NLP复习之神经网络
NLP复习之神经网络
前言
tips:
- 设计神经网络时,输入层与输出层节点数往往固定,中间层可以自由指定;
- 神经网络中的拓扑与箭头代表预测过程数据流向,与训练的数据流有一定区别;
- 我们不妨重点关注连接线,因为它们是权重,是要训练得到的
神经元
神经元模型是一个包含输入、输出、计算功能的模型,注意中间的箭头线,称之为“连接”,上面有“权值”
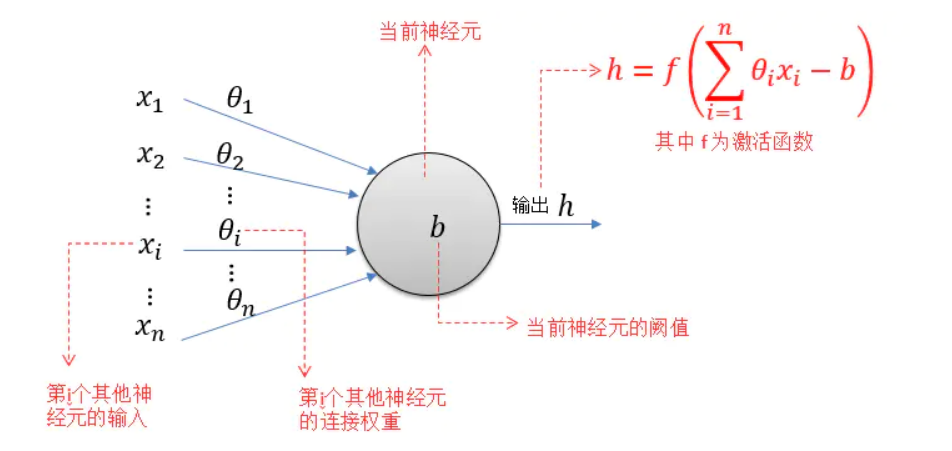
一个神经网络的训练算法就是让权重的值调整到最佳,以使得整个网络的预测效果最好。
MP神经元模型接收来自n个其他神经元传递过来的输入信号(x1~xn),这些输入信号通过带权重(θ或ω来表示权重,上图采用θ)的连接(Connection)进行传递,然后神经元(图示阈值为b)收到的总输入(所有输入和权重的乘积的和)与神经元的阈值b比较,并经由激活函数(Activation Function,又称响应函数)处理之后产生神经元的输出。
理想情况下,激活函数的形式应为阶跃函数(也就是修正线性单元ReLU),通常选择Sigmoid函数:
\]
其值域为\((0,1)\)。
神经元可以看做一个计算与存储单元,计算是神经元对其的输入进行计算,存储是神经元会暂存计算结果,传递到下一层。
多层神经网络
单层神经网络(感知机)在此处暂时忽略不写,期末要挂科了

上图展现了基本两层神经网络,其中\(x_i(i=1, 2, 3)\)为输入层值,\(a_i^{(k)}(k=1, 2, \dots, K; i = 1, 2, 3, \dots, N_k)\)表示第k层中,第i个神经元的激活值,\(N_k\)表示第k层的神经元个数。当k=1时,即为输入层,即\(a_i^{(1)}=x_i\),而\(x_0=1\)和\(a_0^{(2)}=1\)为偏置项
为了求最后的输出值\(h_{\theta}(x)=a_1^{(3)}\),我们需要计算隐藏层中每个神经元的激活值\(a_{ji}^{(k)}(k=2,3)\),而隐藏层/输出层的每一个神经元,都是由上一层神经元经过类似逻辑回归计算得到。
反向传播(BP算法)
给出一个示例,是我们的作业题目

(1)在该例子中什么是输入层,隐藏层,输出层,并对不同的层和层之间的权重矩阵进行维度标记。
(2)使用链式法则,在损失函数L上,分别对\(z^{[2]},z^{[1]}_1,z^{[1]}_2,x_1,x_2\),进行求偏导
解
(1)
输入层:\(x_1,x_2\),维度为\(2 \times 1\);
输入层与隐藏层之间的权重矩阵:\(w_{11}^{[1]},w_{12}^{[1]},w_{21}^{[1]},w_{22}^{[1]}\),维度为\(2 \times 2\);
经过加权求和与偏置后,得到:\(z_1^{[1]},z_2^{[1]}\),维度为\(2 \times 1\);
经过ReLU激活函数后得到隐藏层:\(a_1^{[1]},a_2^{[1]}\),维度为\(2 \times 1\);
隐藏层与输出层之间的权重矩阵:\(w_{11}^{[2]},w_{12}^{[2]}\),维度为\(1 \times 2\);
经过加权求和与偏置后,得到:\(z^{[2]}\),维度为\(1 \times 1\);
经过sigmoid激活函数后得到输出层:\(a^{[2]}\),维度为\(1 \times 1\)。
(2)
损失函数:
\]
所有表达式:
a^{[2]} &= \sigma{(z^{[2]})} \\
z^{[2]} &= w_{11}^{[2]}a_1^{[1]} + w_{12}^{[2]}a_2^{[1]} + b_1^{[2]} \\
a_1^{[1]} &= ReLU(z_1^{[1]}) \\
a_2^{[1]} &= ReLU(z_2^{[1]}) \\
z_1^{[1]} &= w_{11}^{[1]}x_1 + w_{12}^{[1]}x_2 + b_1^{[1]} \\
z_2^{[1]} &= w_{21}^{[1]}x_1 + w_{22}^{[1]}x_2 + b_2^{[1]}
\end{aligned}
\]
阶段求导:
\frac{\partial L}{\partial a^{[2]}} &= - [\frac{y}{a^{[2]}} + \frac{y - 1}{1 - a^{[2]}}] \\
\frac{\partial a^{[2]}}{\partial z^{[2]}} &= \sigma{(z^{[2]})}(1-\sigma{(a^{[2]})}) = a^{[2]}(1 - a^{[2]}) \\
\frac{\partial z^{[2]}}{\partial a_1^{[1]}} &= w_{11}^{[2]} \\
\frac{\partial z^{[2]}}{\partial a_2^{[1]}} &= w_{12}^{[2]} \\
\frac{\partial a_1^{[1]}}{\partial z_1^{[1]}} &= \begin{cases} 0,\text{for } z_1^{[1]} < 0 \\ 1,\text{for } z_1^{[1]} \geq 0 \end{cases} \\
\frac{\partial a_1^{[1]}}{\partial z_2^{[1]}} &= \begin{cases} 0,\text{for }
z_2^{[1]} < 0 \\ 1, \text{for } z_2^{[1]} \geq 0 \end{cases} \\
\frac{\partial z_1^{[1]}}{\partial x_1} &= w_{11}^{[1]},\frac{\partial z_1^{[1]}}{\partial x_2} = w_{12}^{[1]},\frac{\partial z_2^{[1]}}{\partial x_1} = w_{21}^{[1]},\frac{\partial z_2^{[1]}}{\partial x_2} = w_{22}^{[1]}
\end{aligned}
\]
链式求导:

NLP复习之神经网络的更多相关文章
- zz【清华NLP】图神经网络GNN论文分门别类,16大应用200+篇论文最新推荐
[清华NLP]图神经网络GNN论文分门别类,16大应用200+篇论文最新推荐 图神经网络研究成为当前深度学习领域的热点.最近,清华大学NLP课题组Jie Zhou, Ganqu Cui, Zhengy ...
- NLP教程(3) | 神经网络与反向传播
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
- 斯坦福NLP课程 | 第11讲 - NLP中的卷积神经网络
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- 斯坦福NLP课程 | 第18讲 - 句法分析与树形递归神经网络
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- 斯坦福NLP课程 | 第2讲 - 词向量进阶
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- NLP教程(6) - 神经机器翻译、seq2seq与注意力机制
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
- 在 TensorFlow 中实现文本分类的卷积神经网络
在TensorFlow中实现文本分类的卷积神经网络 Github提供了完整的代码: https://github.com/dennybritz/cnn-text-classification-tf 在 ...
- 在TensorFlow中实现文本分类的卷积神经网络
在TensorFlow中实现文本分类的卷积神经网络 Github提供了完整的代码: https://github.com/dennybritz/cnn-text-classification-tf 在 ...
- 斯坦福NLP课程 | 第1讲 - NLP介绍与词向量初步
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- NLP教程(2) | GloVe及词向量的训练与评估
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
随机推荐
- MapStruct使用
1.首先创建一个maven项目 2.导入相关的依赖 注意:lombok的版本 <?xml version="1.0" encoding="UTF-8"?& ...
- SpringBoot项目整合微信登录
一.开通微信登录 去微信开发者平台 1.注册 2.邮箱激活 3.完善开发者资料 4.开发者资质认证 准备营业执照,1-2个工作日审批.300元 5.创建网站应用 6.提交审核,7个工作日审批 7.熟悉 ...
- LeetCode15:三数之和(双指针)
解题思路:常规解法很容易想到O(n^3)的解法,但是,n最大为1000,很显然会超时. 如何优化到O(n^2),a+b+c =0,我们只需要判断 a+b的相反数是否在数组中出现,而且元素的取值范围在 ...
- LeetCode456:132模式(单调栈)
解题思路:根据题意,我们首先首先要找到所有的极大值点,同时记录当前极大值点的左边的最小值.遍历所有点,看是否能够满足132条件.虽然记录极大值点的地方可以优化,减小比较的次数,但是由于我们不知道极大值 ...
- 安装了华企盾DSC防泄密,所有进程的加密文件都无法打开
用pchunter等工具查看系统回调中是否有文件厂商不存在的(system目录的除外),在恢复模式删除掉,或者用360系统急救箱查杀一下
- adobe全家桶破解网站
原文链接:https://baiyunju.cc/8602 总有一些国内.外的大神在破解Adobe全家桶软件,包括Windows.Mac系统最新版的2021.2022版PS.AI.PR.PL.ME.I ...
- IDEA Edit Configuration解决隐藏了不见了
IDEA Edit Configuration解决隐藏了不见了 IDEA Edit Configuration解决隐藏了不见了,我的IDEA版本是2020.3.4,某天按了哪个快捷键导致不见了.按Al ...
- NoClassDefFoundError: javax/el/ELManager
Caused by: java.lang.NoClassDefFoundError: javax/el/ELManager at org.hibernate.validator.messageinte ...
- Java播放MP3播放音频
Java播放MP3播放音频 下面我演示用jdk自带包.框架等分别展示播放mp3.等music 一.使用javafx包 AudioClip 注意jdk11以上剥离了javafx public stati ...
- 计算机网络分层结构--OSI模型、TCP/IP 模型、五层模型
计算机网络分层结构 OSI参考模型与TCP/IP参考模型 五层参考模型