Spark内核概述
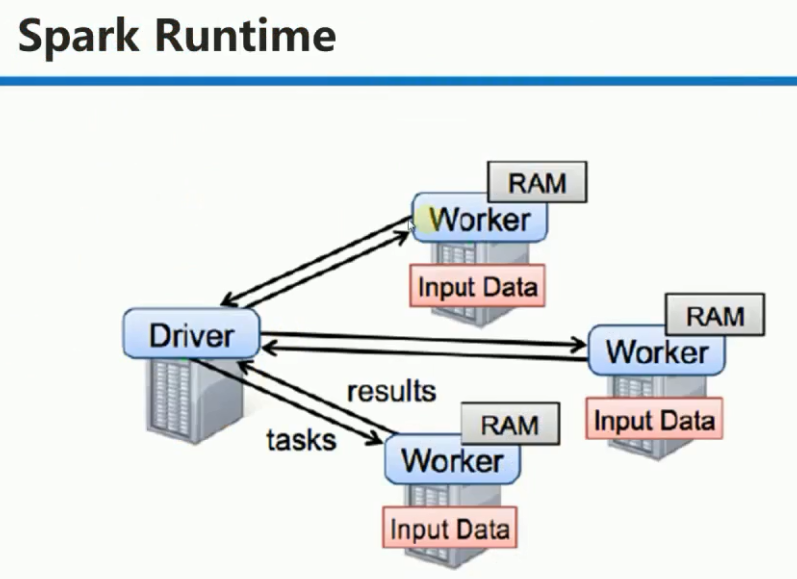

提交Spark程序的机器一般一定和Spark集群在同样的网络环境中(Driver频繁和Executors通信),且其配置和普通的Worker一致
1. Driver: 具有main方法的,初始化 SparkContext 的程序。Driver运行在提交Spark任务的机器上。
Driver 部分的代码: SparkConf + SparkContext
SparkContext: 创建DAGScheduler, TaskScheduler, SchedulerBackend, 在实例化的过程中Register当前程序给Master。 Master接
受注册,如果没有问题,Master会为当前程序分配AppId并分配计算资源
Cluster Manager:获取集群资源的外部服务。Spark应用程序的运行不依赖于Cluster Manager。
Master: 接受用户提交的程序并发送指令给Worker,让其为当前程序分配计算资源,每个Worker所在节点默认为当前程序分配一个
Executor,在Executor中通过线程池并发执行。
可以通过以下三种途径得到要为当前程序分配多少计算资源:
(1). spark-env.sh 和 spark-default.sh 中的配置信息
(2) submit 提供的参数
(3) 程序中,conf里定义的
Worker:不运行程序的代码,它管理当前节点的内存、CPU等计算资源,并接收Master的指令来分配具体的计算资源Executor(在新的进程中分配)
Worker只有在启动时才会向Master发送状态报告。
以下情况会触发Job: 1. Action 2. checkpoint 3. 排序
Spark 提交任务概述:

注意: Master 给 Worker 发送指令,要求其为Application 分配资源时,并不关心具体的资源是否已经分配。也就是说Master发指令后就记录了资源的分配,
以后其它客户端提交程序的时候就不会再分配该资源了。其弊端: 是其它要提交的程序可能分配不到本来可以分配的资源。
优势:在 Spark 分布式系统弱耦合的基础上最快的执行程序(否则如果Master要等到Worker最终分配成功后才通知 Driver的话,就会造成Driver阻塞,不
能够最大化并行计算资源的使用率)。默认情况下,Spark中的任务是排队的,也就是说同时只有一个任务在执行,所以其弊端并不明显。
Spark内核概述的更多相关文章
- 【大数据】Spark内核解析
1. Spark 内核概述 Spark内核泛指Spark的核心运行机制,包括Spark核心组件的运行机制.Spark任务调度机制.Spark内存管理机制.Spark核心功能的运行原理等,熟练掌握Spa ...
- 【Spark 内核】 Spark 内核解析-上
Spark内核泛指Spark的核心运行机制,包括Spark核心组件的运行机制.Spark任务调度机制.Spark内存管理机制.Spark核心功能的运行原理等,熟练掌握Spark内核原理,能够帮助我们更 ...
- Spark内核解析
Spark内核概述 Spark内核泛指Spark的核心运行机制,包括Spark核心组件的运行机制.Spark任务调度机制.Spark内存管理机制.Spark核心功能的运行原理等,熟练掌握Spark内核 ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
- 大数据计算平台Spark内核解读
1.Spark介绍 Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目.随着 Spark在大数据计算领域的暂露头角,越来越多 ...
- 大数据技术之_19_Spark学习_03_Spark SQL 应用解析 + Spark SQL 概述、解析 、数据源、实战 + 执行 Spark SQL 查询 + JDBC/ODBC 服务器
第1章 Spark SQL 概述1.1 什么是 Spark SQL1.2 RDD vs DataFrames vs DataSet1.2.1 RDD1.2.2 DataFrame1.2.3 DataS ...
- 大数据计算平台Spark内核全面解读
1.Spark介绍 Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目.随着Spark在大数据计算领域的暂露头角,越来越多的 ...
- 大数据技术之_19_Spark学习_04_Spark Streaming 应用解析 + Spark Streaming 概述、运行、解析 + DStream 的输入、转换、输出 + 优化
第1章 Spark Streaming 概述1.1 什么是 Spark Streaming1.2 为什么要学习 Spark Streaming1.3 Spark 与 Storm 的对比第2章 运行 S ...
- 大数据技术之_19_Spark学习_05_Spark GraphX 应用解析 + Spark GraphX 概述、解析 + 计算模式 + Pregel API + 图算法参考代码 + PageRank 实例
第1章 Spark GraphX 概述1.1 什么是 Spark GraphX1.2 弹性分布式属性图1.3 运行图计算程序第2章 Spark GraphX 解析2.1 存储模式2.1.1 图存储模式 ...
随机推荐
- Selenium-几种等待方式
强制等待 一直使用的time.sleep(5),可以放在任意地方,不好的地方,不太准确确定时间 隐形等待 driver.implicitly_wait(5) 设置了一个最长等待时间,如果在规定时间内网 ...
- hdu5612 Baby Ming and Matrix games (dfs加暴力)
Baby Ming and Matrix games Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Ja ...
- Simple Rtmp Server的安装与简单使用
Simple Rtmp Server是一个国人编写的开源的RTMP/HLS流媒体服务器. 功能与nginx-rtmp-module类似, 可以实现rtmp/hls的分发. 有关nginx-rtmp-m ...
- NOI2018网络同步赛游记
Day1 t1是一道NOI选手眼中的送分题,对于我来说还是有难度的,用了个把小时想了出来可持久化并查集的做法,最后一个点被卡常.赛后才发现Kruskal重构树是这样的简单.t2.t3由于我真的是太弱了 ...
- 关于VGG网络的介绍
本博客参考作者链接:https://zhuanlan.zhihu.com/p/41423739 前言: VGG是Oxford的Visual Geometry Group的组提出的(大家应该能看出VGG ...
- chrome中的content script脚本文件
打开chrome的devtools工具,sources下有一个Content script: 1 chrome插件开发过程中难免会遇到使用content script来操作页面的dom,在chrome ...
- Trilead,SSH2的Java调用
最近项目要部署10台设备,如果每台设备都手动进行部署想想也是醉了. 因为之前一直使用SecurityFX以及SecurityCRT,所以考虑是否可以使用基于SSH2的类库来实现文件拷贝以及远程命令调用 ...
- bzoj 4823 & 洛谷 P3756 老C的方块 —— 最小割
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=4823 https://www.luogu.org/problemnew/show/P3756 ...
- MySQL函数不能创建的解决方法(转)
在使用MySQL数据库时,有时会遇到MySQL函数不能创建的情况.下面就教您一个解决MySQL函数不能创建问题的方法,供您借鉴参考. 出错信息大致类似: ERROR 1418 (HY000): Thi ...
- fastjson 使用笔记
1.string转json String params={'key1':'50001','key2':10007700'}Map<String, String> a = JSON.pars ...