TensorFlow中的优化算法
搭建好网络后,常使用梯度下降类优化算法进行模型参数求解,模型越复杂我们在训练神经网络的过程上花的时间就越多,为了解决这一问题,我们就需要找一些优化算法来提高训练速度,TF的tf.train模块中提供了丰富的优化算法,这一节对这些优化器做下简单的对比。
Stochastic Gradient Descent(SGD)
最基础的方法就是GD了,将整个数据集放入模型中,不断的迭代得到模型的参数,当然这样的方法计算资源占用的比较大,那么有没有什么好的解决方法呢?就是把整个数据集分成小批(mini-batch),然后再进行上述操作这就是SGD了,这种方法虽然不能反应整体的数据情况,不过能够很大程度上加快了模型的训练速度,并且也不会丢失太多的准确率
参数的迭代公式
\(w:=w-\alpha*dw\)
Momentum
传统的GD可能会让学习过程十分的曲折,这里我们引入了惯性这一分量,在朝着最优点移动的过程中由于惯性走的弯路会变少
\(m=\beta*m-\alpha*dw\)
\(w:=w-m\)
AdaGrad
这个方法主要是在学习率上面动手脚,每个参数的更新都会有不同的学习率
\(s=s+dw^2\)
\(w:=w-\alpha*dw/\sqrt{s}\)
RMSProp
AdaGrad收敛速度快,但不一定是全局最优,为了解决这一点,加入了Momentum部分
\(s=\beta*s+(1-\beta)dw^2\)
\(w:=w-\alpha*dw/\sqrt{s}\)
Adam
adam是目前比较好的方法,它融合了Momentum和RMSProp方法

代码示例
下面部分使用TF来比较一下这些方法的效果
# -*- coding: utf-8 -*-
"""
@author: VasiliShi
"""
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
def reset_graph(seed=42):
tf.reset_default_graph()
tf.set_random_seed(seed)
np.random.seed(seed)
reset_graph()
plt.figure(1,figsize=(10,8))
x = np.linspace(-1,1,100)[:,np.newaxis] #<==>x=x.reshape(100,1)
noise = np.random.normal(0,0.1,size = x.shape)
y=np.power(x,2) + x +noise #y=x^2 + x+噪音
plt.scatter(x,y)
plt.show()
learning_rate = 0.01
batch_size = 10 #mini-batch的大小
class Network(object):
def __init__(self,func,**kwarg):
self.x = tf.placeholder(tf.float32,[None,1])
self.y = tf.placeholder(tf.float32,[None,1])
hidden = tf.layers.dense(self.x,20,tf.nn.relu)
output = tf.layers.dense(hidden,1)
self.loss = tf.losses.mean_squared_error(self.y,output)
self.train = func(learning_rate,**kwarg).minimize(self.loss)
SGD = Network(tf.train.GradientDescentOptimizer)
Momentum = Network(tf.train.MomentumOptimizer,momentum=0.5)
AdaGrad = Network(tf.train.AdagradOptimizer)
RMSprop = Network(tf.train.RMSPropOptimizer)
Adam = Network(tf.train.AdamOptimizer)
networks = [SGD,Momentum,AdaGrad,RMSprop,Adam]
record_loss = [[], [], [], [], []] #踩的坑不能使用[[]]*5
plt.figure(2,figsize=(10,8))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for stp in range(200):
index = np.random.randint(0,x.shape[0],batch_size)#模拟batch
batch_x = x[index]
batch_y = y[index]
for net,loss in zip(networks,record_loss):
_,l = sess.run([net.train,net.loss],feed_dict={net.x:batch_x,net.y:batch_y})
loss.append(l)#保存每一batch的loss
labels = ['SGD','Momentum','AdaGrad','RMSprop','Adam']
for i,loss in enumerate(record_loss):
plt.plot(loss,label=labels[i])
plt.legend(loc="best")
plt.xlabel("steps")
plt.ylabel("loss")
plt.show()
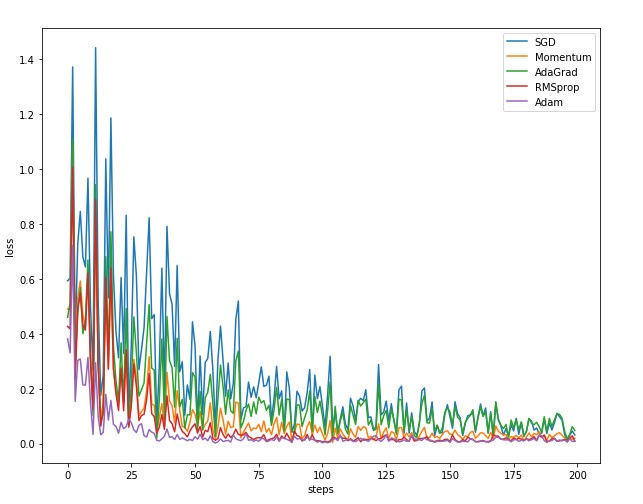
下图是batch_size=10的结果
下图是batch_size=30的结果
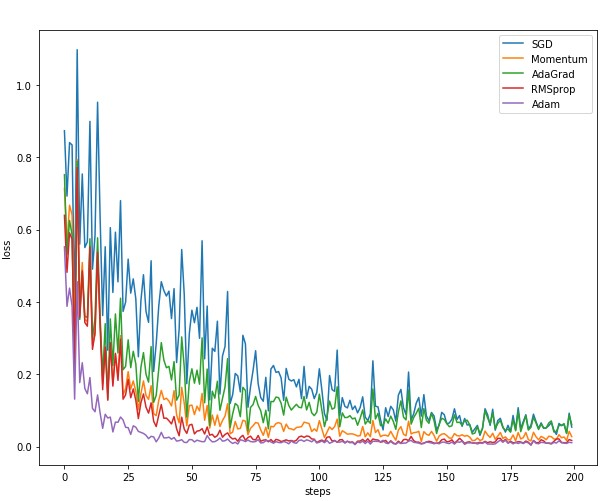
可以看的出Adam方法收敛速度最快,并且波动最小。
TensorFlow中的优化算法的更多相关文章
- Tensorflow 中的优化器解析
Tensorflow:1.6.0 优化器(reference:https://blog.csdn.net/weixin_40170902/article/details/80092628) I: t ...
- optim.py-使用tensorflow实现一般优化算法
optim.py Project URL:https://github.com/Codsir/optim.git Based on: tensorflow, numpy, copy, inspect ...
- TensorFlow中设置学习率的方式
目录 1. 指数衰减 2. 分段常数衰减 3. 自然指数衰减 4. 多项式衰减 5. 倒数衰减 6. 余弦衰减 6.1 标准余弦衰减 6.2 重启余弦衰减 6.3 线性余弦噪声 6.4 噪声余弦衰减 ...
- 分别使用 Python 和 Math.Net 调用优化算法
1. Rosenbrock 函数 在数学最优化中,Rosenbrock 函数是一个用来测试最优化算法性能的非凸函数,由Howard Harry Rosenbrock 在 1960 年提出 .也称为 R ...
- 梯度优化算法总结以及solver及train.prototxt中相关参数解释
参考链接:http://sebastianruder.com/optimizing-gradient-descent/ 如果熟悉英文的话,强烈推荐阅读原文,毕竟翻译过程中因为个人理解有限,可能会有谬误 ...
- 机器学习中几种优化算法的比较(SGD、Momentum、RMSProp、Adam)
有关各种优化算法的详细算法流程和公式可以参考[这篇blog],讲解比较清晰,这里说一下自己对他们之间关系的理解. BGD 与 SGD 首先,最简单的 BGD 以整个训练集的梯度和作为更新方向,缺点是速 ...
- TensorFlow实现与优化深度神经网络
TensorFlow实现与优化深度神经网络 转载请注明作者:梦里风林Github工程地址:https://github.com/ahangchen/GDLnotes欢迎star,有问题可以到Issue ...
- TensorFlow中的通信机制——Rendezvous(二)gRPC传输
背景 [作者:DeepLearningStack,阿里巴巴算法工程师,开源TensorFlow Contributor] 本篇是TensorFlow通信机制系列的第二篇文章,主要梳理使用gRPC网络传 ...
- TensorFlow中的并行执行引擎——StreamExecutor框架
背景 [作者:DeepLearningStack,阿里巴巴算法工程师,开源TensorFlow Contributor] 在前一篇文章中,我们梳理了TensorFlow中各种异构Device的添加和注 ...
随机推荐
- jQuery 自定义函数写法分享
时间:02月20日 自定义主要通过两种方式实现$.extend({aa:function(){}});$.fn.extend({aa:function(){}});调用的方法分别是:$.aa(); ...
- node.js如何将远程的文件下载到本地、解压、读取
其实要解决的问题,很简单,获取远程文件,然后解压到本地读取. 在vscode中通过node.js来实现是比较方便的,相比之前的zip.js,我觉得我还是比较喜欢node.js实现方式. test.js ...
- 在MongoDB数据库中查询数据(上)
在MongoDB数据库中查询数据(上) 在MongoDB数据库中,可以使用Collection对象的find方法从一个集合中查询多个数据文档,find方法使用方法如下所示: collection.fi ...
- PAT A1024 Palindromic Number (25 分)——回文,大整数
A number that will be the same when it is written forwards or backwards is known as a Palindromic Nu ...
- python基础学习第一天
def用法 函数定义的基本格式如下: def function(params): somthing return values 说明:return语句可选,出现return语句表示函数 ...
- Codeforces round 1083
Div1 526 这个E考试的时候没调出来真的是耻辱.jpg A 求个直径就完事 #include<cstdio> #include<algorithm> #include&l ...
- (原创)odoo11配置邮件功能的那些事儿
要点总结: 1.odoo的邮件系统功能设计目的,主要是解决业务相关的邮件沟通问题,切记不要将odoo当作邮件系统或者邮件客户端使用 2.odoo收件,默认需要邮件系统支持catch-all功能,但可惜 ...
- wpf项目打开多个窗体在任务栏只有一个任务
原文:wpf项目打开多个窗体在任务栏只有一个任务 如果在wpf里,在一个父窗体上打开子窗体,只在任务栏显示一个任务,不是qq聊天窗口俩人聊天人显示俩给那样,只能显示 一个 private void B ...
- 在平衡树的海洋中畅游(三)——Splay
Preface 由于我怕学习了Splay之后不直接写blog第二天就忘了,所以强行加了一波优先级. 论谁是天下最秀平衡树,我Splay第一个不服.维护平衡只靠旋转. 一言不合转死你 由于平衡树我也介绍 ...
- 【LGR-048 五周年庆贺】洛谷6月月赛
Luogu的五周年庆典比赛,还是比较满意的. 题目清新不毒瘤,数据优质不卡常,解法自然,为出题人点赞. 前三题的难度都很低,T5个人感觉还好.但是最后那个splay+hash是什么神仙东西. 最后好像 ...