SPSC Queue
在多线程编程中,一个著名的问题是生产者-消费者问题 (Producer Consumer Problem, PC Problem)。
对于这类问题,通过信号量加锁 (https://www.cnblogs.com/sinkinben/p/14087750.html) 来设计 RingBuffer 是十分容易实现的,但欠缺性能。
考虑一个特殊的场景,生产者和消费者均只有一个 (Single Producer Single Consumer, SPSC),在这种情况下,我们可以设计一个无锁队列来解决 PC 问题。
0. Background
考虑以下场景:在一个计算密集型 (Computing Intensive) 和延迟敏感的 for 循环当中,每次循环结束,需要打印当前的迭代次数以及计算结果。
void matrix_compute()
{
for (i = 0 to n)
{
// code of computing
...
// print i and result of computing
std::cout << ...
}
}
在这种情况下,如果使用简单的 std::cout 输出,由于 I/O 的性质,将会造成严重的延迟 (Latency)。
一个直观的解决办法是:将 Log 封装为一个字符串,传递给其他线程,让其他线程打印该字符串,实现异步的 Logging 。
1. Lock-free SPSC Queue
此处使用一个 RingBuffer 来实现队列。
由于是 SPSC 型的队列,队列头部 head 只会被 Consumer 写入,队列尾部 tail 只会被 Producer 写入,所以 SPSC Queue 可以是无锁的,但需要保证写入的原子性。
template <class T> class spsc_queue
{
private:
std::vector<T> m_buffer;
std::atomic<size_t> m_head;
std::atomic<size_t> m_tail;
public:
spsc_queue(size_t capacity) : m_buffer(capacity + 1), m_head(0), m_tail(0) {}
inline bool enqueue(const T &item);
inline bool dequeue(T &item);
};
对于一个 RingBuffer 而言,判空与判满的方法如下:
- Empty 的条件:
head == tail - Full 的条件:
(tail + 1) % N == head
因此,enqueue 和 dequeue 可以是以下的实现:
inline bool enqueue(const T &item)
{
const size_t tail = m_tail.load(std::memory_order_relaxed);
const size_t next = (tail + 1) % m_buffer.size();
if (next == m_head.load(std::memory_order_acquire))
return false;
m_buffer[tail] = item;
m_tail.store(next, std::memory_order_release);
return true;
}
inline bool dequeue(T &item)
{
const size_t head = m_head.load(std::memory_order_relaxed);
if (head == m_tail.load(std::memory_order_acquire))
return false;
item = m_buffer[head];
const size_t next = (head + 1) % m_buffer.size();
m_head.store(next, std::memory_order_release);
return true;
}
std::memory_order 的使用说明:https://en.cppreference.com/w/cpp/atomic/memory_order
Benchmark 计算 SPSC Queue 的吞吐量:
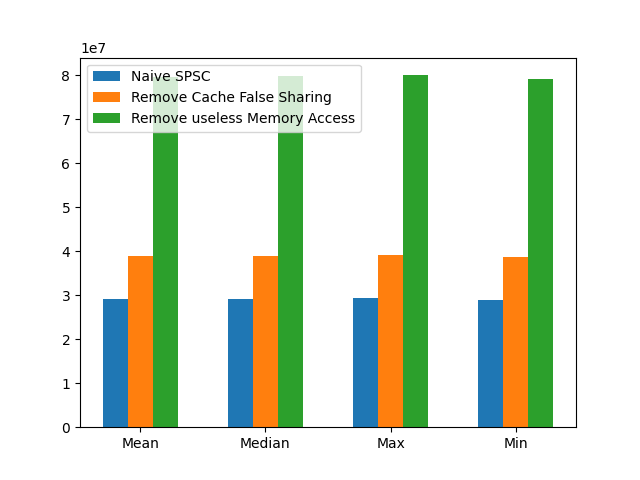
Mean: 29,158,897.200000 elements/s
Median: 29,178,822.000000 elements/s
Max: 29,315,199 elements/s
Min: 28,995,515 elements/s
Benchmark 的计算方法为:
- Producer 和 Consumer 分别执行
1e8次enqueue和dequeue,计算队列为空所耗费的总时间t,1e8 / t即为吞吐量。 - 上述过程执行 10 次,最终计算
mean, median, min, max的值。
2. Remove cache false sharing
什么是 Cache False Sharing? 参考 Architecture of Modern CPU 的 Exercise 一节。
int *a = new int[1024];
void worker(int idx)
{
for (int j = 0; j < 1e9; j++)
a[idx] = a[idx] + 1;
}
考虑以下程序:
- P1: 开启 2 线程,执行
worker(0), worker(1) - P2: 开启 2 线程,执行
worker(0), worker(16)
P2 的执行速度会比 P1 快,现代 CPU 的 Cache Line 大小一般为 64 字节,由于 a[0], a[1] 位于同一个 CPU Core 的同一个 Cache Line,每次写入都会带来数据竞争 (Data Race) ,触发缓存和内存的同步(参考 MESI 协议),而 a[0], a[16] 之间相差了 64 字节,不在同一个 Cache Line,所以避免了这个问题。
所以,对于上述的 SPSC Queue,可以进行以下改进:
template <class T>
class spsc_queue
{
private:
std::vector<T> m_buffer;
alignas(64) std::atomic<size_t> m_head;
alignas(64) std::atomic<size_t> m_tail;
};
这里的 alignas(64) 实际上改为 std::hardware_constructive_interference_size 更加合理,因为 Cache Line 的大小取决于具体 CPU 硬件的实现,并不总是为 64 字节。
#ifdef __cpp_lib_hardware_interference_size
using std::hardware_constructive_interference_size;
using std::hardware_destructive_interference_size;
#else
// 64 bytes on x86-64 │ L1_CACHE_BYTES │ L1_CACHE_SHIFT │ __cacheline_aligned │ ...
constexpr std::size_t hardware_constructive_interference_size = 64;
constexpr std::size_t hardware_destructive_interference_size = 64;
#endif
Benchmark 结果:
Mean: 38,993,940.400000 elements/s
Median: 39,027,123.000000 elements/s
Max: 39,253,946 elements/s
Min: 38,624,197 elements/s
3. Remove useless memory access
在使用 spsc_queue 的时候,通常会有以下形式的代码:
spsc_queue sq(1024);
// Producer keep spinning
int x = 233;
while (!sq.enqueue(x)) {}
而在 dequeue/enqueue 中,存在判空/判满的代码:
inline bool enqueue(const T &item)
{
const size_t tail = m_tail.load(std::memory_order_relaxed);
const size_t next = (tail + 1) % m_buffer.size();
if (next == m_head.load(std::memory_order_acquire))
return false;
// ...
}
每次执行 m_head.load,Producer 线程的 CPU 都会访问一次 m_head 所在的内存,但实际上触发该条件的概率较小(因为在实际的场景下, Producer/Consumer 都是计算密集型,否则根本不需要无锁的数据结构)。在判空/判满的时候,可以去 “离 CPU 更近” 的 Cache 去获取 m_head 的值。
template <class T>
class spsc_queue
{
private:
std::vector<T> m_buffer;
alignas(hardware_constructive_interference_size) std::atomic<size_t> m_head;
alignas(hardware_constructive_interference_size) std::atomic<size_t> m_tail;
alignas(hardware_constructive_interference_size) size_t cached_head;
alignas(hardware_constructive_interference_size) size_t cached_tail;
};
inline bool enqueue(const T &item)
{
const size_t tail = m_tail.load(std::memory_order_relaxed);
const size_t next = (tail + 1) % m_buffer.size();
if (next == cached_head)
{
cached_head = m_head.load(std::memory_order_acquire);
if (next == cached_head)
return false;
}
}
Benchmark 结果:
Mean: 79,740,671.300000 elements/s
Median: 79,838,314.000000 elements/s
Max: 80,044,793 elements/s
Min: 79,241,180 elements/s
4. Summary
3 个版本的 spsc_queue 的吞吐量比较(均值,中位数,最大值,最小值)。在优化 Cache False Sharing 和优先从 Cache 读取 head, tail 之后,可得到 x2 的提升。
SPSC Queue的更多相关文章
- readerwriterqueue 一个用 C++ 实现的快速无锁队列
https://www.oschina.net/translate/a-fast-lock-free-queue-for-cpp?cmp&p=2 A single-producer, sing ...
- [数据结构]——链表(list)、队列(queue)和栈(stack)
在前面几篇博文中曾经提到链表(list).队列(queue)和(stack),为了更加系统化,这里统一介绍着三种数据结构及相应实现. 1)链表 首先回想一下基本的数据类型,当需要存储多个相同类型的数据 ...
- Azure Queue Storage 基本用法 -- Azure Storage 之 Queue
Azure Storage 是微软 Azure 云提供的云端存储解决方案,当前支持的存储类型有 Blob.Queue.File 和 Table. 笔者在<Azure File Storage 基 ...
- C++ std::queue
std::queue template <class T, class Container = deque<T> > class queue; FIFO queue queue ...
- 初识Message Queue之--基础篇
之前我在项目中要用到消息队列相关的技术时,一直让Redis兼职消息队列功能,一个偶然的机会接触到了MSMQ消息队列.秉着技术还是专业的好为原则,对MSMQ进行了学习,以下是我个人的学习笔记. 一.什么 ...
- 搭建高可用的rabbitmq集群 + Mirror Queue + 使用C#驱动连接
我们知道rabbitmq是一个专业的MQ产品,而且它也是一个严格遵守AMQP协议的玩意,但是要想骚,一定需要拿出高可用的东西出来,这不本篇就跟大家说 一下cluster的概念,rabbitmq是erl ...
- PriorityQueue和Queue的一种变体的实现
队列和优先队列是我们十分熟悉的数据结构.提供了所谓的“先进先出”功能,优先队列则按照某种规则“先进先出”.但是他们都没有提供:“固定大小的队列”和“固定大小的优先队列”的功能. 比如我们要实现:记录按 ...
- C#基础---Queue(队列)的应用
Queue队列,特性先进先出. 在一些项目中我们会遇到对一些数据的Check,如果数据不符合条件将会把不通过的信息返回到界面.但是对于有的数据可能会Check很多条件,如果一个数据一旦很多条件不 ...
- [LeetCode] Queue Reconstruction by Height 根据高度重建队列
Suppose you have a random list of people standing in a queue. Each person is described by a pair of ...
- [LeetCode] Implement Queue using Stacks 用栈来实现队列
Implement the following operations of a queue using stacks. push(x) -- Push element x to the back of ...
随机推荐
- 兴达易控Modbus转Profinet 网关连接 ACS510 变频器配置案例
案例简介: 该案例为兴达易控Modbus转Profinet网关(XD-MDPN100)将ABB ACS510 变频器接入西门子 1200PLC.需要设备为西门子 PLC1200.ACS510 变频器. ...
- pta2023年9月7日 第五期
5月23日 11月14日 有效期3年: 更新方式待定: 双方认证合作CCF编程培训师资认证(PTA)中国计算机学会https://pta.ccf.org.cn/中国科教工作者协会(原:中国青 ...
- OpenJDK17-JVM源码阅读-ZGC-并发标记
1.ZGC简介 1.1 介绍 ZGC 是一款低延迟的垃圾回收器,是 Java 垃圾收集技术的最前沿,理解了 ZGC,那么便可以说理解了 java 最前沿的垃圾收集技术. 从 JDK11 中作为试验特性 ...
- CSP2021游记
题外话 中午十二点半到了考场.没到时间不让进,恰巧发现 lhm 在对面饭店于是去讨论了一下上午 J 组的题,复习了线段树板子( 等到进考场坐好的时候已经两点半了,看考号本来以为我们同机房三个同学会坐一 ...
- 实战|如何低成本训练一个可以超越 70B Llama2 的模型 Zephyr-7B
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新.社区活动.学习资源和内容更新.开源库和模型更新等,我们将其称之为「Hugging Ne ...
- FreeSWITCH添加自定义endpoint之api及app开发
操作系统 :CentOS 7.6_x64 FreeSWITCH版本 :1.10.9 之前写过FreeSWITCH添加自定义endpoint的文章,今天整理下api及app开发的笔记.历史文章可参考如下 ...
- windows11配置wsl2虚拟linux环境
windows11配置wsl2虚拟linux环境 wsl( Windows Subsystem for Linux )是microsoft官方为windows开发的模拟Linux方法.避免了虚拟机vm ...
- 生成伪随机数 rand;srand函数
1 相关内容来自鱼c论坛https://fishc.com.cn/forum.php?mod=viewthread&tid=84363&extra=page%3D1%26filter% ...
- Keepalived+Nginx高可用案例(抢占式与非抢占式)
(1)下载安装Keepalived源码包 Keepalived官网源码包下载地址 在服务器上解压 tar -xf keepalived-2.2.8.tar.gz 安装相关前置依赖 yum -y ins ...
- 从物理机到K8S:应用系统部署方式的演进及其影响
公众号「架构成长指南」,专注于生产实践.云原生.分布式系统.大数据技术分享. 概述 随着科技的进步,软件系统的部署架构也在不断演进,从以前传统的物理机到虚拟机.Docker和Kubernetes,我们 ...