解决问题了。
Spark SQL 读到的记录数与 hive 读到的不一致的更多相关文章
- SQL Server 查询表的记录数(3种方法,推荐第一种)
http://blog.csdn.net/smahorse/article/details/8156483 --SQL Server 查询表的记录数 --one: 使用系统表. SELECT obje ...
- 【转】SQL Server 查询表的记录数(3种方法,推荐第一种)
--SQL Server 查询表的记录数 --one: 使用系统表. SELECT object_name (i.id) TableName, rows as RowCnt FROM sysindex ...
- spark SQL (五)数据源 Data Source----json hive jdbc等数据的的读取与加载
1,JSON数据集 Spark SQL可以自动推断JSON数据集的模式,并将其作为一个Dataset[Row].这个转换可以SparkSession.read.json()在一个Dataset[Str ...
- 查找 SQL SERVER 所有表记录数
-- 所有表的记录数 SELECT a.name, b.rowsFROM sysobjects AS a INNER JOIN sysindexes AS b ON a.id = b.idWHERE ...
- sqlserver sql语句查看分区记录数、查看记录所在分区
select count(1) ,$PARTITION.WorkDatePFN(workdate) from imgfile group by $PARTITION.WorkDatePFN(workd ...
- sql 查看表的记录数
select a.name as 表名,max(b.rows) as 记录条数 from sysobjects a ,sysindexes b where a.id=b.id and a.xtype= ...
- SQL 获取各表记录数的最快方法
select distinct o.name,i.rows from sysobjects o,sysindexes i where o.id=i.id and o.Xtype= 'U' and i ...
- 统计SQL Server所有表记录数
SELECT SCHEMA_NAME(t.schema_id) AS [schema] ,t.name AS tableName ,i.rows AS [rowCount] FROM sys.tabl ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
随机推荐
- 模拟Windows任务管理器CPU使用率的动态折线图-农夫山泉
Delphi的TCanvas类可以实现各种复杂的图形输出功能,基于近期项目的需求,利用它实现了一个很炫的动态折线图(模拟了资源管理器中CPU使用率的折线图),可以直观地展现出数值的实时变化情况. 这段 ...
- 分享知识-快乐自己:Maven 无法加载 Oracle 数据库驱动源
由于Oracle授权问题,Maven3不提供Oracle JDBC driver,为了在Maven项目中应用Oracle JDBC driver,必须手动添加到本地仓库. 手动添加到本地仓库需要本地有 ...
- Java中数学计算的相关方法
1:Math类 2.BigInteger类 3.BigDecimal类 BigInteger bi = new BigInteger("12433241123"); BigDec ...
- Java Modifiers
Private means this could only be seen within this class. Protected means "package private" ...
- 一步一步学RenderMonkey
http://blog.csdn.net/tianhai110/article/details/5668832 转载请注明出处:http://blog.csdn.net/tianhai110/ 网上一 ...
- Swift中数组和字典都是值类型
在 Swift 中,所有的基本类型:整数(Integer).浮点数(floating-point).布尔值(Boolean).字符串(string).数组(array)和字典(dictionary), ...
- 汇编题目:在DOS下,按F1键后改变当前屏幕的显示颜色
我们都知道int9中断是键盘的按键中断程序,按下键盘触发int9中断,不懂int9中断的请自己去百度查查说明和用法 利用中断任务安装一个新的int 9中断例程,功能:在DOS下,按F1键后改变当前屏幕 ...
- 洛谷【P1480】A/B Problem
题目传送门:https://www.luogu.org/problemnew/show/P1480 高精除低精板子题,灵性地回忆一下小学时期列竖式的草稿纸即可. 时间复杂度:\(O(len)\) 空间 ...
- Fortify代码扫描解决方案
Fortify扫描漏洞解决方案: Log Forging漏洞: 1.数据从一个不可信赖的数据源进入应用程序. 在这种情况下,数据经由getParameter()到后台. 2. 数据写入到应用程序或系统 ...
- Spring boot 学习一:认识Spring boot
什么是spring boot Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程.该框架使用了特定的方式来进行配置,从而使开发人员 ...