技本功|Hive优化之监控(三)
Hive是大数据领域常用的组件之一,主要是大数据离线数仓的运算,关于Hive的性能调优在日常工作和面试中是经常涉及的一个点,因此掌握一些Hive调优是必不可少的技能。影响Hive效率的主要有数据倾斜、数据冗余、job的IO以及不同底层引擎配置情况和Hive本身参数和HiveSQL的执行等因素。本文主要是从监控运维的角度对Hive进行整体性能把控,通过对hive元数据监控,提前发现Hive表的不合理处及可优化点,将被动运维转化为主动运维。
1 Hive元数据简介
Hive元数据一般会存储在关系数据库中,mysql是最常见的选择,这里介绍的就是Hive元数据就是存储在myslq中的,本次会介绍几张主要的元数据表,DBS、TBLS、SDS、PARTITIONS
1.1 Hive数据库相关的元数据表(DBS)

1.2 Hive表和视图相关的元数据表(TBLS)

1.3 Hive文件存储信息相关的元数据表(SDS)

1.4 Hive数据库相关的元数据表(PARTITIONS)

2 收集Hive元数据
在使用Hive元数据做监控时要确保相应表或者分区的元数据信息已经被收集。收集元数据的方式如下
2.1 收集表的元数据
analyze table 表名 compute statistic;
2.2 收集表的字段的元数据
analyze table 表名 compute statistic for columns;
2.3 收集所有分区的元数据
analyze table 表名 partition(分区列) compute statistic;
2.4 指定特定分区进行收集元数据
analyze table 表名 partition(分区列=分区值) compute statistic;
2.5 收集所有分区的列的元数据
analyze table 表名 partition(分区列) compute statistic for columns;
3 Hive元数据监控案例
3.1监控普通表存储的文件的平均大小
对于大的文件块可能导致数据在读取时产生数据倾斜,影响集群任务的运行效率。下面sql是对于大于两倍HDFS文件块大小的表:
-- 整体逻辑:通过DBS找到对应库下面的表TBLS,再通过TBLS找到每个表对应的表属性,取得totalSize和numFiles两个属性,前者表示文件大小,后者表示文件数量
**SELECT**
TBL_NAME,round(avgfilesize,1) **as** 'fileSize(Mb)'
**FROM** (
**SELECT**
tp.totalSize/(1024*1024)/numFiles avgfilesize,TBL_NAME
**FROM** metastore.dbs d
**INNER** **join** metastore.tbls t **on** d.DB_ID = t.DB_ID
**left** **join** (
**SELECT** TBL_ID,
**MAX**(**case** PARAM_KEY **when** 'numFiles' **then** PARAM_VALUE **ELSE** 0 **END**) numFiles,
**MAX**(**case** PARAM_KEY **when** 'totalSize' **then** PARAM_VALUE **ELSE** 0 **END** ) totalSize
**from** metastore.table_params
**GROUP** **by** TBL_ID
) tp **on** t.TBL_ID = tp.TBL_ID
**where** d.NAME = '要监控的库'
**and** tp.numFiles **is** **not** **NULL**
**and** tp.numFiles > 0
) a **where** avgfilesize > hdfs的文件块大小*2
**ORDER** **BY** avgfilesize **desc**;
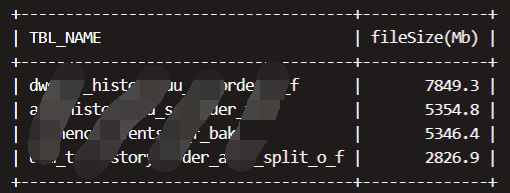
3.2监控分区存储的文件平均大小,大于两倍HDFS文件块大小的分区,
-- 整体逻辑:先用DBS关联TBLS表,TBLS表关联PARTITIONS表PARTITION表关联PARTITION_PARAMS
**SELECT**
TBL_NAME,part_name,round(avgfilesize,1) **as** 'fileSize(Mb)'
**FROM** (
**SELECT**
pp.totalSize/(1024*1024)/numFiles avgfilesize,TBL_NAME,part.PART_NAME
**FROM** metastore.dbs d
**INNER** **join** metastore.TBLS t **on** d.DB_ID = t.DB_ID
**INNER** **join** metastore.PARTITIONS part **on** t.TBL_ID = part.TBL_ID
**left** **join** (
**SELECT** PART_ID,
-- 每个表存储的文件个数
**MAX**(**case** PARAM_KEY **when** 'numFiles' **then** PARAM_VALUE **ELSE** 0 **END**) numFiles,
-- 文件存储的大小
**MAX**(**case** PARAM_KEY **when** 'totalSize' **then** PARAM_VALUE **ELSE** 0 **END** ) totalSize
**from** metastore.PARTITION_PARAMS
**GROUP** **by** PART_ID
) pp **on** part.PART_ID = pp.PART_ID
**where** d.NAME = '要监控的库'
**and** pp.numFiles **is** **not** **NULL**
**and** pp.numFiles > 0
) a **where** avgfilesize >hdfs的文件块大小*2
**ORDER** **BY** avgfilesize **desc**;
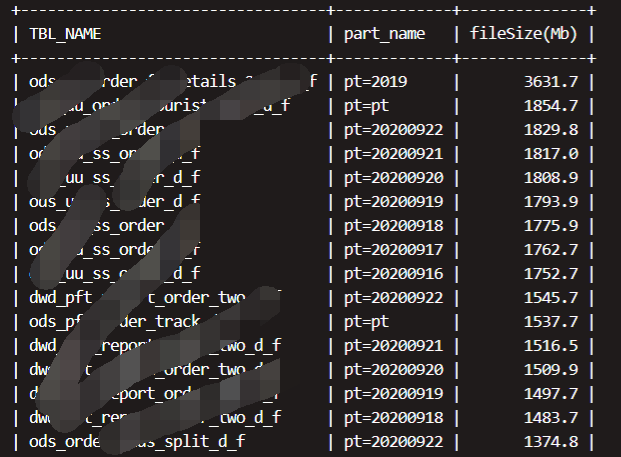
3.3监控大表不分区的表
对于大数据量的表,如果不进行分区,意味着程序在读取相同的数据时需要遍历更多的文件块,性能会下降很多。
**select** t.TBL_NAME ,round(totalSize/1024/1024,1) **as** 'fileSize(Mb)'
**FROM** metastore.DBS d
**inner** **join** metastore.TBLS t **on** d.`DB_ID` = t.`DB_ID`
**inner** **join** (
**select** `TBL_ID`,**max**(**case** `PARAM_KEY` **when** 'totalSize' **then** `PARAM_VALUE` **else** 0 **end**) totalSize
**from** `TABLE_PARAMS`
**group** **by** `TBL_ID`
) tp **on** t.`TBL_ID` = tp.`TBL_ID`
**left** **join**
(
**select** **distinct** `TBL_ID` **from** metastore.PARTITIONS p
) part **on** t.`TBL_ID` = part.`TBL_ID`
**where** d.`NAME` = '要监控的库'
**and** part.`TBL_ID` **is** **null**
**and** totalSize/1024/1024/1024 > 30
**ORDER** **BY** totalSize/1024 **desc**;
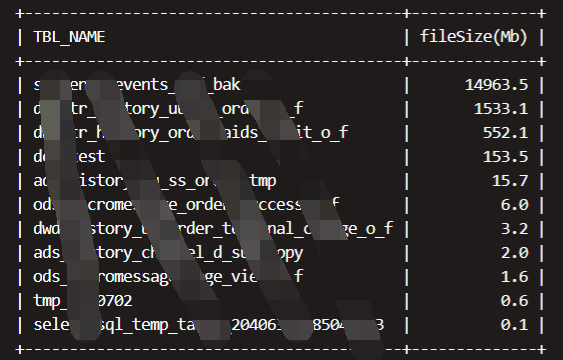
3.4监控表分区的数量
了解表的分区数量,在做全表join时如果一个表数量不大,分区很多,可以考虑分区合并等优化手段
**SELECT**
t.TBL_NAME '表名',d.`NAME` '库名', **COUNT**(part.PART_NAME) '分区数'
**FROM**
DBS d
**INNER** **JOIN** TBLS t **on** d.DB_ID = t.DB_ID
**INNER** **join** `PARTITIONS` part **on** part.TBL_ID = t.TBL_ID
**WHERE** d.`NAME` = '要监控的库'
**GROUP** **by** t.TBL_NAME,d.`NAME`
**ORDER** **BY** **COUNT**(part.PART_NAME) **desc**;
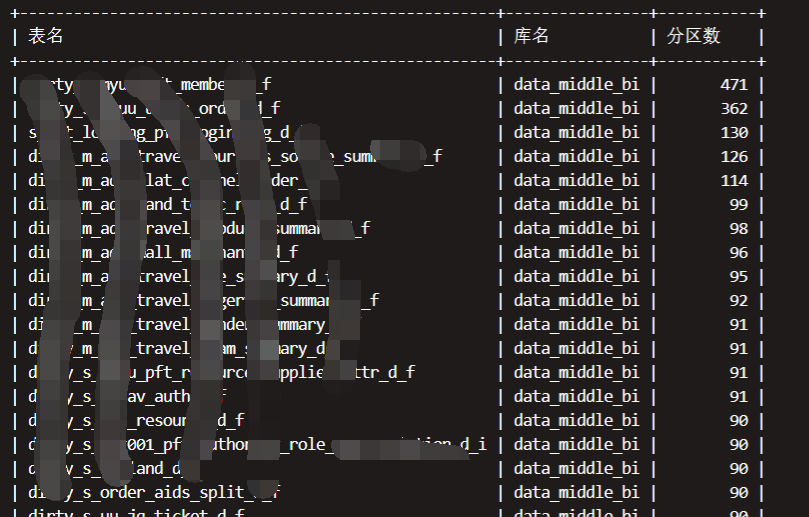
结语:
Hive元数据的监控主要目的就是对Hive中表情况的整体把控,这里主要介绍了大数据块、不分区表、表分区这几个指标的监控,当然还有很多,比如hive的小文件、表的数据存储格式等等,对这些信息的长期监控,最好可以和grafana这些结合展示,这对整个数仓的稳定运行至关重要。后面我们还会出Hive SQL调优相关的文章,敬请期待。
更多业务信息请查看云掣官网https://www.dtstack.com/dtsmart/
技本功|Hive优化之监控(三)的更多相关文章
- Hive 12、Hive优化
要点:优化时,把hive sql当做map reduce程序来读,会有意想不到的惊喜. 理解hadoop的核心能力,是hive优化的根本. 长期观察hadoop处理数据的过程,有几个显著的特征: 1. ...
- hive优化之——控制hive任务中的map数和reduce数
一. 控制hive任务中的map数: 1. 通常情况下,作业会通过input的目录产生一个或者多个map任务.主要的决定因素有: input的文件总个数,input的文件大小,集群设置的文 ...
- Hive优化案例
1.Hadoop计算框架的特点 数据量大不是问题,数据倾斜是个问题. jobs数比较多的作业效率相对比较低,比如即使有几百万的表,如果多次关联多次汇总,产生十几个jobs,耗时很长.原因是map re ...
- 一起学Hive——总结常用的Hive优化技巧
今天总结本人在使用Hive过程中的一些优化技巧,希望给大家带来帮助.Hive优化最体现程序员的技术能力,面试官在面试时最喜欢问的就是Hive的优化技巧. 技巧1.控制reducer数量 下面的内容是我 ...
- 大数据技术之_08_Hive学习_04_压缩和存储(Hive高级)+ 企业级调优(Hive优化)
第8章 压缩和存储(Hive高级)8.1 Hadoop源码编译支持Snappy压缩8.1.1 资源准备8.1.2 jar包安装8.1.3 编译源码8.2 Hadoop压缩配置8.2.1 MR支持的压缩 ...
- 【转】Hive优化总结
优化时,把hive sql当做map reduce程序来读,会有意想不到的惊喜. 理解Hadoop的核心能力,是hive优化的根本.这是这一年来,项目组所有成员宝贵的经验总结. 长期观察hadoo ...
- 技本功丨请带上纸笔刷着看:解读MySQL执行计划的type列和extra列
本萌最近被一则新闻深受鼓舞,西工大硬核“女学神”白雨桐,获6所世界顶级大学博士录取 货真价值的才貌双全,别人家的孩子 高考失利与心仪的专业失之交臂,选择了软件工程这门自己完全不懂的专业.即便全部归零, ...
- Hive(六)hive执行过程实例分析与hive优化策略
一.Hive 执行过程实例分析 1.join 对于 join 操作:SELECT pv.pageid, u.age FROM page_view pv JOIN user u ON (pv.useri ...
- 技本功丨知否知否,Redux源码竟如此意味深长(上集)
夫 子 说 元月二号欠下袋鼠云技术公号一篇关于Redux源码解读的文章,转眼月底,期间常被“债主”上门催债.由于年底项目工期比较紧,于是债务就这样被利滚利.但是好在这段时间有点闲暇,于是赶紧把这篇文章 ...
- 百度APP移动端网络深度优化实践分享(三):移动端弱网优化篇
本文由百度技术团队“蔡锐”原创发表于“百度App技术”公众号,原题为<百度App网络深度优化系列<三>弱网优化>,感谢原作者的无私分享. 一.前言 网络优化解决的核心问题有三个 ...
随机推荐
- 全网最详细Java-JVM
Java-JVM ①JVM概述 ❶基本介绍 JVM:全称 Java Virtual Machine,一个虚拟计算机,Java 程序的运行环境(Java二进制字节码的运行环境) 特点: Java 虚拟机 ...
- 如何vue3中使用全局变量,与Vue2的区别
对比: 在vue2.x中我们挂载全局变量或方法是通过是使用Vue.prototype.$xxxx=xxx的形式来挂载,然后通过this.$xxx来获取挂载到全局的变量或者方法 但是 在vue3.x中显 ...
- 前端三件套系例之JS——JavaScript基础、JavaScript基本数据类型、JavaScript函数
文章目录 1 JavaScript基础 1.JavaScript是什么 2.JavaScript介绍 2-1 ECMAScript和JavaScript的关系 2-2 ECMAScript的历史 3. ...
- MySQL系列之——索引作用、索引的种类、B树、聚簇索引构建B树、辅助索引(S)构建B+树、辅助索引细分、索引树的高度、索引的基本管理、执行计划获取及分析、索引应用规范、优化器针对索引、问题汇总
文章目录 一 索引作用 二 索引的种类(算法) 三 B树 基于不同的查找算法分类介绍 B 树 B+树 B*树 四 在功能上的分类 4.1 聚簇索引构建B树(簇就是区) 4.1.1 前提 4.1.2 作 ...
- React跨路由组件动画
我们是袋鼠云数栈 UED 团队,致力于打造优秀的一站式数据中台产品.我们始终保持工匠精神,探索前端道路,为社区积累并传播经验价值. 本文作者:佳岚 回顾传统React动画 对于普通的 React 动画 ...
- 23集训 Day4 数论
快速幂 定义 快速幂,是一个在 \(\Theta(\log n)\) 的时间内计算 \(a^n\) 的小技巧,而暴力的计算需要 \(\Theta(n)\) 的时间. 解释 \[\because a^{ ...
- JS个人总结(1)
1. html页面引入js文件优先使用引入外部js文件. 2. 如果在html页面里使用<script></script>,则把js内容放在html内容下面,也就是</b ...
- .NET6发布项目到腾讯云Windows2012R全网最详细教程
注意:本次使用腾讯云作为本次的演示 1.创建服务器及连接 1.1 请先在腾讯云.阿里云等创建实例 1.2 打开远程连接工具输入在腾讯云获取的公网iP输入计算机 1.3 根据图片点击连接 1.4 输入服 ...
- Gitlab仓库代码更新时Jenkins自动构建
环境说明 1.Jenkins和gitlab已经都已经安装完毕 2.Jenkins能连接到gitlab获取项目并能手动创建项目 3.Jenkins和gitlab能相互访问的到(gitlab要能连接到Je ...
- docker 仓库-Harbor
docker 仓库之分布式 Harbor: Harbor 是一个用于存储和分发docker镜像的企业级Registry服务器,由于Vmware 开源,其通过添加一些企业必须的功能特性,例如安全.标识和 ...