python 爬虫-2
小白新手完全不懂的什么,还有一个robots.txt限制文件,稀里糊涂的 还是百度 可以看一下:http://www.baidu.com/robots.txt
里面会有一些限制,常见的一些配置:
1. 允许所有的robot访问
User-agent: *
Allow: / #(允许根目录==所有目录)
或者
User-agent: *
Disallow: #(注意:Disallow是空的。没有限制==所有)
2. 禁止所有搜索引擎访问网站的任何部分
User-agent: *
Disallow: / #(注意:Disallow是限制根目录==所有目录)
3. 仅禁止Baiduspider访问您的网站
User-agent: Baiduspider
Disallow: /
4. 仅允许Baiduspider访问您的网站
User-agent: Baiduspider
Disallow:
5. 禁止spider访问特定目录
User-agent: *
Disallow: /cgi-bin/
6. 允许访问特定目录中的部分url
User-agent: *
Allow: /cgi-bin/see
Disallow: /~joe/
验证用户的代码:
agent = 用户名
rp = robotparser.RobotFileParser()
url = 'http://www.baidu.com'
robots_url = 'http://www.baidu.com/robots.txt'
rp.set_url(robots_url)
rp.read()
if rp.can_fetch(agent, url):
#如果用户被robots.txt允许 返回true
#如果用户不被robots.txt允许 返回false
根据这个robot.txt文件的内容,编写爬虫时,去匹配一下,是否有权限
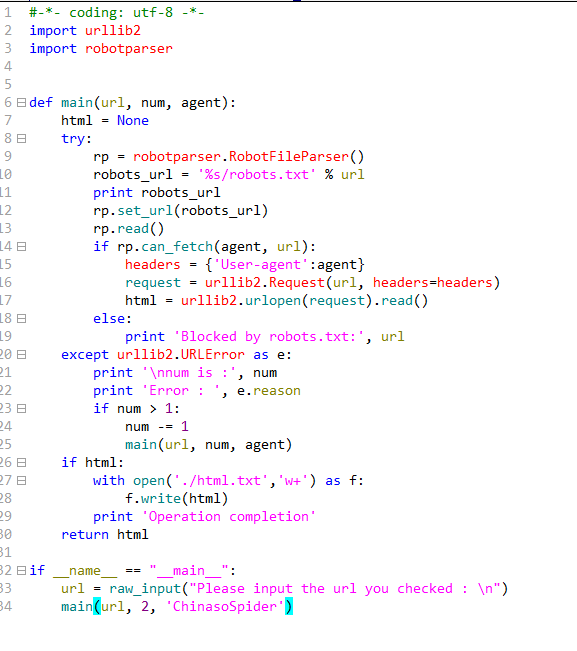
百度允许的用户:ChinasoSpider(在百度的robot.txt中),去验证
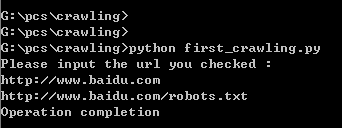
自己随便写的用户:zzf,去验证
python 爬虫-2的更多相关文章
- Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的博客,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了 ...
- python爬虫成长之路(一):抓取证券之星的股票数据
获取数据是数据分析中必不可少的一部分,而网络爬虫是是获取数据的一个重要渠道之一.鉴于此,我拾起了Python这把利器,开启了网络爬虫之路. 本篇使用的版本为python3.5,意在抓取证券之星上当天所 ...
- python爬虫学习(7) —— 爬取你的AC代码
上一篇文章中,我们介绍了python爬虫利器--requests,并且拿HDU做了小测试. 这篇文章,我们来爬取一下自己AC的代码. 1 确定ac代码对应的页面 如下图所示,我们一般情况可以通过该顺序 ...
- python爬虫学习(6) —— 神器 Requests
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库.用 Python 编写,真正的为人类着想. Python 标准库中的 urllib2 模块提供了你所需要的大多数 H ...
- 批量下载小说网站上的小说(python爬虫)
随便说点什么 因为在学python,所有自然而然的就掉进了爬虫这个坑里,好吧,主要是因为我觉得爬虫比较酷,才入坑的. 想想看,你可以批量自动的采集互联网上海量的资料数据,是多么令人激动啊! 所以我就被 ...
- python 爬虫(二)
python 爬虫 Advanced HTML Parsing 1. 通过属性查找标签:基本上在每一个网站上都有stylesheets,针对于不同的标签会有不同的css类于之向对应在我们看到的标签可能 ...
- Python 爬虫1——爬虫简述
Python除了可以用来开发Python Web之后,其实还可以用来编写一些爬虫小工具,可能还有人不知道什么是爬虫的. 一.爬虫的定义: 爬虫——网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区 ...
- Python爬虫入门一之综述
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- [python]爬虫学习(一)
要学习Python爬虫,我们要学习的共有以下几点(python2): Python基础知识 Python中urllib和urllib2库的用法 Python正则表达式 Python爬虫框架Scrapy ...
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
随机推荐
- 【python】——python3 与 python2 的那些不兼容
python2 python3 string.uppercase string.ascii_uppercase string.lowercase string.ascii_lowercase xran ...
- /usr/bin/uwsgi --http :8888 --wsgi-file wsgi.py --master --processes 4 --threads 2
/usr/bin/uwsgi --http :8888 --wsgi-file wsgi.py --master --processes 4 --threads 2 root 18756 0.0 0. ...
- java.lang.NoClassDefFoundError: javax/annotation/Priority
异常内容: 2017-09-25-15-02 [localhost-startStop-1] [org.springframework.web.context.ContextLoader] [ERRO ...
- 目前我对ReactNative的了解
1.什么是React? 一个js组件库,不同于angular的是一个完整的framework,React需要像jQuery一样写事件监听逻辑,最大特点是Virtual DOM. 官网:https:// ...
- Windows上使用telnet测试端口号
之前测试服务器某一端口开启开启情况一般在服务器上使用 netstat –ano|findstr "端口号"命令查看. 但是有时候端口在服务器上开通了,但是客户端并不一定可以访问到 ...
- Ext-JS-Modern-Demo 面向移动端示例
基于Ext Js 6.5.2 面向移动端示例,低于此版本可能存在兼容问题,慎用 已忽略编译目录,请自行编译运行 Sencha Cmd 版本:v6.5.2.15 git地址:https://github ...
- A - Black Box 优先队列
来源poj1442 Our Black Box represents a primitive database. It can save an integer array and has a spec ...
- 删除或修改本地Git保存的账号密码
win10 系统下进入 控制面板 > 用户帐户 > 管理你的凭据 选择 [Windows 凭据] git 保存的用户信息在普通凭据列表里 >>编辑>>>完成
- canvas霓虹雨
在codepen上看到一个Canvas做的下雨效果动画,感觉蛮有意思的.就研究了下,这里来分享下,实现技巧.效果可以见下面的链接. 霓虹雨: http://codepen.io/natewiley/f ...
- orace函数
处理字符的函数 lower(char);//把字符串转换成小写格式 upper(char);//把字符转换成大写 length(char);//返回字符串的长度 substr(char,m,n);// ...