flume 配置与使用
1、下载flume,解压到自建文件夹
2、修改flume-env.sh文件
在文件中添加JAVA_HOME
3、修改flume.conf 文件(原名好像不叫这个,我自己把模板名改了)
里面我自己配的(具体配置参见 http://flume.apache.org/FlumeUserGuide.html)
agent1 是我的代理名称
source是netcat (数据源)
channel 是memory(内存)
sink是hdfs(输出)
注意配置中添加
agent1.sinks.k1.hdfs.fileType = DataStream
否则hdfs中接收的文件会出现乱码
如果要配置根据时间来分类写入hdfs的功能,要求传入的文件必须要有时间戳(datastamp)
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License. # The configuration file needs to define the sources,
# the channels and the sinks.
# Sources, channels and sinks are defined per agent,
# in this case called 'agent' agent1.sources = r1
agent1.channels = c1
agent1.sinks = k1 # For each one of the sources, the type is defined
agent1.sources.r1.type = netcat
agent1.sources.r1.channels = c1
#agent1.sources.r1.ack-every-event = false
agent1.sources.r1.max-line-length = 100
agent1.sources.r1.bind = 192.168.19.107
agent1.sources.r1.port = 44445 # Describe/configure the interceptor #agent1.sources.r1.interceptors = i1
#agent1.sources.r1.interceptors.i1.type = com.nd.bigdata.insight.interceptor.KeyTimestampForKafka$Builder # Each sink's type must be defined
#agent1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
#agent1.sinks.k1.topic = insight-test6
#agent1.sinks.k1.brokerList =192.168.181.120:9092,192.168.181.121:9092,192.168.181.66:9092
#agent1.sinks.k1.batchSize=100
#agent1.sinks.k1.requiredAcks = 0 # logger
#agent1.sinks.k1.type = logger
#agent1.sinks.k1.channel = c1 #HDFS
agent1.sinks.k1.type = hdfs
agent1.sinks.k1.channel = c1
agent1.sinks.k1.hdfs.path = test/flume/events/
agent1.sinks.k1.hdfs.filePrefix = events-
agent1.sinks.k1.hdfs.round = true
agent1.sinks.k1.hdfs.roundValue = 10
agent1.sinks.k1.hdfs.roundUnit = minute
agent1.sinks.k1.hdfs.fileType = DataStream # Each channel's type is defined.
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 1000
"flume.conf" 70L, 2291C
4、启动flume:(文件根目录下启动)
bin/flume-ng agent --conf conf --conf-file conf/flume.conf --name agent1 -Dflume.root.logger=INFO,console(里面的flume.conf ,agent1 请替换成你自己的名字)
5、用另一台机试着发送文件
telnet 192.168.19.107 44445 (创建连接)
然后发送内容
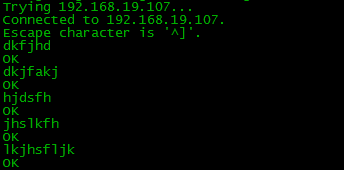
6、生成的hdfs文件

flume 配置与使用的更多相关文章
- 关于flume配置加载(二)
为什么翻flume的代码,一方面是确实遇到了问题,另一方面是想翻一下flume的源码,看看有什么收获,现在收获还谈不上,因为要继续总结.不够已经够解决问题了,而且确实有好的代码,后续会继续慢慢分享,这 ...
- flume 配置
[root@dtpweb data]#tar -zxvf apache-flume-1.7.0-bin.tar.gz[root@dtpweb conf]# cp flume-env.sh.templa ...
- 关于flume配置加载
最近项目在用到flume,因此翻了下flume的代码, 启动脚本: nohup bin/flume-ng agent -n tsdbflume -c conf -f conf/配置文件.conf -D ...
- Flume配置Replicating Channel Selector
1 官网内容 上面的配置是r1获取到的内容会同时复制到c1 c2 c3 三个channel里面 2 详细配置信息 # Name the components on this agent a1.sour ...
- Flume配置Multiplexing Channel Selector
1 官网内容 上面配置的是根据不同的heder当中state值走不同的channels,如果是CZ就走c1 如果是US就走c2 c3 其他默认走c4 2 我的详细配置信息 一个监听http端口 然后 ...
- hadoop生态搭建(3节点)-09.flume配置
# http://archive.apache.org/dist/flume/1.8.0/# ===================================================== ...
- flume配置和说明(转)
Flume是什么 收集.聚合事件流数据的分布式框架 通常用于log数据 采用ad-hoc方案,明显优点如下: 可靠的.可伸缩.可管理.可定制.高性能 声明式配置,可以动态更新配置 提供上下文路由功能 ...
- flume配置参数的意义
1.监控端口数据: flume启动: [bingo@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file jo ...
- Flume配置Failover Sink Processor
1 官网内容 2 看一张图一目了然 3 详细配置 source配置文件 #配置文件: a1.sources= r1 a1.sinks= k1 k2 a1.channels= c1 #负载平衡 a1.s ...
随机推荐
- 【python】-- web开发之HTML
HTML HTML是英文Hyper Text Mark-up Language(超文本标记语言)的缩写,是一种制作万维网页面标准语言(标记).通俗的讲就是相当于定义统一的一套规则,大家都来遵守他,这样 ...
- 【python】-- web开发之jQuery
jQuery jQuery 是一个 JavaScript 函数库,jQuery库包含以下特性(HTML 元素选取.HTML 元素操作.CSS 操作.HTML 事件函数.JavaScript 特效和动画 ...
- windows下安装PyQt4
第一步:确认自己电脑上的Python版本.然后下载对应的.whl文件下载 第二步:https://www.lfd.uci.edu/~gohlke/pythonlibs/#pyqt4上下载对应版本版本的 ...
- linux c编程:进程控制(一)
一个进程,包括代码.数据和分配给进程的资源.fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程, 也就是两个进程可以做完全相同的事,但如果初始参数或者传入的变量不同,两个进程也可以做不同 ...
- 保护眼睛,win7家庭版如何修改窗口的背景颜色
win7的窗口背景色为白色,长时间使用电脑对眼睛的刺激比较大,为了保护眼睛建议改成浅灰色或者淡绿.淡黄色等,可是win7的家庭版里没有[个性化]菜单,那么我们如何修改呢? 首先在[开始]处找到[控制面 ...
- STM32L0 HAL库 TIM定时1s
STM32L0的定制器资源: 本实验使用TIM6 HSI频率是16Mhz,则单指令周期是1/16Mhz 预分频设置为1600,则每跑1600下,定时器加1,相当于定时器加1的时间是1600*(1/16 ...
- 3.26课·········window.document对象
1.Window.document对象 一.找到元素: docunment.getElementById("id"):根据id找,最多找一个: var a =docun ...
- js实现select动态添加option
关于 select 的添加 option 应该注意的问题. 标准的做法如上也就是说,标准的做法是 s.options.add();但是如果你一定要用 s.appendChild(option);注意了 ...
- spring boot项目使用swagger-codegen生成服务间调用的jar包
swagger-codegen的github:https://github.com/swagger-api/swagger-codegen 需要的环境:jdk > 1.7 maven > ...
- DEV开发之控件XtraTabbedMdiManager
使用的时候要先设置窗体的IsMdiZContainer属性为True然后再窗体上新增XtraTabbedMdiManager控件 设置属性:HeaderLocation为bottomClosePage ...