Spark SQL 读到的记录数与 hive 读到的不一致
问题:我用 sqoop 把 Mysql 中的数据导入到 hive,使用了--delete-target-dir --hive-import --hive-overwrite 等参数,执行了两次。 mysql 中只有 20 条记录。在 hive shell 中,查询导入到的表的记录,得到结果 20 条,是对的。

然而在 spark-shell 中,使用 spark sql 得到的结果却是 40 条。
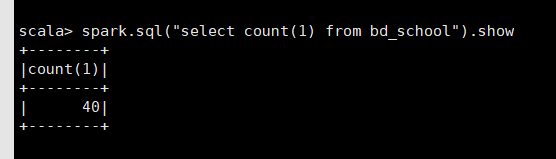
又执行了一次 sqoop 的导入,hive 中仍然查询到 20 条,而 spark shell 中却得到了 60 条!!
查了一下 HDFS 上,结果发现有 3 个文件
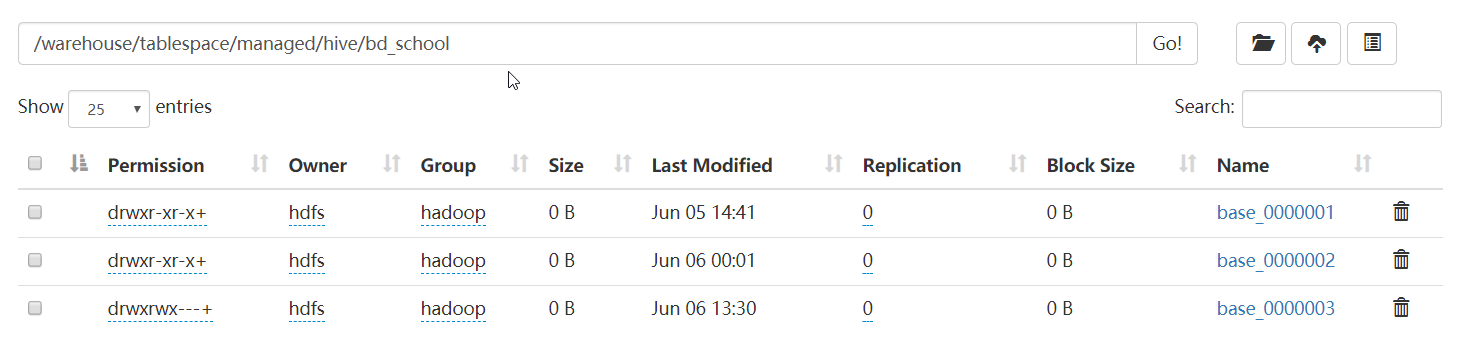
后来在网上看到有说 Hortonworks 中,用 Ambari 部署的 hive(V3.0),默认是开启 ACID 的,Spark 不支持 hive 的 ACID。更改 hive 的如下参数,关闭 ACID 功能。
hive.strict.managed.tables=false
hive.create.as.insert.only=false
metastore.create.as.acid=false
删除 hive 中的表,重新导入。
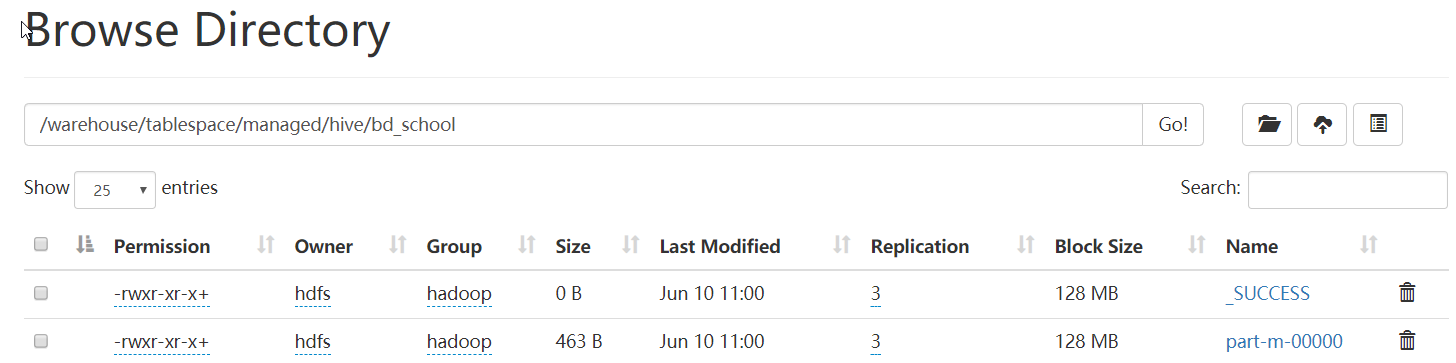
可以看到,表目录下的文件名变了,不是原来的 base_ 开头的了。
用 overwrite 的方式导入多次,也还是只有这两个文件,spark sql 读取的数据也没有出现翻倍的现象。
至此,问题算是解决了。但是不明白为什么 hive 开启 ACID 时,尽管表目录下有多个文件,但是 hive shell 能知道到底哪个是正确的,而 spark 则不知道。估计只有研究源码才能解决问题了。
Spark SQL 读到的记录数与 hive 读到的不一致的更多相关文章
- SQL Server 查询表的记录数(3种方法,推荐第一种)
http://blog.csdn.net/smahorse/article/details/8156483 --SQL Server 查询表的记录数 --one: 使用系统表. SELECT obje ...
- 【转】SQL Server 查询表的记录数(3种方法,推荐第一种)
--SQL Server 查询表的记录数 --one: 使用系统表. SELECT object_name (i.id) TableName, rows as RowCnt FROM sysindex ...
- spark SQL (五)数据源 Data Source----json hive jdbc等数据的的读取与加载
1,JSON数据集 Spark SQL可以自动推断JSON数据集的模式,并将其作为一个Dataset[Row].这个转换可以SparkSession.read.json()在一个Dataset[Str ...
- 查找 SQL SERVER 所有表记录数
-- 所有表的记录数 SELECT a.name, b.rowsFROM sysobjects AS a INNER JOIN sysindexes AS b ON a.id = b.idWHERE ...
- sqlserver sql语句查看分区记录数、查看记录所在分区
select count(1) ,$PARTITION.WorkDatePFN(workdate) from imgfile group by $PARTITION.WorkDatePFN(workd ...
- sql 查看表的记录数
select a.name as 表名,max(b.rows) as 记录条数 from sysobjects a ,sysindexes b where a.id=b.id and a.xtype= ...
- SQL 获取各表记录数的最快方法
select distinct o.name,i.rows from sysobjects o,sysindexes i where o.id=i.id and o.Xtype= 'U' and i ...
- 统计SQL Server所有表记录数
SELECT SCHEMA_NAME(t.schema_id) AS [schema] ,t.name AS tableName ,i.rows AS [rowCount] FROM sys.tabl ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
随机推荐
- spring boot: EL和资源 (一般注入说明(二) @Service注解 @Component注解)
@Service用于标注业务层组件 : 将当前类注册为spring的Bean @Controller用于标注控制层组件(如struts中的action) @Repository用于标注数据访问组件,即 ...
- Eclipse 下配置MySql5.6的连接池,使用Tomcat7.0
目前找到的最简单的配置方法. 1.首先在eclipse中创建一个Dynamical Web Application,在WebContent文件夹下的META-INF文件夹中创建新的名为conten ...
- Python—is和==
首先要知道Python中对象包含的三个基本要素,分别是:id(身份标识).type(数据类型)和value(值). ==是python运算符中的比较操作符,用来比较判断两个对象的value(值)是否相 ...
- IDEA 加载Eclipse项目
- Java钉钉开发_00_资源帖
1.源码 本系列教程的源码已上传至GitHub: https://github.com/shirayner/DingTalk_Demo 2.官方 官方源码:https://github.com/op ...
- 【BZOJ 4709】柠檬 斜率优化dp+单调栈
题意 给$n$个贝壳,可以将贝壳分成若干段,每段选取一个贝壳$s_i$,这一段$s_i$的数目为$num$,可以得到$num^2\times s_i$个柠檬,求最多能得到几个柠檬 可以发现只有在一段中 ...
- freeMarker(二)——模板开发指南之入门
学习笔记,选自freeMarker中文文档,译自 Email: ddekany at users.sourceforge.net 模板开发指南-入门 1.模板+数据模型=输出 假设在一个在线商店的应 ...
- bzoj 2969: 矩形粉刷 概率期望
题目: 为了庆祝新的一年到来,小M决定要粉刷一个大木板.大木板实际上是一个W*H的方阵.小M得到了一个神奇的工具,这个工具只需要指定方阵中两个格子,就可以把这两格子为对角的,平行于木板边界的一个子矩形 ...
- node好用的东东
supervisor 可参考: http://www.cnblogs.com/pigtail/archive/2013/01/08/2851056.html http://www.cnblogs.co ...
- sql server 2008 开启1433端口,开启远程连接
通常情况下只需要设置两处