[转帖]可直接拿来用的kafka+prometheus+grafana监控告警配置
kafka配置jmx_exporter
点击:https://github.com/prometheus/jmx_exporter,选择下面的jar包下载:

将下载好的这个agent jar包上传到kafka的broker节点所在服务器上,每个broker都需要,比如上传到如下路径:
/opt/agent/jmx_prometheus_javaagent-0.16.1.jar
修改kafka启动脚本: bin/kafka-server-start.sh,增加java agent配置如下:
-
JMX_EXPORTER_OPTS="-javaagent:/opt/agent/jmx_prometheus_javaagent-0.16.1.jar=9095:/opt/agent/kafka_broker.yml"
-
export KAFKA_JMX_OPTS="$KAFKA_JMX_OPTS $JMX_EXPORTER_OPTS"
这两行代码可以添加在脚本首部。
这里指定了9095作为端口,jmx_exporter用到的kafka_broker.yml 配置如下:https://github.com/xxd763795151/kafka-exporter/blob/main/kafka_broker.yml
将kafka每个broker都这样配置,重启kafka。
Prometheus配置
修改prometheus的配置prometheus.yml,增加如下配置:
-
- job_name: 'kafka'
-
metrics_path: /metrics
-
static_configs:
-
- targets: ['kafka1:9095', 'kafka2:9095', 'kafka3:9095']
-
labels:
-
env: "test"
p.s. 注意job_name不要修改,值就是"kafka",要不我下面的grafana不能直接用,还需要每个面板依次修改。
Grafana配置
下面的Grafana面板我已经配置好,可以直接拿来用,之后可以根据需要增加或删除相关面板:https://github.com/xxd763795151/kafka-exporter/blob/main/grafana.json
贴几个截图:
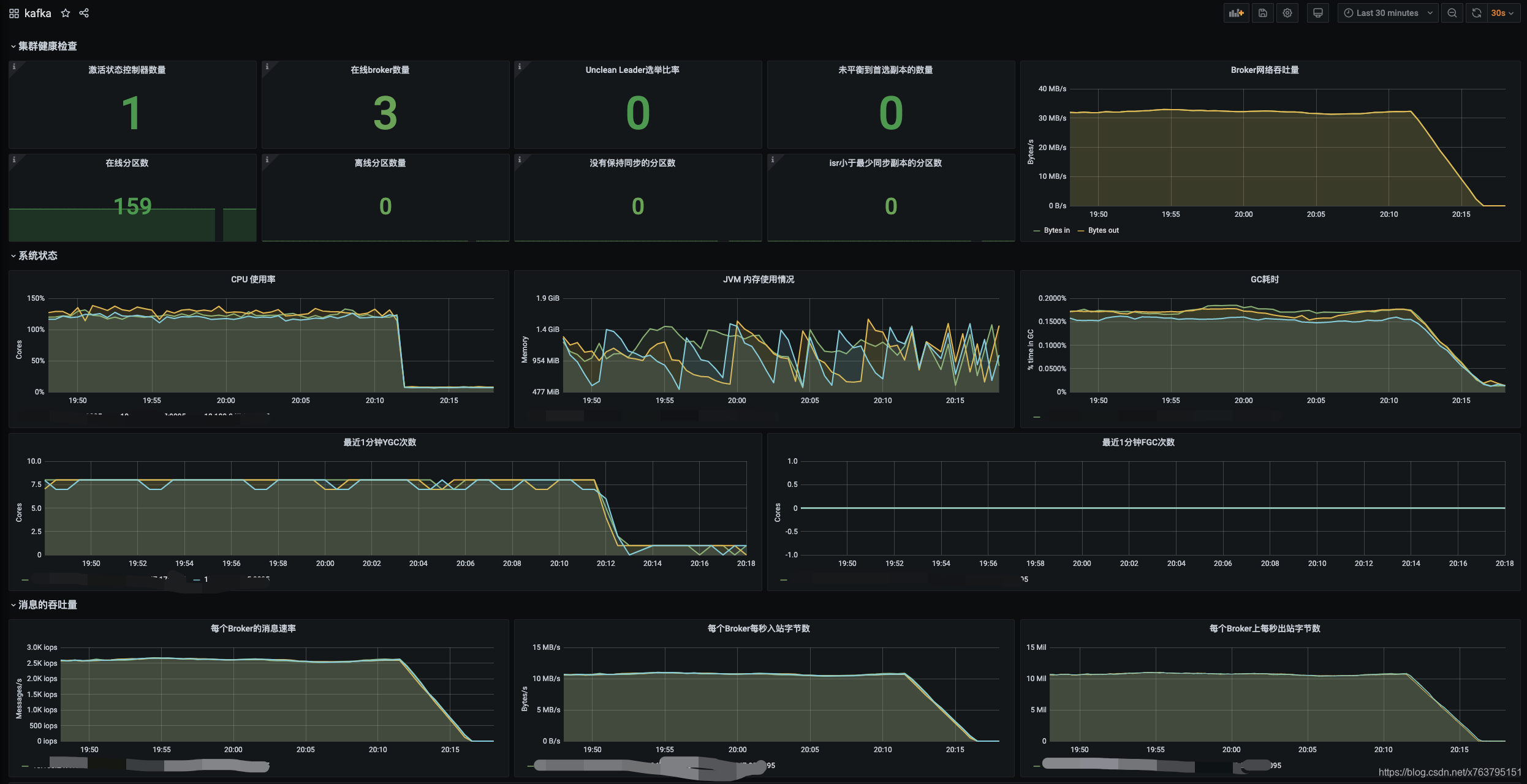
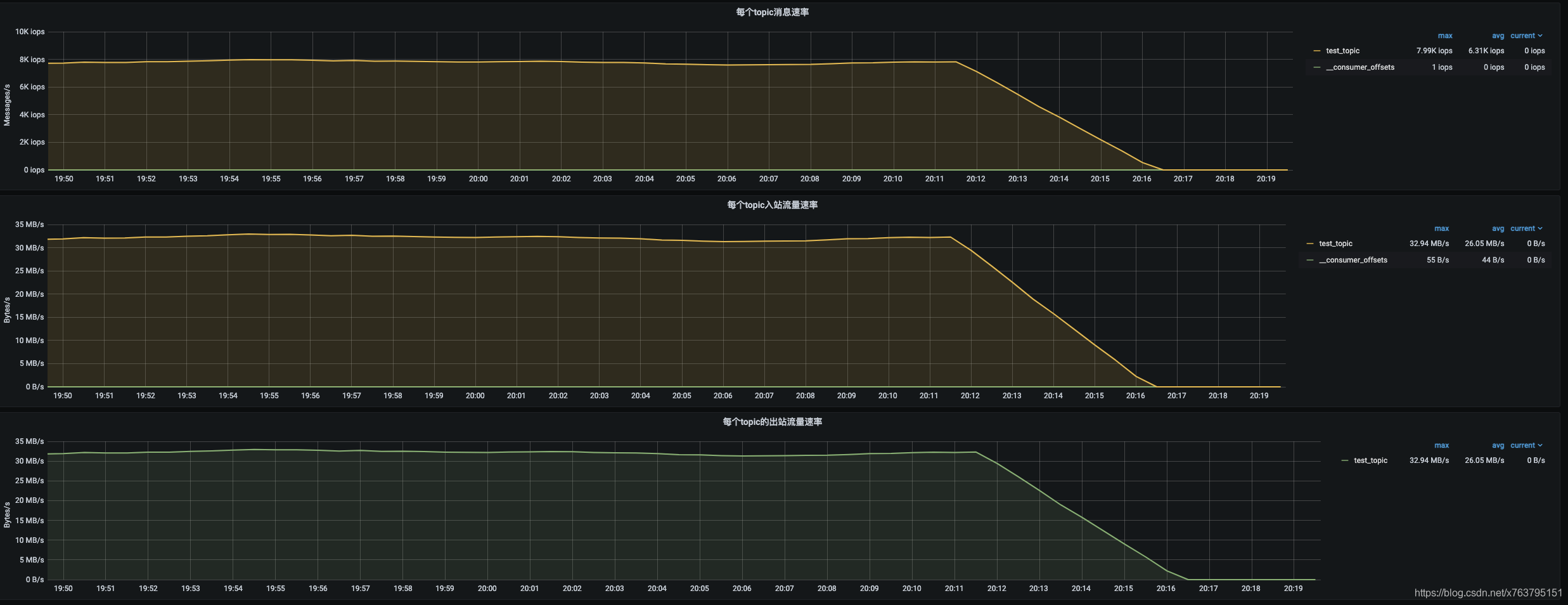

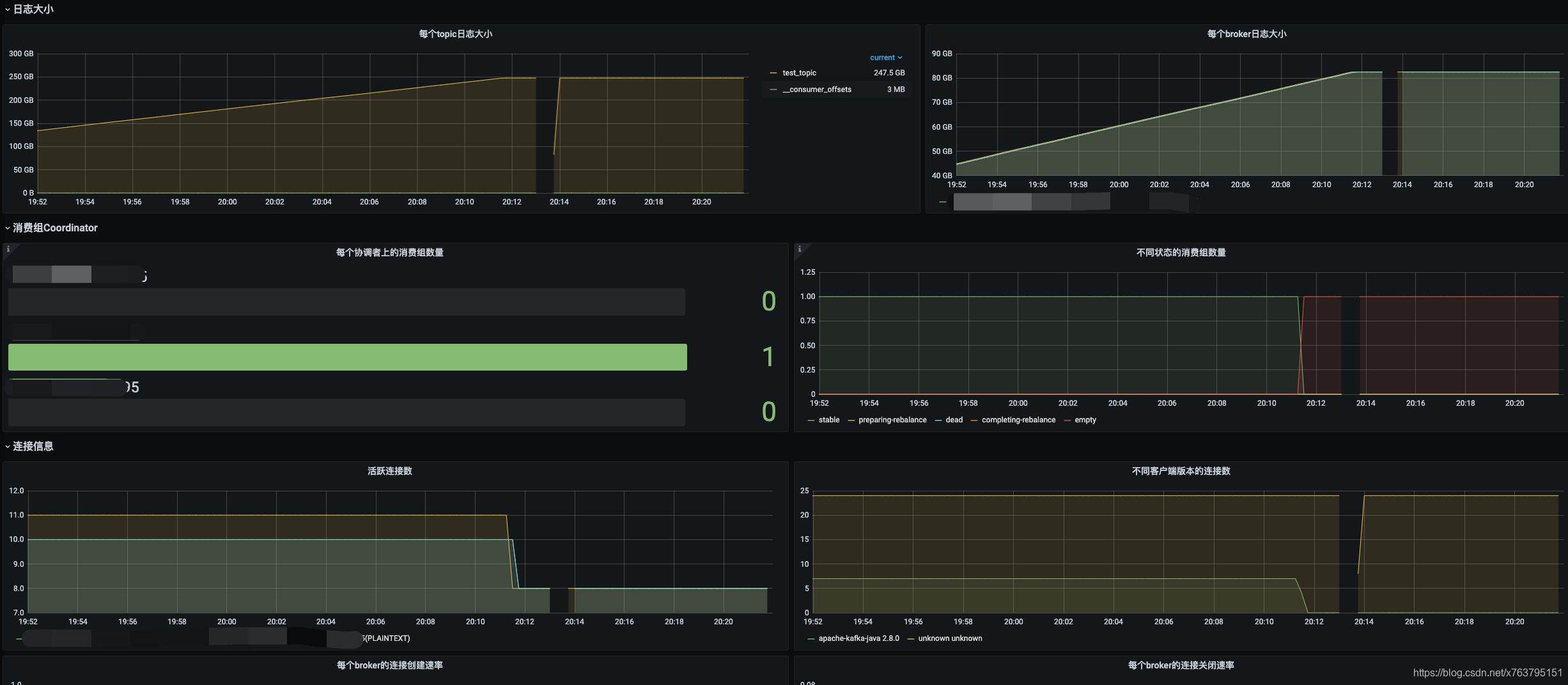
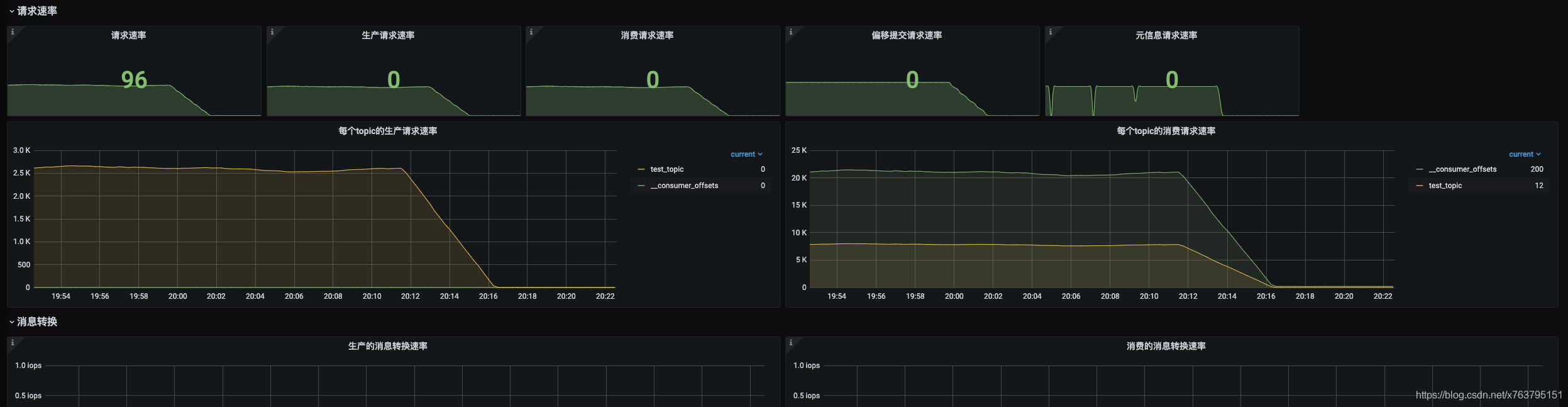
消息积压
在kafka的broker端无法直接获取消息积压等指标信息,这些数据在消费端上,我们也不太可能去连接所有的消费端获取监控信息。
所以,我单独写了一个kafka-exporter可以获取消息积压的监控指标:https://github.com/xxd763795151/kafka-exporter
点击这个链接进入github仓库后,根据说明进行部署并配置启动后,然后在prometheus.yml增加如下配置:
-
- job_name: 'kafka-exporter'
-
metrics_path: /prometheus
-
static_configs:
-
- targets: ['kafka-expoter-host:9097']
-
labels:
-
env: "test"
上面的grafana配置里已经包含了消息积压的面板:
 如果后续有其它指标在jmx里不提供,也可以继续补充kafka-exporter,刮取更多需要的metrics。
如果后续有其它指标在jmx里不提供,也可以继续补充kafka-exporter,刮取更多需要的metrics。
告警
最新的配置代码会提交在这里: https://github.com/xxd763795151/kafka-exporter/blob/main/kafka_alert.yml
示例如下:

末语
我从grafana 官方上搜索了几个dashboard,但指标实在太少。感谢从这篇博文里找到的grafana配置可以参考,提供了很多指标的面板,可以让我对着kafka官方监控jmx说明进行整理,让我在grafana面板的配置上,省了一半的功夫:
https://www.confluent.io/blog/monitor-kafka-clusters-with-prometheus-grafana-and-confluent/
[转帖]可直接拿来用的kafka+prometheus+grafana监控告警配置的更多相关文章
- [转帖]Prometheus+Grafana监控Kubernetes
原博客的位置: https://blog.csdn.net/shenhonglei1234/article/details/80503353 感谢原作者 这里记录一下自己试验过程中遇到的问题: . 自 ...
- [转帖]安装prometheus+grafana监控mysql redis kubernetes等
安装prometheus+grafana监控mysql redis kubernetes等 https://www.cnblogs.com/sfnz/p/6566951.html plug 的模式进行 ...
- [转帖]插曲:大白话带你认识Kafka
插曲:大白话带你认识Kafka 2019-11-18 21:58:27 从事Java 阅读数 2更多 分类专栏: java Kafaka 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA ...
- [转帖]基于docker 搭建Prometheus+Grafana
基于docker 搭建Prometheus+Grafana https://www.cnblogs.com/xiao987334176/p/9930517.html need good study 一 ...
- [转帖]Linux网络管理员不得不了解的系统目录/proc/sys/net/(网络配置)
Linux网络管理员不得不了解的系统目录/proc/sys/net/(网络配置) https://blog.csdn.net/u013485792/article/details/76416836 需 ...
- [ZZ] [精彩盘点] TesterHome 社区 2018年 度精华帖
原文地址: https://testerhome.com/topics/17646 相逢即是缘分,总有一篇适合您! 感觉好的请点赞收藏 ,感觉分类不严谨的,欢迎反馈给我! 测试方法&测试管理 ...
- 《转》Spring4 Freemarker框架搭建学习
这里原帖地址:http://www.cnblogs.com/porcoGT/p/4537064.html 完整配置springmvc4,最终视图选择的是html,非静态文件. 最近自己配置spring ...
- Windows 7 封装与定制不完全教程
Windows 7 封装与定制不完全教程 从定制Win7母盘到封装详细教程 手把手教你定制WIN7小母盘 Windows 7 封装与定制不完全教程 [教程] Windows 7 封装与定制不完全教程( ...
- Open Source
资源来源于http://www.cnblogs.com/Leo_wl/category/246424.html RabbitMQ 安装与使用 摘要: RabbitMQ 安装与使用 前言 吃多了拉就是队 ...
- 你都用python来做什么?
首页发现话题 提问 你都用 Python 来做什么? 关注问题写回答 编程语言 Python 编程 Python 入门 Python 开发 你都用 Python 来做什么? 发现很 ...
随机推荐
- ClickHouse的JOIN算法选择逻辑以及auto选项
ClickHouse的JOIN算法选择逻辑以及auto选项 ClickHouse中的JOIN的算法有6种: Direct; Partial merge; Hash; Grace hash; Full ...
- vue部署项目报错导致空白页解决
在nginx上部署项目出现空白页并报错 解决方法: 在vue的vue.config.js文件中 改成:module.exports = {publicPath: './'}
- Draco使用笔记(1)——图形解压缩
目录 1. 概述 2. 详论 2.1. 工具 2.2. 代码 1. 概述 Draco是Google开发的图形压缩库,用于压缩和解压缩3D几何网格(geometric mesh)和点云(point cl ...
- 为什么程序猿DD热衷于内容输出与分享?
一.热衷于内容输出与分享 我是程序猿DD,大家知道我热衷于内容输出与分享.比如我一直有在产出博客或维护开源项目,是因为平时不沉迷游戏或追剧,空下来就喜欢整理整理最近碰到的问题,那么写写博客正好是一种比 ...
- 华为云CCE集群健康中心:一个有专家运维经验的云原生可观测平台
本文分享自华为云社区<新一代云原生可观测平台之华为云CCE集群健康中心>,作者:云容器大未来. "Kubernetes运维确实复杂,这不仅需要深入理解各种概念.原理和最佳实践,还 ...
- 论文复现丨基于ModelArts进行图像风格化绘画
摘要:这个 notebook 基于论文「Stylized Neural Painting, arXiv:2011.08114.」提供了最基本的「图片生成绘画」变换的可复现例子. 本文分享自华为云社区& ...
- 一文详解什么是可解释AI
摘要:本文带来什么是可解释AI,如何使用可解释AI能力来更好理解图片分类模型的预测结果,获取作为分类预测依据的关键特征区域,从而判断得到分类结果的合理性和正确性,加速模型调优. 1. 为什么需要可解释 ...
- 云小课|云小课带您快速了解LTS可视化查看
阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说).深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云.更多精彩内容请单击此处. 摘要: 可视化查看是日志 ...
- DNS--主从
操作系统:centos7.8 DNS-master:192.168.198.128 DNS-slave:192.168.198.129 一 主从同步过程 master修改完成重启后 将传送notify ...
- HDU - 2181 :哈密顿绕行世界问题
Descriptions: 一个规则的实心十二面体,它的 20个顶点标出世界著名的20个城市,你从一个城市出发经过每个城市刚好一次后回到出发的城市. Input 前20行的第i行有3个数,表示与第i个 ...