strimzi实战之三:prometheus+grafana监控(按官方文档搞不定监控?不妨看看本文,已经踩过坑了)
欢迎访问我的GitHub
这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos
本篇概览
- 由于整个系列的实战都涉及到消息生产和消费,所以咱们需要一套监控服务,用于观察各种操作的效果,例如生产消息是否成功、消息是否被消费、有没有发生堆积等
- 因此,在前文完成了最基本的部署和体验后,今天就一起来把监控服务部署好,为后续的实战提供良好的后勤支撑
- 今天的实战,假设CentOS操作系统、kubernetes环境、pv这三样都已提前装好,我们要做的是:通过strimzi部署一套kafka服务,并且带有prometheus和grafana来监控这个kafka
- 如果您对安装kubernetes和pv还不了解,请参考:《快速搭建云原生开发环境(k8s+pv+prometheus+grafana)》,要注意的是,此文中虽然介绍了如何安装prometheus+grafana,但是在本篇用不上,您在参考此文的时候,只看k8s+pv部分即可
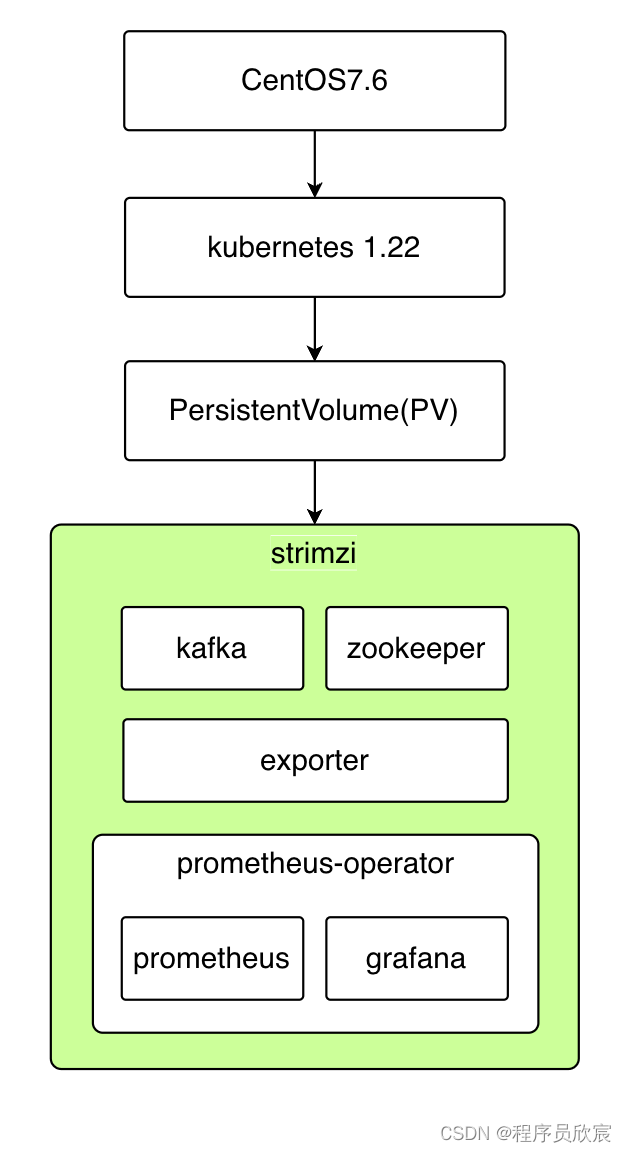
- 本篇的操作如下图所示,绿色部分及其内部是咱们要做的事情,前面的几个步骤假设您已经提前做好了
本文适合的读者
- 第一种读者:对欣宸的实战系列有信心,打算按照本文去部署监控服务
- 第二种读者:对官方资料存在疑问,寻求辅助信息加以对照
- 第三中读者:按照官方资料操作,结果难以成功(例如grafana上的数据始终为空)
- 这里提一下,本来欣宸也是按官方资料去部署监控的,然而遇到各种问题,要么服务启动失败,要么grafana没有数据,反复修改调整尝试后才部署成功并且数据正常,因此写下此文避免今后再次踩坑,也希望这点经验能给更多人提供有价值的参考,毕竟网上的strimzi类原创并不多,涉及监控的就更少了
重点问题需要先澄清
- 首先要搞清楚的是:咱们常说的prometheus-operator,到底是啥?
- 如下图,可见首先prometheus-operator是个github账号,该账号下面有两个重要的仓库:prometheus-operator和kube-prometheus
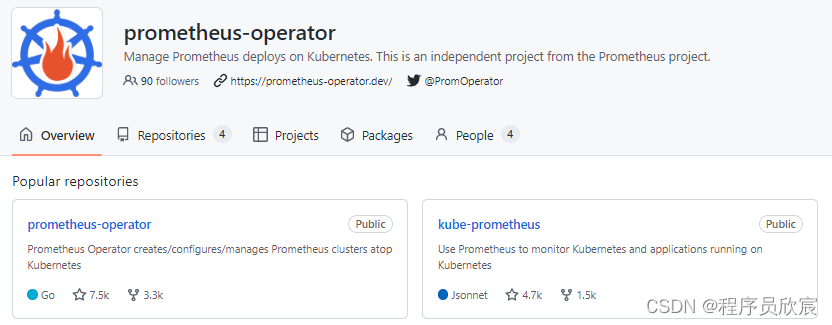
- 关于prometheus-operator和kube-prometheus这两个仓库的区别,继续看官方描述,如下图,prometheus-operator是基础,通过CRD简化了prometheus、alertmanager以及其他监控组件的部署,而kube-prometheus则是在prometheus-operator的基础上增加了很多集群监控的样例,例如多实例、各种指标的exporter等等

- 简单的说:prometheus-operator只提供监控服务用到各种要素,kube-prometheus在prometheus-operator的基础上提供了具体的成果,即各种监控图表
- 如果您看过《快速搭建云原生开发环境(k8s+pv+prometheus+grafana)》,会发现此文已介绍了如何部署prometheus+grafana,并且各种监控图表一应俱全,其实那里用的就是kube-prometheus
- 现在相信您已经清楚了prometheus-operator和kube-prometheus的关系,然后重点来了:strimzi的官方资料中,搭建监控服务是基于prometheus-operator来做的
- 也就是说,按照strimzi官方的资料部署好的监控服务中,只能看到strimzi相关的内容,例如消息相关、kafka服务相关,至于kube-prometheus中提供的那些丰富的监控内容(例如宿主机、kubernetes等相关指标),都是不存在的...
- 当然您可能会说:只要strimzi的exporter正常,完全可以自己部署kube-prometheus,再参考官方的脚本去自己定做监控报表即可,确实,这样做没问题,但是对于本系列来说就超纲了,咱们只是想借助prometheus和grafana观察strimzi的指标而已,其他的并非主题,能省就省吧...
官方操作速看
- 动手前快速浏览官方操作指导,对基本操作有个大概了解(自己遇到的问题也在此指出,为您把坑提前避开)
- strimzi关于监控相关的资料链接如下图红色箭头,地址是:https://strimzi.io/docs/operators/in-development/deploying.html#assembly-metrics-setup-str

执行kubectl apply -f kafka-metrics.yaml,这里面包含了Exporter(用于暴露指标),文件kafka-metrics.yaml可以在GitHub的发布包中找到
执行以下命令,生成名为prometheus-operator-deployment.yaml的文件
curl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/bundle.yaml | sed -e '/[[:space:]]*namespace: [a-zA-Z0-9-]*$/s/namespace:[[:space:]]*[a-zA-Z0-9-]*$/namespace: my-namespace/' > prometheus-operator-deployment.yaml
- 执行kubectl create -f prometheus-operator-deployment.yaml,完成prometheus-operator的部署
- 修改prometheus.yml文件,这里面是prometheus的配置信息,现在要修改的是namespace,改成您自己的
sed -i 's/namespace: .*/namespace: my-namespace/' prometheus.yaml
- 修改文件strimzi-pod-monitor.yaml,找到namespaceSelector.matchNames属性,改成自己的namespace(漏掉这一步就是致命问题,会导致grafana不出数据,我漏过...)
- 执行以下操作
kubectl apply -f prometheus-additional.yaml
kubectl apply -f strimzi-pod-monitor.yaml
kubectl apply -f prometheus-rules.yaml
kubectl apply -f prometheus.yaml
- 部署grafana
kubectl apply -f grafana.yaml
- 上述步骤是对官方操作的简单介绍,接下来就是我这边逐步详细的操作过程,可以确保成功的那种,为了避免官方文件变化导致部署问题,相关文件我都存入了自己的仓库
- 现在相信您对整个部署过程已经有了大致了解,接下来咱们开始吧
实际操作之一:创建命名空间
- 这里就随意些吧,我的命名空间是aabbcc
kubectl create namespace aabbcc
实际操作之二:创建strimzi的资源
kubectl create -f 'https://strimzi.io/install/latest?namespace=aabbcc' -n aabbcc
实际操作之三:部署kafka+zookeeper+exporter
- 执行以下命令,会下载一个名为kafka-metrics.yaml 的配置文件,并在kubernets创建文件中配置的资源,包括kafka集群及其exporter的部署(exporter的作用是向prometheus暴露监控数据),注意namespace
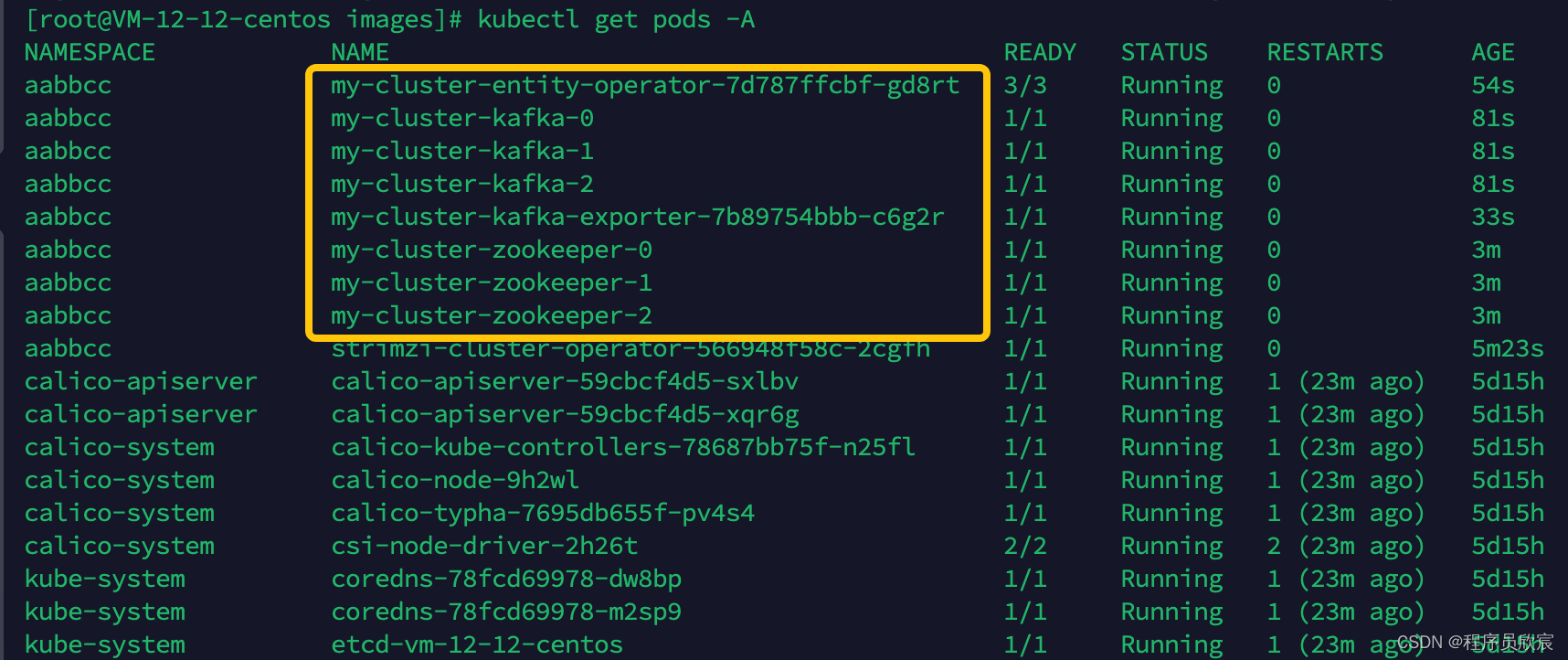
kubectl create -f 'https://gitee.com/zq2599/blog_download_files/raw/master/strimzi/prometheus/kafka-metrics.yaml?namespace=aabbcc' -n aabbcc
- 等待容器启动完毕,如下图所示,kafka集群和exporter都已经就绪,接下来该部署prometheus了
实际操作之四:部署prometheus+grafana
- 为了部署prometheus+grafana,这边要准备七个文件,接下来会详细说明
- 首先是准备好prometheus-operator的资源文件,执行以下命令,注意将aabbcc改成您自己的namespace(因为文件bundle.yaml很大,导致此命令会耗时三分钟左右,请耐心等待)
curl –connect-timeout 300 -m 300 -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/bundle.yaml | sed -e '/[[:space:]]*namespace: [a-zA-Z0-9-]*$/s/namespace:[[:space:]]*[a-zA-Z0-9-]*$/namespace: aabbcc/' > prometheus-operator-deployment.yaml
- 执行完上面的命令后,在本地得到了名为prometheus-operator-deployment.yaml的文件,此文件是用来创建prometheus-operator的,稍后会用到
- 记得打开文件prometheus-operator-deployment.yaml查看一下,如果里面内容为空(网络问题所致),就需要重新执行上一步操作,请务必要检查,因为太容易出错了!!!
- 第二个文件是prometheus的资源文件,执行以下命令,注意将aabbcc改成您自己的namespace
curl -s https://gitee.com/zq2599/blog_download_files/raw/master/strimzi/prometheus/prometheus.yaml | sed -e 's/namespace: .*/namespace: aabbcc/' > prometheus.yaml
- 执行完上面的命令后,在本地得到了名为prometheus.yaml的文件,此文件是用来创建prometheus的,稍后会用到
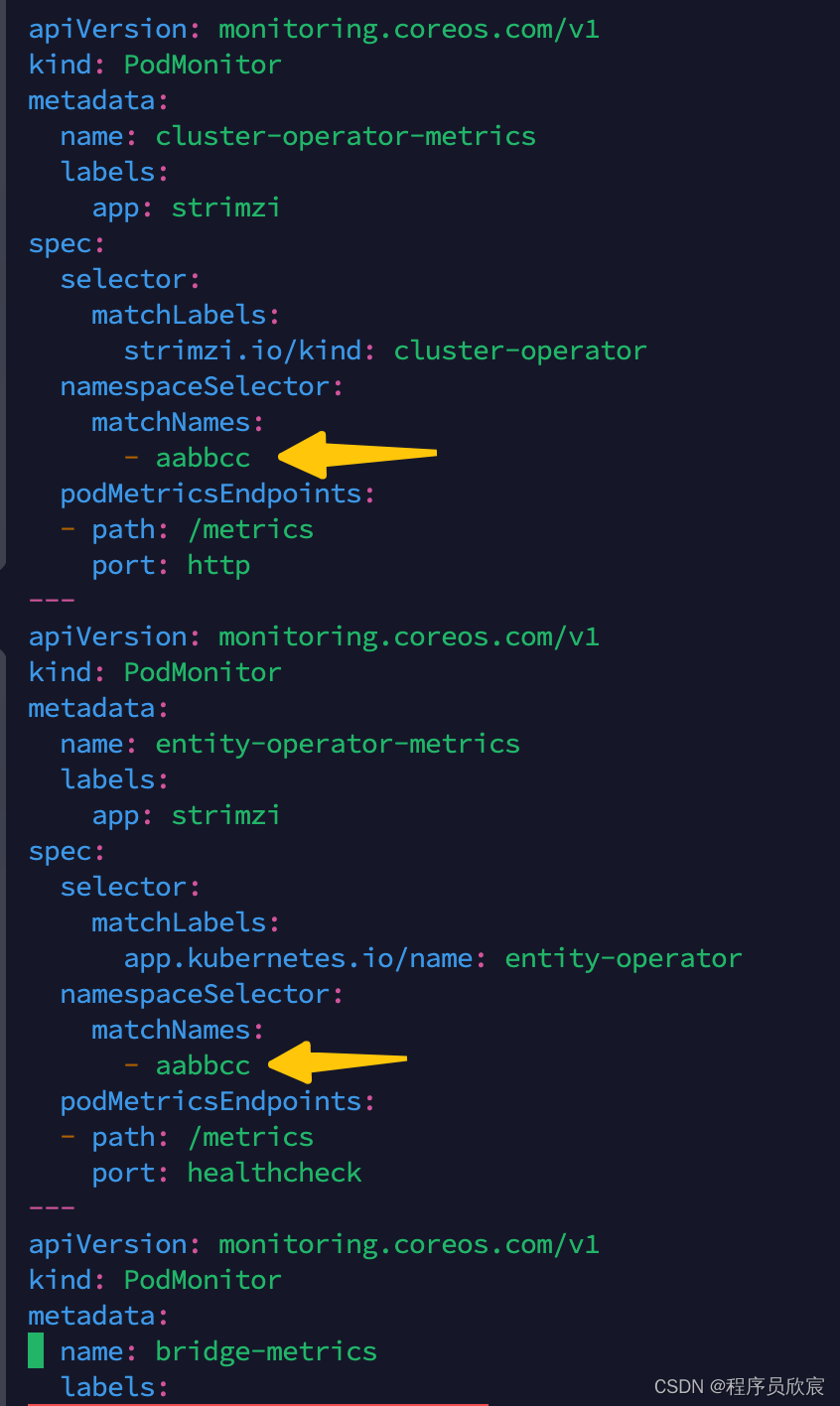
- 第三个文件名为strimzi-pod-monitor.yaml,下载地址:https://gitee.com/zq2599/blog_download_files/raw/master/strimzi/prometheus/strimzi-pod-monitor.yaml
- 第三个文件strimzi-pod-monitor.yaml下载后,要做的修改如下图黄色箭头所示,每个namespaceSelector.matchNames的值都要该成您自己的namespace,一共有四处,请务必要修改正确(我最初操作时grafana一直没有数据,最终发现是漏了这一步导致的)
- 第四个文件名为grafana-service-nodeport.yaml,下载地址:https://gitee.com/zq2599/blog_download_files/raw/master/strimzi/prometheus/grafana-service-nodeport.yaml ,这个是定义了外部访问grafana页面的端口,我这里配置的是31330端口,您可以按照自己的实际情况去修改
- 另外还有三个文件,它们不需要做任何修改,直接下载到本地即可,下载命令如下
wget https://gitee.com/zq2599/blog_download_files/raw/master/strimzi/prometheus/prometheus-additional.yaml
wget https://gitee.com/zq2599/blog_download_files/raw/master/strimzi/prometheus/prometheus-rules.yaml
wget https://gitee.com/zq2599/blog_download_files/raw/master/strimzi/prometheus/grafana.yaml
- 至此,咱们本地一共生成了七个文件,这里用表格对其做说明,请检查确认,以免遗漏
| 编号 | 文件名 | 作用 | 是否需要修改 |
|---|---|---|---|
| 1 | prometheus-operator-deployment.yaml | 创建prometheus-operator | 是 |
| 2 | prometheus.yaml | 创建prometheus | 是 |
| 3 | strimzi-pod-monitor.yaml | prometheus采集pod指标的规则 | 是 |
| 4 | prometheus-additional.yaml | 可以在此增加prometheus的采集job | 否 |
| 5 | prometheus-rules.yaml | 告警规则 | 否 |
| 6 | grafana.yaml | 创建grafana | 否 |
| 7 | grafana-service-nodeport.yaml | grafana的服务配置文件,端口是31330 | 否 |
- 至此,所有文件都准备好了,先执行以下命令创建prometheus-operator,再次提醒,检查prometheus-operator-deployment.yaml的内容,很有可能因为网络问题导致此文件为空,需要重新下载
kubectl create -f prometheus-operator-deployment.yaml
- 执行以下命令完成prometheus和grafana的创建
kubectl apply -f prometheus-additional.yaml
kubectl apply -f strimzi-pod-monitor.yaml
kubectl apply -f prometheus-rules.yaml
kubectl apply -f prometheus.yaml
kubectl apply -f grafana.yaml
kubectl create clusterrolebinding kube-state-metrics-admin-binding \
--clusterrole=cluster-admin \
--user=system:serviceaccount:default:prometheus-server
kubectl apply -f grafana-service-nodeport.yaml
- 上述命令要注意的是:prometheus-operator-deployment.yaml文件太大了,不能用kubectl apply命令,只能用kubectl create命令
- 至此,prometheus+grafana已部署完成,接下来咱们登录grafana,导入dashboard
实际操作之五:在grafana创建数据源
- dashboard就是grafana上的各种监控图表,strimzi为我们提供了几个样例,咱们直接导入即可
- 假设我的kubernetes宿主机的IP地址是192.168.0.1,那么grafana地址就是:192.168.0.1:31330
- 打开页面后,grafana要求输入账号密码,默认的账号和密码都是admin
- 登录后,点击下图黄色箭头位置,将prometheus设置为grafana的数据源
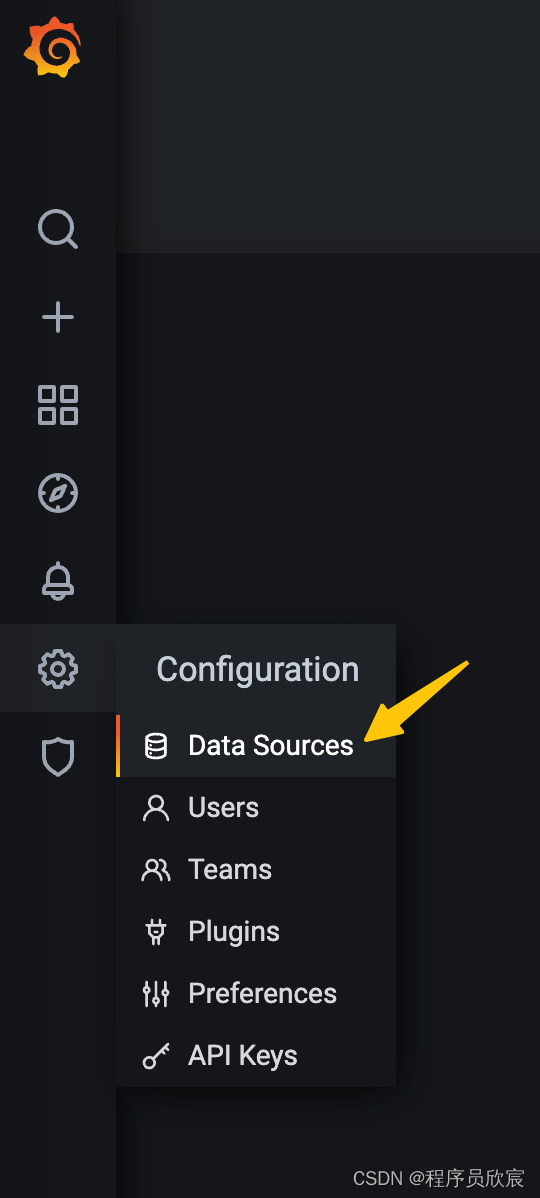
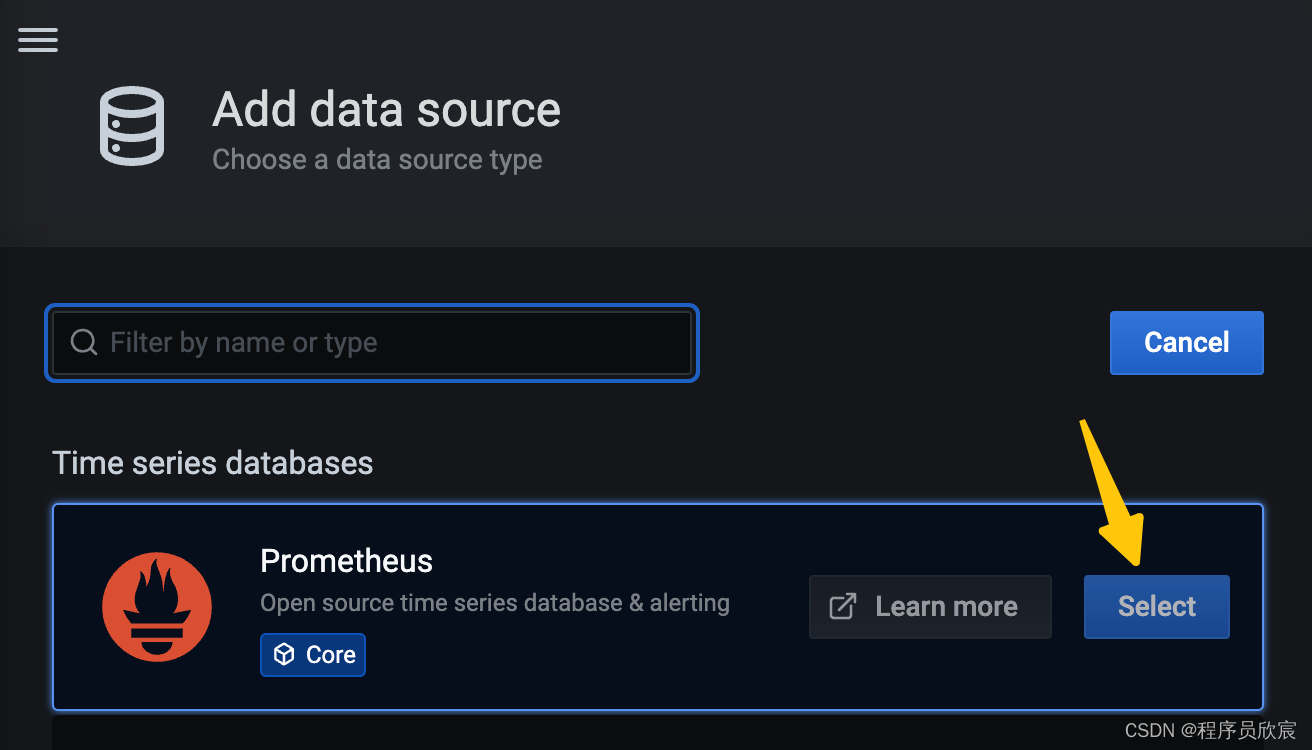
- 类型选择prometheus
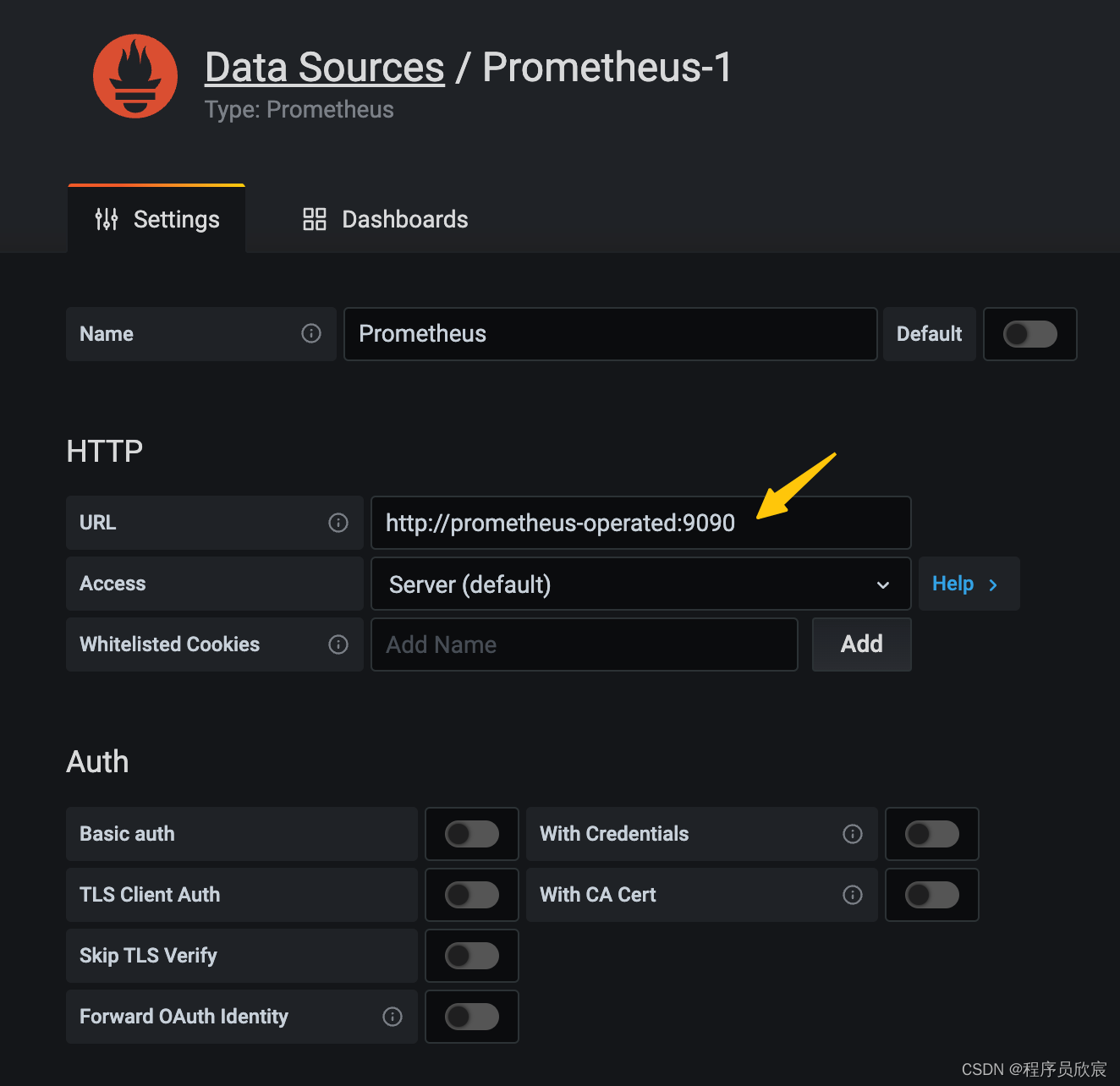
- prometheus地址如下图黄色箭头所示http://prometheus-operated:9090,最后点击底部的Save & Test按钮,就完成了数据源的添加,接下来可以添加dashboard(图表)了
在grafana创建dashboard
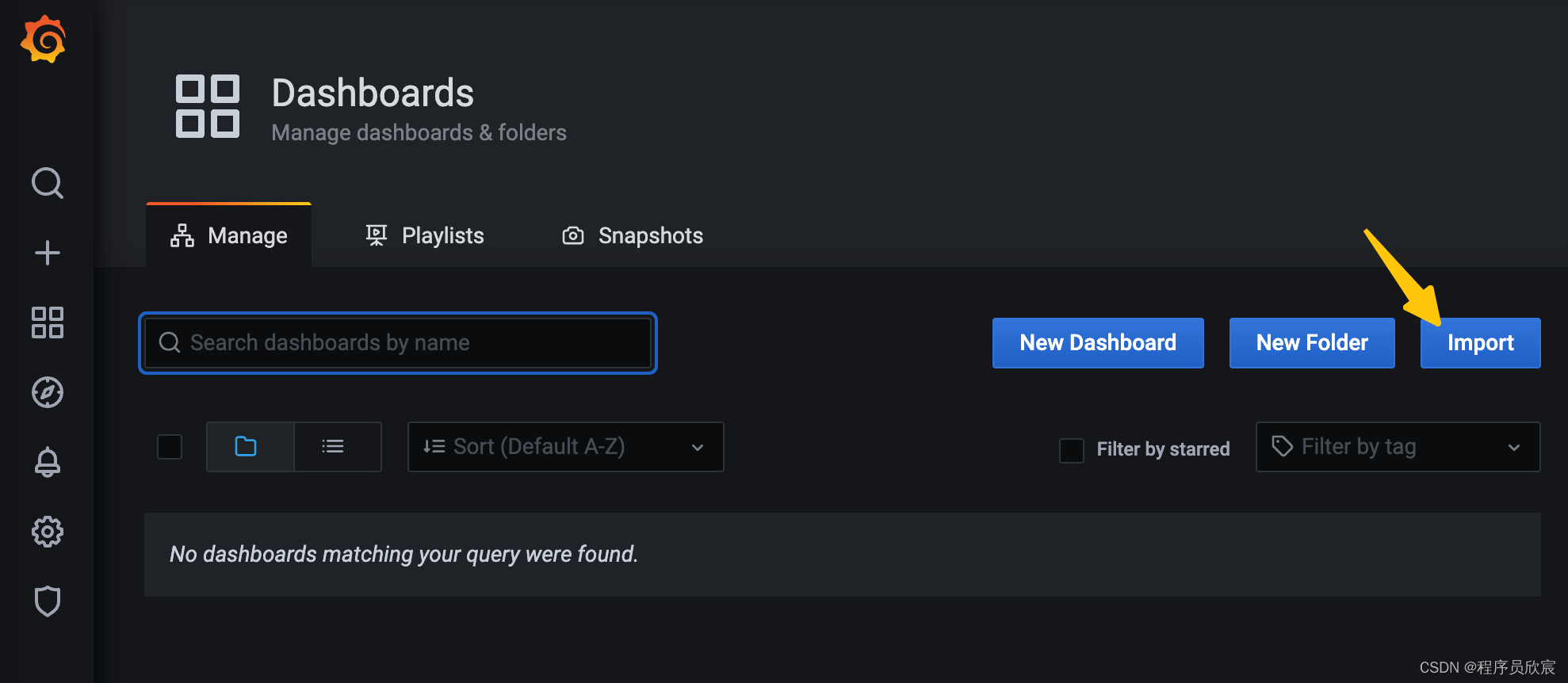
- 现在,咱们只需要在grafana上添加dashboard,就能在页面上监控kafka的各项数据了
- 如下图,点击黄色箭头所指的Import按钮
- 此时会出现导入dashboard的表单,咱们只要把strimzi提供的dashboard数据粘贴到下图黄色箭头所指区域即可
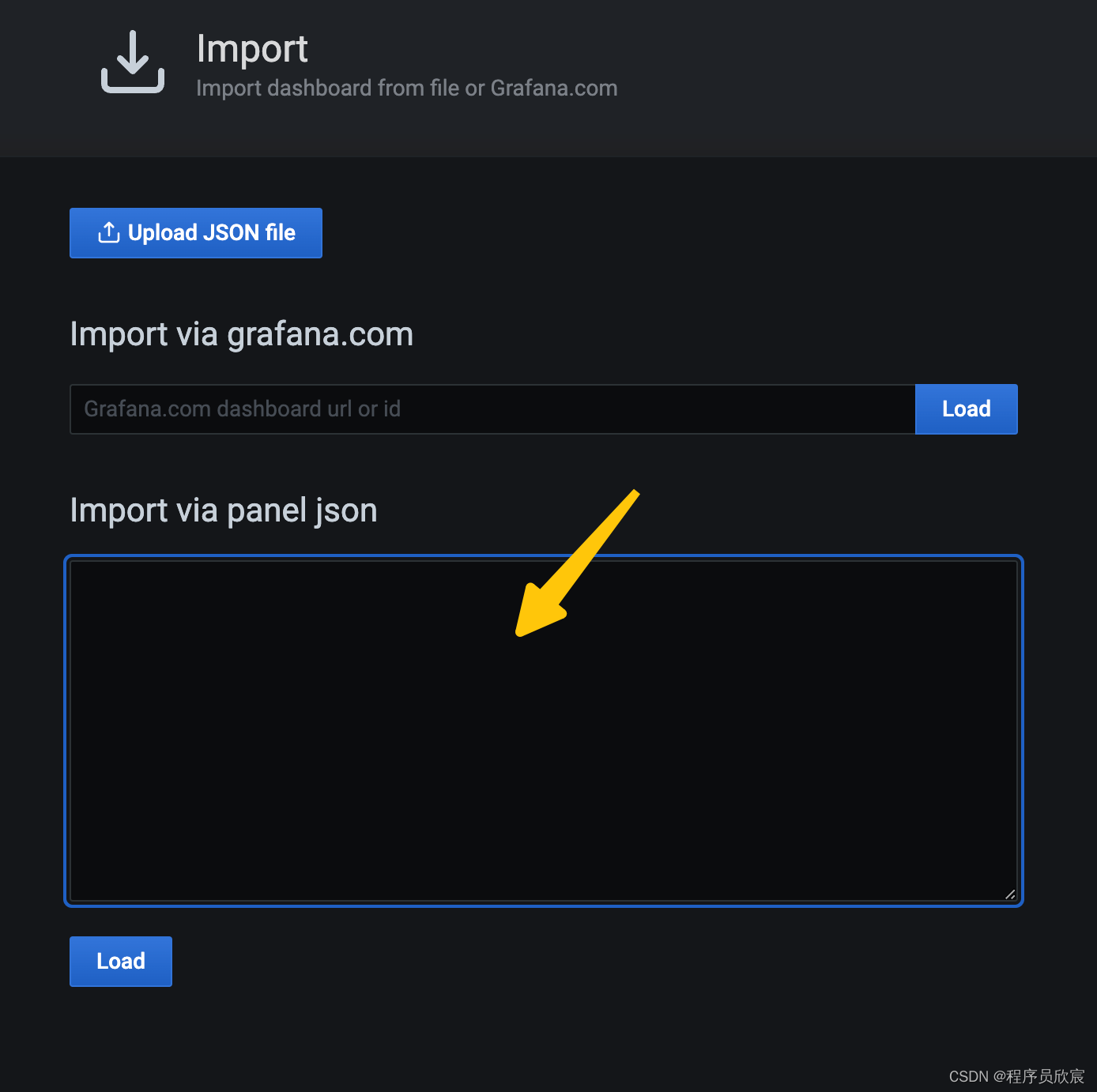
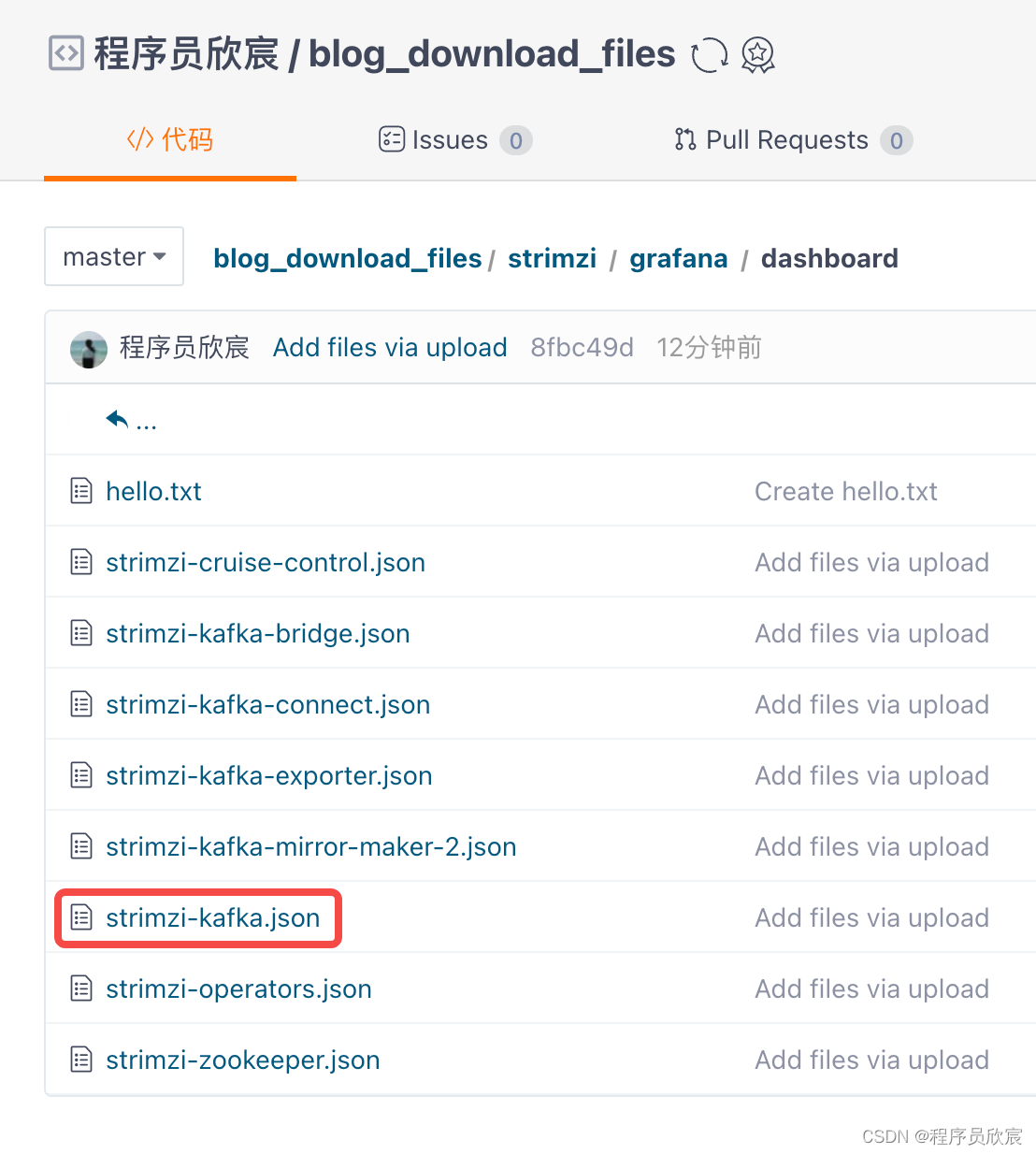
- strimzi提供了丰富的dashboard配置,我已搜集好放在仓库中,地址:https://gitee.com/zq2599/blog_download_files/tree/master/strimzi/grafana/dashboard ,如下图,打开红框中的文件,将其内容复制到上图grafana页面中黄色箭头指向的位置
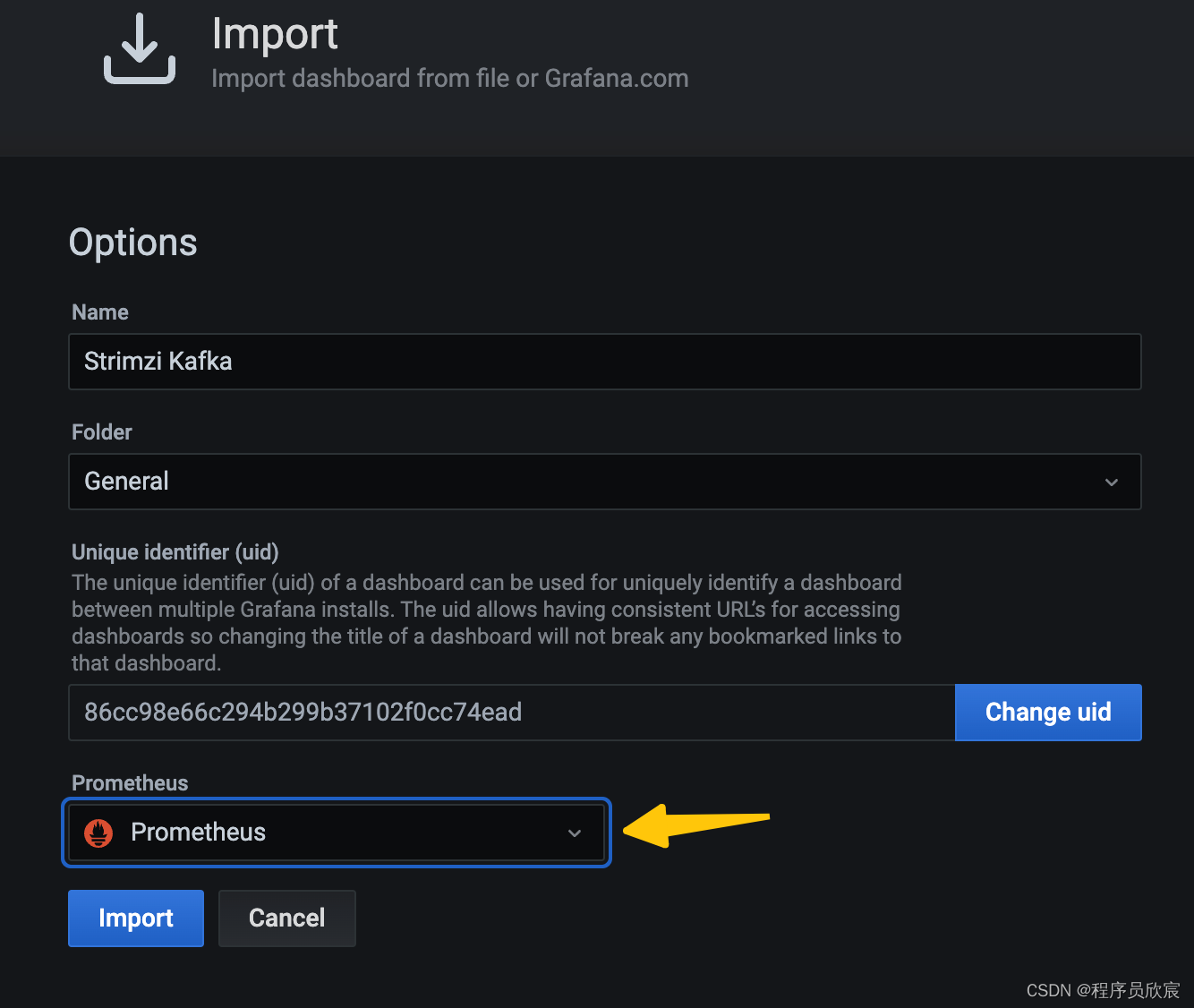
- 注意选择数据源
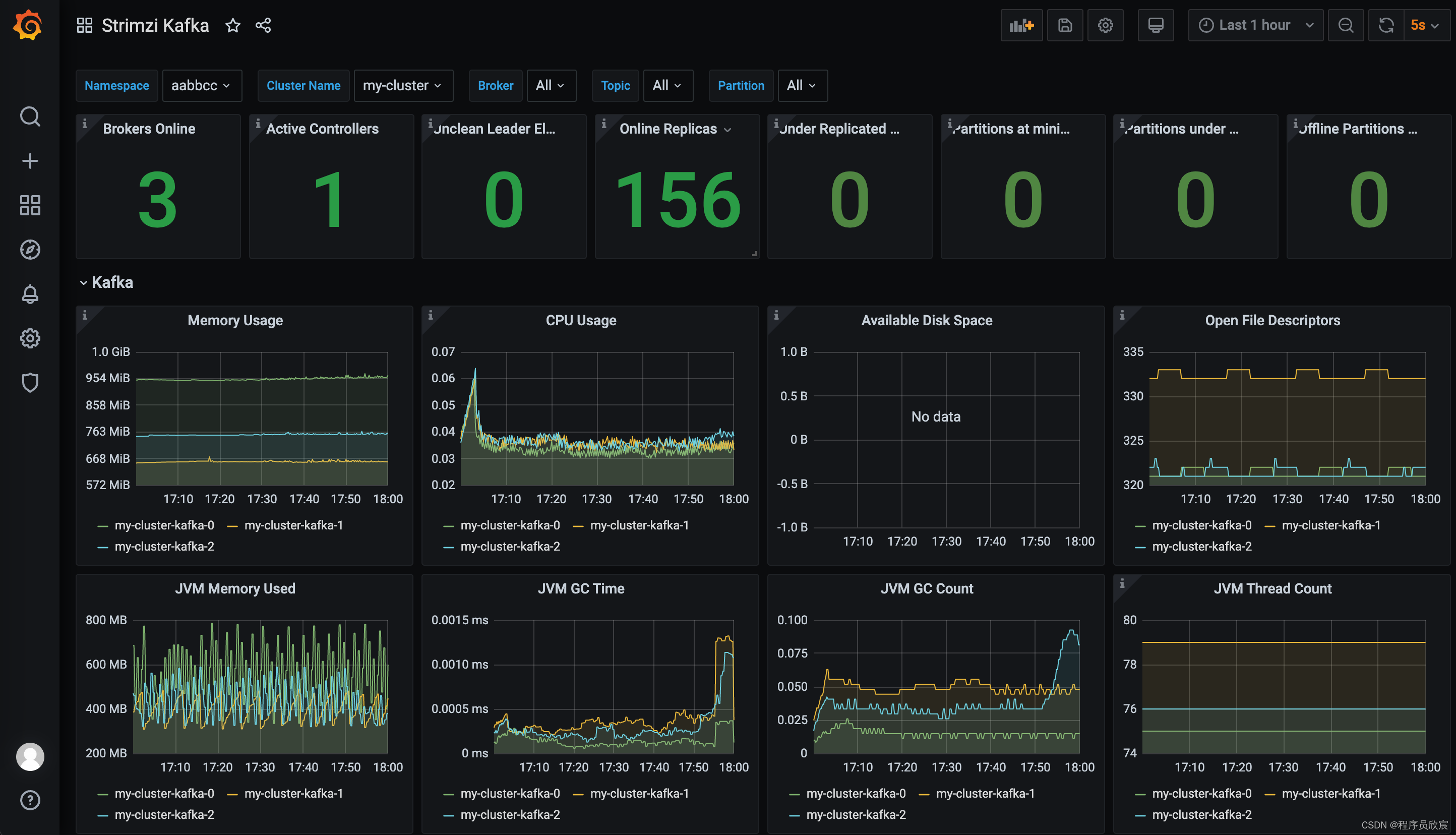
- 配置完成后,就能看到kafka监控信息了
验证
- 接下来咱们生产和消费一些消息,看看grafana显示的数据是否符合预期
- 执行以下命令,进入生产消息的交互模式,输入一些消息(每次回车都会发送一条)
kubectl -n aabbcc \
run kafka-producer \
-ti \
--image=quay.io/strimzi/kafka:0.32.0-kafka-3.3.1 \
--rm=true \
--restart=Never \
-- bin/kafka-console-producer.sh --bootstrap-server my-cluster-kafka-bootstrap:9092 --topic my-topic
- 生产消息的信息很快就在grafa图表中体现出来,如下图
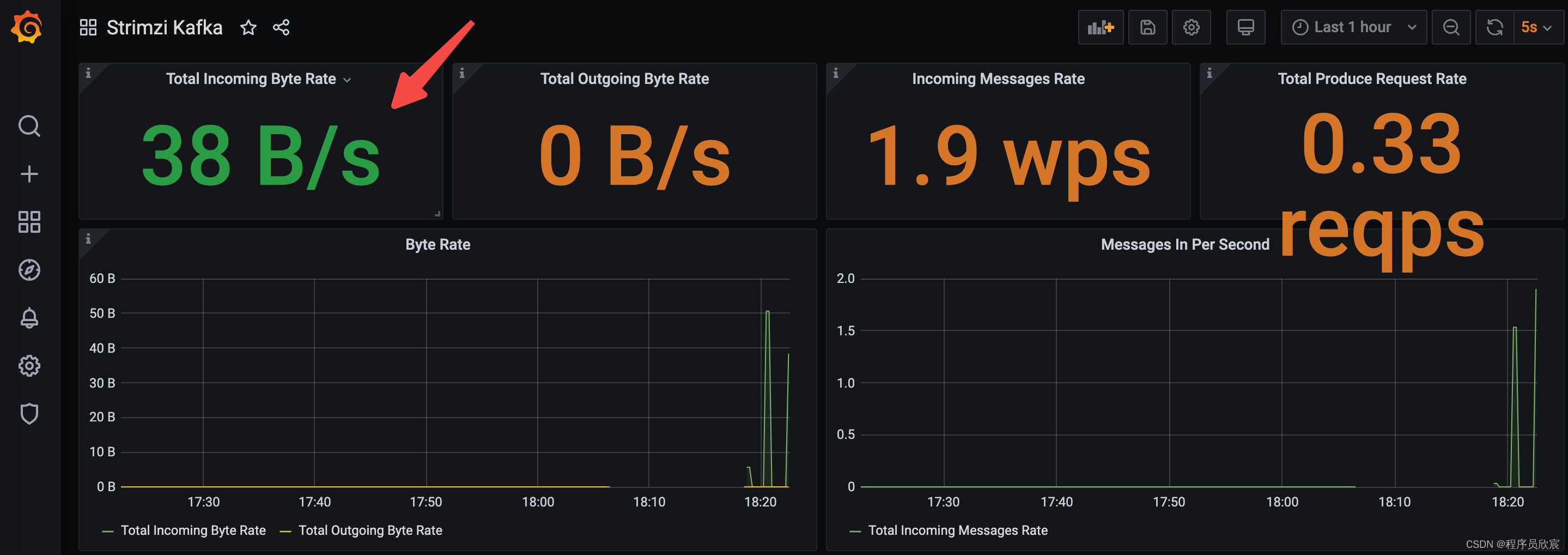
- 再开启一个控制台,执行以下命令消息消息
kubectl -n aabbcc \
run kafka-consumer \
-ti \
--image=quay.io/strimzi/kafka:0.32.0-kafka-3.3.1 \
--rm=true \
--restart=Never \
-- bin/kafka-console-consumer.sh --bootstrap-server my-cluster-kafka-bootstrap:9092 --topic my-topic --from-beginning
- 数十秒后,grafana上就会看见消费消息的指标数据,如下图右侧
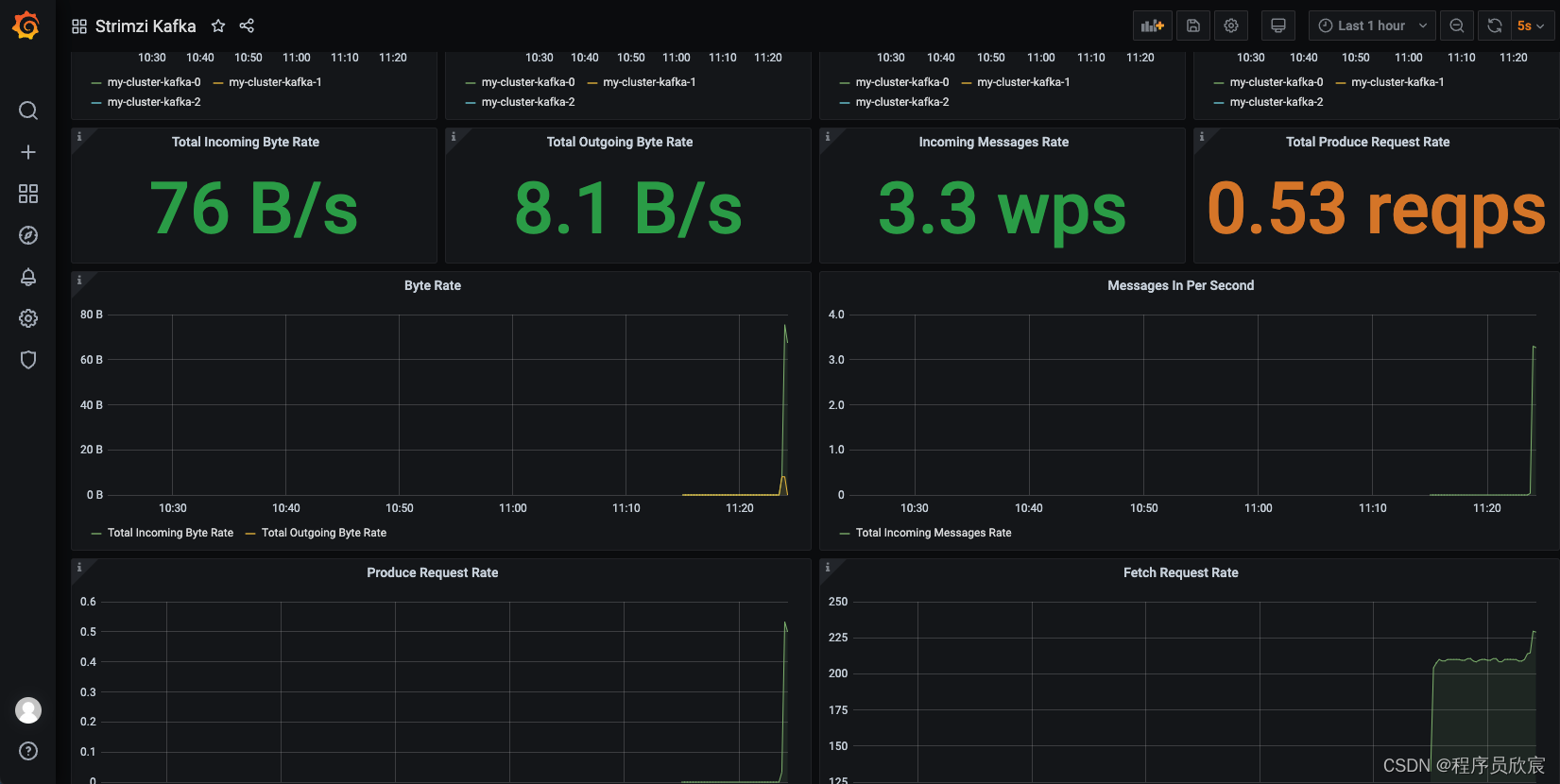
关于prometheus的存储
- 细心的您可能会发现:prometheus采集的数据并没有存储在外部,而是存储在容器内部,这样一旦pod被杀,数据就会丢失,情况确实如此
- prometheus的存储属于prometheus-operator邻域的配置,篇幅所限就不在本篇细说了,这里给出一些参考信息,您可以自己动手试试,如下图,在prometheus.yaml文件中,红色箭头所指位置可以添加pvc,这样就能使用当前kubernetes环境的pv了,grafana的存储配置亦是如此

kafka视图
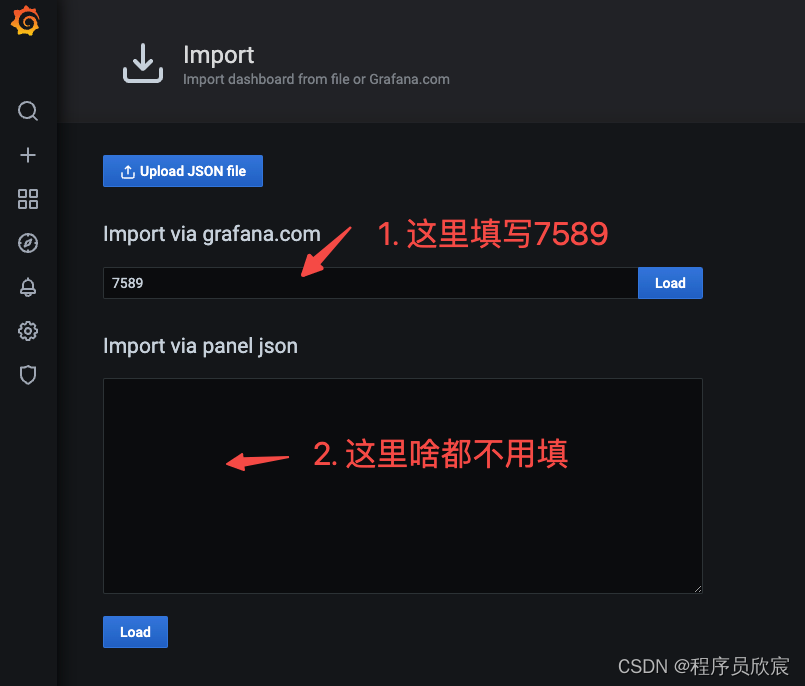
除了strimzi提供的grafana图表,我们还可以使用grabana官网上的kafka图标,最具代表性的应该是Kafka Exporter Overview,导入方法很简单,如下图,在导入表单上输入ID号7589即可(记得点击Load按钮,数据源继续选prometheus)
此dashboard的效果如下
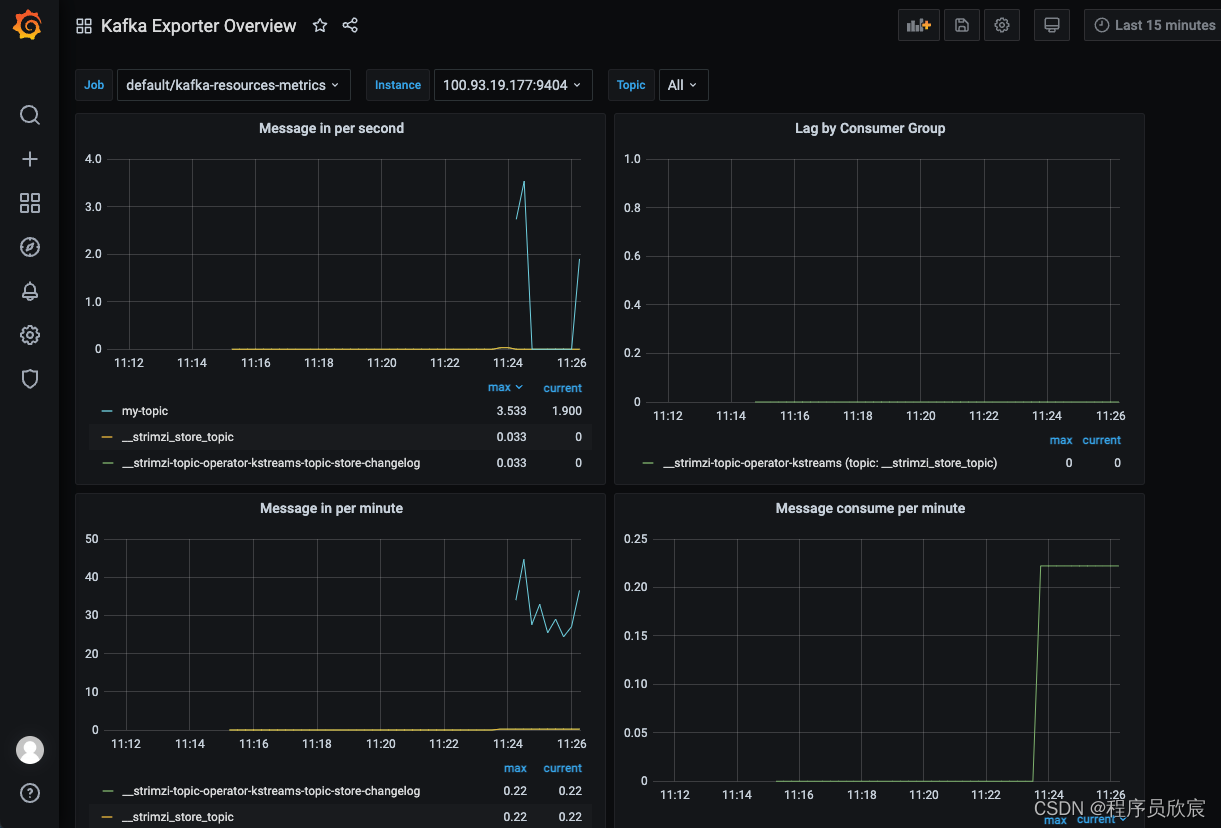
至此,strimzi中部署监控的实战已经完成,希望本篇能给您一些参考,助您顺利完成部署,欢迎您继续关注《strimzi实战》系列,接下来会解锁更多strimzi的神奇能力
欢迎关注博客园:程序员欣宸
strimzi实战之三:prometheus+grafana监控(按官方文档搞不定监控?不妨看看本文,已经踩过坑了)的更多相关文章
- 【知识体系】Kafka文档汇总、组成及架构,配置,常见名词解释,命令行及api操作,官方文档内容,各部分深入,zookeeper和security,监控和运维
〇.相关资料 1.快速搭建文档: 2.详细讲义 3.在线官方文档:http://kafka.apache.org/documentation/ 4.Kafka知识个人总结 5.KafkaPPT汇报 链 ...
- 官方文档 | 【JVM调优体系】「GC底层调优实战」XPocket为终结性能问题而生—开发指南
XPocket 用户文档 XPocket 是PerfMa为终结性能问题而生的开源的插件容器,它是性能领域的乐高,将定位或者解决各种性能问题的常见的Linux命令,JDK工具,知名性能工具等适配成各种X ...
- Spark官方文档 - 中文翻译
Spark官方文档 - 中文翻译 Spark版本:1.6.0 转载请注明出处:http://www.cnblogs.com/BYRans/ 1 概述(Overview) 2 引入Spark(Linki ...
- Spring 4 官方文档学习(十四)WebSocket支持
个人提示:如果需要用到页面推送,高频且要低延迟,WebSocket无疑是最佳选择.否则还是轮询和long polling吧. 做了一个小demo放在码云上,有兴趣的可以看一下,简单易懂:websock ...
- Spark Streaming官方文档学习--上
官方文档地址:http://spark.apache.org/docs/latest/streaming-programming-guide.html Spark Streaming是spark ap ...
- Spring Cloud官方文档中文版-服务发现:Eureka服务端
官方文档地址为:http://cloud.spring.io/spring-cloud-static/Dalston.SR3/#spring-cloud-eureka-server 文中例子我做了一些 ...
- cassandra 3.x官方文档(5)---探测器
写在前面 cassandra3.x官方文档的非官方翻译.翻译内容水平全依赖本人英文水平和对cassandra的理解.所以强烈建议阅读英文版cassandra 3.x 官方文档.此文档一半是翻译,一半是 ...
- 比官方文档更易懂的Vue.js教程!包你学会!
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由蔡述雄发表于云+社区专栏 蔡述雄,现腾讯用户体验设计部QQ空间高级UI工程师.智图图片优化系统首席工程师,曾参与<众妙之门> ...
- Cocos Creator 加载和切换场景(官方文档摘录)
Cocos Creator 加载和切换场景(官方文档摘录) 在 Cocos Creator 中,我们使用场景文件名( 可以不包含扩展名)来索引指代场景.并通过以下接口进行加载和切换操作: cc.dir ...
- 《KAFKA官方文档》入门指南(转)
1.入门指南 1.1简介 Apache的Kafka™是一个分布式流平台(a distributed streaming platform).这到底意味着什么? 我们认为,一个流处理平台应该具有三个关键 ...
随机推荐
- 20200630 excel365 选中一个单元格,对应的行和列都高亮
Excel默认只高亮选中单元格的行标和列标,在整理数据时容易眼花,如能把这一行和列都高亮岂不是更好.方法在此: 1 打开"开发工具"菜单 默认这一项是隐藏的.文件-选项-自定义功能 ...
- 浏览器输入URL到网页完全呈现的过程
前言 临近计算机网络期末考试, 最近在复习(预习), 写一遍博客讲解加深印象. 浏览器输入URL过程图 浏览器输入 URL 过程: 当用户在网页上输入网址 URL 后, 浏览器会对网址进行 DNS 域 ...
- ChatGPT+Mermaid自然语言流程图形化产出小试
ChatGPT+Mermaid语言实现技术概念可视化 本文旨在介绍如何使用ChatGPT和Mermaid语言生成流程图的技术.在现代软件开发中,流程图是一种重要的工具,用于可视化和呈现各种流程和结构. ...
- (内附示例源码)如何通过electron构建桌面跨平台音视频应用
近年来,视频直播.直播带货.在线教育.在线医疗等音视频领域的相关行业都非常热门,成为大众瞩目的焦点. 在不久的将来,音视频技术渗透于各行各业,无处不在.从IoT网络到个人用户的移动设备,音视频技术以不 ...
- 筛选出N以内的素数
解题思路:1.素数是指在大于1的自然数中,除了1和它本身以外不再有其他因数的自然数.(也就是只有 1 和它本身能整除)2.利用两个for循环来判断素数. 注意事项:1.注意for添加花括号.2.注意输 ...
- dash构建多页应用
dash 构建多页面应用一种方案 本方案对dash官网多页面案例使用dash_bootstrap_components案例进行优化与测试,效果如下 项目代码结构如下 │ app.py │ ├─asse ...
- YOLOv6在LabVIEW中的推理部署(含源码)
前言 YOLOv6 是美团视觉智能部研发的一款目标检测框架,致力于工业应用.如何使用python进行该模型的部署,官网已经介绍的很清楚了,但是对于如何在LabVIEW中实现该模型的部署,笔者目前还没有 ...
- Go语言中指针详解
指针在 Go 语言中是一个重要的特性,它允许你引用和操作变量的内存地址.下面是指针的主要作用和相关示例代码: 1. 引用传递 在 Go 中,所有的变量传递都是值传递,即复制变量的值.如果你想在一个函数 ...
- mysql根据mysqlbinlog恢复找回被删除的数据库
年初和朋友一起做了个项目,到现在还没收到钱呢,今天中午时候突然听说之前的数据库被攻击了,业务数据库全部被删除.看有没有什么办法恢复,要是恢复不了,肯定也别想拿钱了吧? README FOR RECOV ...
- Visual Studio常用快捷键(附带免费PDF)
前言 对于开发者而言,熟悉快捷键的使用,能够起到事半功倍的作用,提高工作效率.以下是我整理的一份Visual Studio常用快捷键清单,希望能够帮助到你. 常用快捷方式 快捷键 功能 Ctrl + ...