[HDFS Manual] CH6 HDFS Federation
HDFS Federation
1 Background
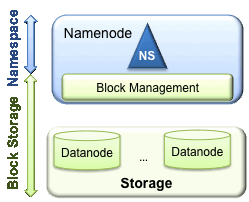
HDFS主要有2层
· Namespace
o 由目录,文件和块组成
o 支持所有namespace相关的文件系统操作,create,delete,modify和查看文件和目录
· Block 存储服务
o Block管理
§ 提供datanode clusterc成员,通过注册和定期心跳控制。
§ 处理block report并且维护block位置。
§ Block的相关操作,比如创建,修改,删除和获取block位置。
§ 管理副本位置,block复制,如果超出删除block副本。
o Storage 用来提供保存block,保存在本地文件系统,允许读写访问。
之前的HDFS体系结构允许一个namespace。在这个配置,一个namenode管理namespace。HDFS联合支持多个namenode,namespace。
2.多个namenode/namespace
为了水平扩展name service,联合使用多个独立的namenode/namespace。Namenode是联合的,独立的不需要互相协助。Datanode作为通用存储来保存所有的namenode的block。每个datanode会在所有的namenode中注册。Datanode定期的发送心跳和block report。也处理来自namenode 的命令。
用户使用ViewFS来创建个人的namespace view。ViewFs客户端的mount table一样。
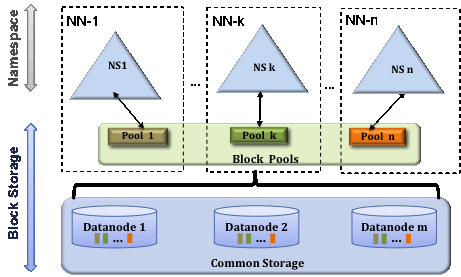
Block Pool
Block pool是属于一个namespace的block集合。Datanode保存了所有cluster的block pool的block。每个block pool都是独立的。不需要其他namespace协助,允许一个namespace生成一个新的block id。一个Namenode错误不会阻止datanode为其他namenode服务。
Namespace和block pool一起称为NameSpace Volume。是一个管理单元。当namenode/namespace被删除,相关的block pool也会被删除。当集群升级,每个namespace volume也是作为一个单元被更新的。
ClusterID
ClusterID用来标识cluster中所有的node。当namenode被格式化,标识符可以提供也可以自动生成。这个ID需要用来格式化其他namenode。
2.1 关键好处
· Namespace扩展联合增加了namespace的水平扩展。大的部署或者大量小文件的集群可以通过增加namenode获得好处。
· 性能文件系统吞吐不会被单个namenode限制。另外增加namenode会扩展文件系统的读写吞吐量。
· 隔离单个namenode不会对用户进行隔离。比如,一个应用overload namenode会导致其他应用性能下降。使用多个namenode,不同的应用分类,可以隔离到不同的namenode上。
3 联合配置
联合配置是向后兼容的并且允许已经存在的单个namenode配置,不需要其他修改。新的配置被设计用来所有的node都可以使用一样的配置,不需要node不同的配置。
联合增加了一个新的NameServiceID。Namnode和相关的secondary/backup/checkpointer node都属于一个nameserviceid。为了支持一个配置文件,namenode和secondary/backup/checkpointer node使用nameserviceid前缀。
3.1 配置
步骤1:增加dfs.nameservices参数来配置使用逗号分隔。被datanode使用来决定cluster中的namenode。
步骤2:对于每个namenode和secondary/backup/checkpointer node增加以下配置使用nameserviceid作为前缀:
|
Daemon |
Configuration Parameter |
|
Namenode |
dfs.namenode.rpc-address |
|
Secondary Namenode |
dfs.namenode.secondary.http-address |
|
BackupNode |
dfs.namenode.backup.address |
配置例子:
3.2 格式化namenode
步骤1:格式化namenode使用以下命令:
[hdfs]$ $HADOOP_HOME/bin/hdfs namenode -format [-clusterId <cluster_id>]
选择一个文艺的clusterid不能和环境中的其他cluster冲突。如果cluster_id不提供会自动生成一个唯一的cluster_id。
步骤2:格式化其他namenode:
[hdfs]$ $HADOOP_HOME/bin/hdfs namenode -format -clusterId <cluster_id>
注意这里的clusterid要和上面的clusterid一样。如果不同,另外的namenode不是联合集群的一部分。
3.3 更新老的release并且配置联合
老的release只支持一个namenode。更新cluster到新的release并且提供一个clusterid:
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon start namenode -upgrade -clusterId
<cluster_ID>
如果没有提供会自动生成。
3.4 增加新的namenode到已经存在的cluster
步骤如下:
·
增加dfs.nameservices配置
·
使用nameserviceid前缀来更新配置。
·
增加一个新的namenode。
·
把配置文件发到所有的node
·
启动新的namenode和secondary/backup
·
刷新datanode获取新的namenode:
[hdfs]$ $HADOOP_HOME/bin/hdfs dfsadmin -refreshNamenodes <datanode_host_name>:<datanode_rpc_port>
4 管理集群
4.1 启动和关闭集群
启动集群命令:
[hdfs]$ $HADOOP_HOME/sbin/start-dfs.sh
关闭集群命令:
[hdfs]$ $HADOOP_HOME/sbin/stop-dfs.sh
这个命令可以集群中的任何节点运行。命令使用配置决定集群的namenode,然后在这些node启动namenode进程。Workfile 中的node 启动Datanode。可以参考这个脚本设计自己的脚本来启动和关闭集群。
4.2 均衡器
均衡器因为要运行在多个namenode被改变。均衡器可以使用以下方法启动:
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon start balancer [-policy <policy>]
Policy参数有2个:
·
Datanode 这个是默认的策略,均衡datanode级别的存储。和以前差不多。
·
Blockpool会均衡blockpool级别,也会均衡datanode级别。
注意均衡器只会均衡data不会均衡namespace。
4.3 停止运行
停止运行和之前的类似,node需要被停运的,会增加到exclude文件中。当一个datanode中的所有namenode都停运,那么datanode被认为停运了。
步骤1:复制exclude文件到所有的namenode,并执行一下命令:
[hdfs]$ $HADOOP_HOME/sbin/distribute-exclude.sh <exclude_file>
步骤2:刷新所有的namenode,获取新的exclude文件的内容:
[hdfs]$ $HADOOP_HOME/sbin/refresh-namenodes.sh
上面的命令使用HDFS配置来决定cluster的namenode并且刷新exclude文件。
4.4 Cluster Web Console
和namenode状态web page相似,当使用联合可以使用cluster web Console可以通过http://<any_nn_host:port>/dfsclusterhealth.jsp监控联合cluster。任何cluster中的namenode都可以在这个web中访问。
这个Cluster Web
Console提供以下信息:
·
Cluster summary显示了文件个数,block个数,总配置的存储容量和可用的,已经使用的存储。
·
列出namenode,summaryb包括文件个数,block,丢失的block和live和dead datanode。这个可以通过namenode的web UI访问。
·
停止运行的datanode。
[HDFS Manual] CH6 HDFS Federation的更多相关文章
- [HDFS Manual] CH3 HDFS Commands Guide
HDFS Commands Guide HDFS Commands Guide 3.1概述 3.2 用户命令 3.2.1 classpath 3.2.2 dfs 3.2.3 envvars 3.2.4 ...
- [HDFS Manual] CH2 HDFS Users Guide
2 HDFS Users Guide 2 HDFS Users Guide 2.1目的 2.2.概述 2.3.先决条件 2.4. Web Interface 2.5. Shell Command 2. ...
- [HDFS Manual] CH1 HDFS体系结构
v\:* {behavior:url(#default#VML);} o\:* {behavior:url(#default#VML);} w\:* {behavior:url(#default#VM ...
- [HDFS Manual] CH4 HDFS High Availability Using the Quorum Journal Manager
HDFS High Availability Using the Quorum Journal Manager HDFS High Availability Using the Quorum Jour ...
- [HDFS Manual] CH8 HDFS Snapshots
HDFS Snapshots HDFS Snapshots 1. 概述 1.1 Snapshottable目录 1.2 快照路径 2. 带快照的更新 3. 快照操作 3.1 管理操作 3.2 用户操作 ...
- 【hadoop】python通过hdfs模块读hdfs数据
hdfs官网:http://hdfscli.readthedocs.io/en/latest/api.html 一个非常好的博客:http://blog.csdn.net/gamer_gyt/arti ...
- HDFS之四:HDFS原理解析(总体架构,读写操作流程)
前言 HDFS 是一个能够面向大规模数据使用的,可进行扩展的文件存储与传递系统.是一种允许文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和 存储空间.让实际上是通过网络来访问文件 ...
- Hadoop之hadoop fs和hdfs dfs、hdfs fs三者区别
适用范围 案例 备注 小记 hadoop fs 使用范围最广,对象:可任何对象 hadoop dfs 只HDFS文件系统相关 hdfs fs 只HDFS文件系统相关(包括与 ...
- [HDFS Manual] CH7 ViewFS Guide
ViewFS Guide ViewFS Guide 1 介绍 2. The Old World(Prior to Federation) 2.1单个Namenode Clusters 2.2 路径使用 ...
随机推荐
- javascript闭包和this对象
闭包(closure)是Javascript语言的一个难点,也是它的特色,很多高级应用都要依靠闭包实现. 一.变量的作用域 要理解闭包,首先必须理解Javascript特殊的变量作用域. 变量的作用域 ...
- SpringBoot集成阿里巴巴Druid监控
druid是阿里巴巴开源的数据库连接池,提供了优秀的对数据库操作的监控功能,本文要讲解一下springboot项目怎么集成druid. 本文在基于jpa的项目下开发,首先在pom文件中额外加入drui ...
- Jmeter测试http+JSON配置相关
1.添加HTTP信息头管理器 Content-Type application/json Accept application/json 2.添加http请求(方法.编码.路径.body)
- RFID的winform程序心得2
RFID的winform程序心得1 webBrowser1.AllowWebBrowserDrop = false;//将 WebBrowser 控件的 AllowWebBrowserDrop 属性设 ...
- 潭州课堂25班:Ph201805201 django框架 第八课 表关联对象方法add,create,remove,clear,多表查询 (课堂笔记)
查表: 数据的插入 新建添加 删除 清空
- 潭州课堂25班:Ph201805201 django框架 第二课 url,,include,kwargs,name的使用 (课堂笔记)
url 路由配置 这里的 name 由用户输入,得到参数 /<>/是获取用户输入值 这里的 name 默认接收的是 str 如果要接收 int 时: 当输入参数非数字时提示错误 最常用是 ...
- 如何使用TDD和React Testing Library构建健壮的React应用程序
如何使用TDD和React Testing Library构建健壮的React应用程序 当我开始学习React时,我努力的一件事就是以一种既有用又直观的方式来测试我的web应用程序. 每次我想测试它时 ...
- java加载类的顺序
一.什么时候会加载类?使用到类中的内容时加载:有三种情况1.创建对象:new StaticCode();2.使用类中的静态成员:StaticCode.num=9; StaticCode.show() ...
- 通过xml处理sql语句时对小于号与大于号的处理转换
以上方法,很容易使用,直接ss < #{ss} 法二 <![CDATA[>=]]>表示大于等于 变量<![CDATA[ < ]]>#{变量}表示 ...
- Spring使用原生JDBC
Spring使用原生JDBC 为加深对Spring解耦的理解,本次实验学习用Spring连接JDBC 一.POM配置文件 pom.xml <project xmlns="http:// ...