python库-urllib
urllib库提供了一系列操作url的功能,是python处理爬虫的入门级工具,网上的学习资料也很多。我做爬虫是一开始就用了Scrapy框架,并不是一步步从urllib开始的,反而是在后来解决一些小问题的时候用到了urllib库,感觉用起来很简洁也很实用,下面是我最近的一些应用总结。
1、urllib和urllib2
在python2.x的版本中有urllib和urllib2两个库,为什么这样我也没有好好去调研。两者能处理的问题有些相交,更多的是不同,在我的应用场景中,一个最重要的区别就是通过urllib2的方法可以修改header信息,而urllib不支持,后边的例子可以看到。
在python3的版本中,已经没有urllib2了,版本2中的urllib和urllib2合并在了一起,urllib自然也就支持修改头部信息
下面这两段代码是python2和python3的使用情况对比
import urllib2
req=urllib2.Request('https://www.python.org/')
req.add_header('Range','bytes=0-20')
res=urllib2.urlopen(req)
data=res.read().decode('utf-8')
print data
python3:
from urllib import request
req=request.Request("https://www.python.org/")
req.add_header('Range','bytes=0-20')
res=request.urlopen(req) res.read().decode('utf-8')
2、应用urllib爬取页面信息的完整小案例(python2)
我理解的整个爬虫的过程就是首先下载网页,然后对网页进行解析提取需要的数据,最后数据入库或者是文件等等。上面的代码已经将网页下载下来了,只不过由于修改了Range信息,所以只下载了网页的一部分。
下面的例子就是如何解析网页,我之前关于Scrapy的博客用到了Xpath的方式,下面这个例子是用的正则,其实解析网页就没有urllib什么事了...
豆瓣电影中排名前170名电影的得分之和:我用的urllib库,用urllib2也是可以的
import urllib
import re
ll=[]
for i in range(7):
url='http://movie.douban.com/top250?start'+str(i*25)
req=urllib.urlopen(url)
page=req.read()
reg='<span class="rating_num" property="v:average">([0-9]+.[0-9]+)</span>'
regc=re.compile(reg)
res=regc.findall(page)
ll.extend(res)
sum=0
for i in range(170):
sum+=float(ll[i])
print sum
3、应用urllib2发送get和post请求(python2)
get和post最简单的理解就是,get是把请求信息附加到url里,而post则是通过表单
(1)查看请求参数——看url,可以从网址栏看,也可以通过开发者工具看
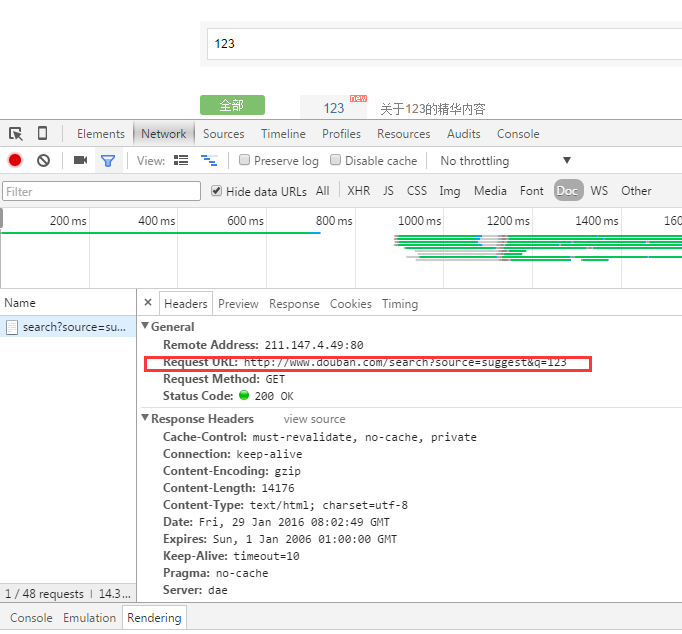
或者从,参数列表看:
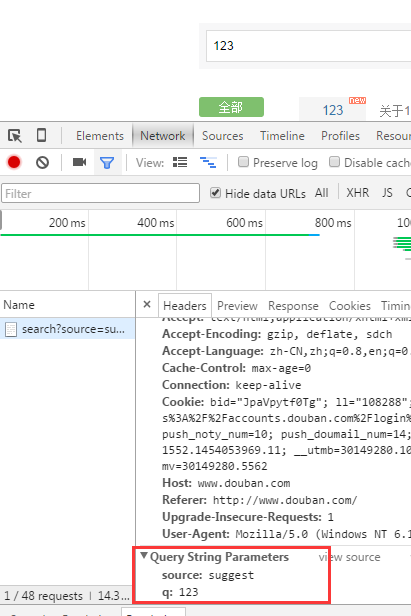
(2)get方式----把参数附加到url即可
import urllib2
url='http://www.douban.com/search?source=suggest&q=123'
req=urllib2.Request(url)
(3)post方式
import urllib
import urllib2
url="http://www.douban.com/search"
data={'source':'suggest','q':''}
data=urllib.urlencode(data) # 编码成url的格式
req=urllib2.Request(url=url,data=data)
4、爬虫真的很好玩~~
最后再说点有意思的,本人也是有喜欢的小明星哒,网上那么多的美图下也下不过来,肿么办呢?写个爬虫吧哈哈~前几天逛贴吧看美图突发奇想写个小爬虫,追星学习两不误呢~
import re
import urllib def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' % x)
x = x + 1 html = getHtml("http://tieba.baidu.com/p/..........?pn=1") #改一下参数
getImg(html)
python库-urllib的更多相关文章
- python爬虫 - Urllib库及cookie的使用
http://blog.csdn.net/pipisorry/article/details/47905781 lz提示一点,python3中urllib包括了py2中的urllib+urllib2. ...
- Python爬虫Urllib库的高级用法
Python爬虫Urllib库的高级用法 设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Head ...
- Python爬虫Urllib库的基本使用
Python爬虫Urllib库的基本使用 深入理解urllib.urllib2及requests 请访问: http://www.mamicode.com/info-detail-1224080.h ...
- Python爬虫--Urllib库
Urllib库 Urllib是python内置的HTTP请求库,包括以下模块:urllib.request (请求模块).urllib.error( 异常处理模块).urllib.parse (url ...
- python之urllib库
urllib库 urllib库是Python中一个最基本的网络请求库.可以模拟浏览器的行为,向指定的服务器发送一个请求,并可以保存服务器返回的数据. urlopen函数: 在Python3的urlli ...
- python 之 Urllib库的基本使用
目录 python 之 Urllib库的基本使用 官方文档 什么是Urllib urlopen url参数的使用 data参数的使用 timeout参数的使用 响应 响应类型.状态码.响应头 requ ...
- Python使用urllib,urllib3,requests库+beautifulsoup爬取网页
Python使用urllib/urllib3/requests库+beautifulsoup爬取网页 urllib urllib3 requests 笔者在爬取时遇到的问题 1.结果不全 2.'抓取失 ...
- python中urllib, urllib2,urllib3, httplib,httplib2, request的区别
permike原文python中urllib, urllib2,urllib3, httplib,httplib2, request的区别 若只使用python3.X, 下面可以不看了, 记住有个ur ...
- python:利用urllib查找计算机二级准考证号
aaarticlea/png;base64,iVBORw0KGgoAAAANSUhEUgAAAaYAAAEACAIAAAB3VkWnAAAgAElEQVR4nOydZ3gUR9bv+WhExhHnDH
随机推荐
- hihoCoder#1698 : 假期计划 组合数
题面:hihoCoder#1698 : 假期计划 组合数 题解: 题目要求是有序的排列,因此我们可以在一开始就乘上A!*B!然后在把这个序列划分成很多段. 这样的话由于乘了阶乘,所以所有排列我们都已 ...
- 【bzoj2743】[HEOI2012]采花 树状数组
题目描述 萧芸斓是Z国的公主,平时的一大爱好是采花. 今天天气晴朗,阳光明媚,公主清晨便去了皇宫中新建的花园采花.花园足够大,容纳了n朵花,花有c种颜色(用整数1-c表示),且花是排成一排的,以便于公 ...
- UVA.540 Team Queue (队列)
UVA.540 Team Queue (队列) 题意分析 有t个团队正在排队,每次来一个新人的时候,他可以插入到他最后一个队友的身后,如果没有他的队友,那么他只能插入到队伍的最后.题目中包含以下操作: ...
- 【逆序对相关/数学】【P1966】【NOIP2013D1T2】 火柴排队
传送门 Description 涵涵有两盒火柴,每盒装有 $n$ 根火柴,每根火柴都有一个高度. 现在将每盒中的火柴各自排成一列, 同一列火柴的高度互不相同, 两列火柴之间的距离定义为:$ \sum ...
- Spring3 MVC 深入核心研究
[转载自 http://elf8848.iteye.com/blog/875830] 目录: 一.前言 二.核心类与接口 三.核心流程图 四.DispatcherServlet说明 五.双亲上下文的说 ...
- HDU4612:Warm up(缩点+树的直径)
Warm up Time Limit: 10000/5000 MS (Java/Others) Memory Limit: 65535/65535 K (Java/Others)Total Su ...
- ACM2066
题目原址:http://acm.hdu.edu.cn/showproblem.php?pid=2066 大神必须飘过,我在这个题目里面学到了太多太多了.我提交了十六次,错了十二次,反复了这么久才解决内 ...
- HDU3666 差分约束
THE MATRIX PROBLEM Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Other ...
- web开发环境和要求配置
对于eclipse,有很多版本,但要开发WEB程序,需要用到j2ee版本,如果是winform或android 用不带ee的版本就行,两者的明显区别是在看帮助->关于->Eclipse J ...
- 问题03.如果有多个集合的迭代处理情况【使用MAP】
在SQL开发过程中,动态构建In集合条件查询是比较常见的用法,在Mybatis中提供了foreach功能,该功能比较强大,它允许你指定一个集合,声明集合项和索引变量,它们可以用在元素体内.它也允许你指 ...