[转帖]使用 TiUP cluster 在单机上安装TiDB
https://zhuanlan.zhihu.com/p/369414808
TiUP 是 TiDB 4.0 版本引入的集群运维工具,TiUP cluster 是 TiUP 提供的使用 Golang 编写的集群管理组件,通过 TiUP cluster 组件就可以进行日常的运维工作,包括部署、启动、关闭、销毁、弹性扩缩容、升级 TiDB 集群,以及管理 TiDB 集群参数。
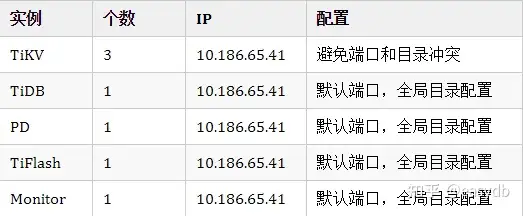
最小规模的 TiDB 集群拓扑:
1、添加数据盘 EXT4 文件系统
生产环境部署,建议使用 EXT4 类型文件系统的 NVME 类型的 SSD 磁盘存储 TiKV 数据文件。这个配置方案为最佳实施方案,其可靠性、安全性、稳定性已经在大量线上场景中得到证实。
使用 root 用户登录目标机器,将部署目标机器数据盘格式化成 ext4 文件系统,挂载时添加 nodelalloc 和 noatime 挂载参数。nodelalloc 是必选参数,否则 TiUP 安装时检测无法通过;noatime 是可选建议参数。
注意:
如果你的数据盘已经格式化成 ext4 并挂载了磁盘,可先执行 umount /dev/vdb 命令卸载,从编辑 /etc/fstab 文件步骤开始执行,添加挂载参数重新挂载即可。
1.1 查看数据盘
fdisk -l
Disk /dev/vdb: 107.4 GB, 107374182400 bytes, 209715200 sectors
1.2 创建分区
parted -s -a optimal /dev/vdb mklabel gpt -- mkpart primary ext4 1 -1
1.3 格式化文件系统
mkfs.ext4 /dev/vdb
1.4 使用 lsblk 命令查看分区的设备号及UUID:
[root@tidb01 ~]# lsblk -f
NAME FSTYPE LABEL UUID MOUNTPOINT
sr0 iso9660 CONTEXT 2021-04-30-09-59-46-00
vda
└─vda1 xfs de86ba8a-914b-4104-9fd8-f9de800452ea /
vdb ext4 957bb4c8-68f7-40df-ab37-1de7a4b5ee5e
1.5 编辑 /etc/fstab 文件,添加 nodelalloc 挂载参数
vi /etc/fstab
UUID=957bb4c8-68f7-40df-ab37-1de7a4b5ee5e /data ext4 defaults,nodelalloc,noatime 0 2
1.6 创建数据目录并挂载磁盘
mkdir -p /data && mount -a
1.7 检查文件系统是否挂载成功
执行以下命令,如果文件系统为 ext4,并且挂载参数中包含 nodelalloc,则表示已生效。
[root@tidb01 ~]# mount -t ext4
/dev/vdb on /data type ext4 (rw,noatime,nodelalloc,data=ordered)
2、安装步骤
2.1 下载并安装 TiUP:
curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh
2.2 安装 TiUP 的 cluster 组件:
tiup cluster
需要打开一个新的终端或重新加载source /root/.bash_profile文件才能执行tiup命令
2.3 如果机器已经安装 TiUP cluster,需要更新软件版本:
tiup update --self && tiup update cluster
2.4 调大 sshd 服务的连接数
由于模拟多机部署,需要通过 root 用户调大 sshd 服务的连接数限制:
- 修改 /etc/ssh/sshd_config 将 MaxSessions 调至 20。
- 重启 sshd 服务:
systemctl restart sshd.service
2.5 创建并启动集群
按下面的配置模板,编辑配置文件,命名为 topo.yaml,其中:
- user: "tidb":表示通过 tidb 系统用户(部署会自动创建)来做集群的内部管理,默认使用 22 端口通过 ssh 登录目标机器
- deploy_dir/data_dir: 分别为集群组件安装目录和数据目录
- replication.enable-placement-rules:设置这个 PD 参数来确保 TiFlash 正常运行
- host:设置为本部署主机的 IP
[root@tidb01 .tiup]# pwd
/root/.tiup
[root@tidb01 .tiup]# cat topo.yaml
# # Global variables are applied to all deployments and used as the default value of
# # the deployments if a specific deployment value is missing.
global:
user: "tidb"
ssh_port: 22
deploy_dir: "/data/tidb-deploy"
data_dir: "/data/tidb-data"
# # Monitored variables are applied to all the machines.
monitored:
node_exporter_port: 9100
blackbox_exporter_port: 9115
server_configs:
tidb:
log.slow-threshold: 300
tikv:
readpool.storage.use-unified-pool: false
readpool.coprocessor.use-unified-pool: true
pd:
replication.enable-placement-rules: true
replication.location-labels: ["host"]
tiflash:
logger.level: "info"
pd_servers:
- host: 10.186.65.41
tidb_servers:
- host: 10.186.65.41
tikv_servers:
- host: 10.186.65.41
port: 20160
status_port: 20180
config:
server.labels: { host: "logic-host-1" }
- host: 10.186.65.41
port: 20161
status_port: 20181
config:
server.labels: { host: "logic-host-2" }
- host: 10.186.65.41
port: 20162
status_port: 20182
config:
server.labels: { host: "logic-host-3" }
tiflash_servers:
- host: 10.186.65.41
monitoring_servers:
- host: 10.186.65.41
grafana_servers:
- host: 10.186.65.41
2.6 执行集群安装命令:
tiup cluster deploy <cluster-name> <tidb-version> ./topo.yaml --user root -p
- 参数 表示设置集群名称
- 参数 表示设置集群版本,可以通过 tiup list tidb 命令来查看当前支持部署的 TiDB 版本
示例
tiup cluster deploy barlow 4.0.12 ./topo.yaml --user root -p
按照引导,输入”y”及 root 密码,来完成部署:
Do you want to continue? [y/N]: y
Input SSH password:
成功安装会提示如下启动字样:
Cluster `barlow` deployed successfully, you can start it with command: `tiup cluster start barlow`
2.7 启动集群:
tiup cluster start barlow
tiup cluster start <cluster-name>
2.8 访问集群:
- 安装 MySQL 客户端。如果已安装 MySQL 客户端则可跳过这一步骤:
yum install -y mysql
- 访问TiDB数据库,密码为空:
mysql -uroot -p -h10.186.65.41 -P4000
- 访问 TiDB 的 Grafana 监控:
通过 http://{grafana-ip}:3000 访问集群 Grafana 监控页面,默认用户名和密码均为 admin。
http://10.186.65.41:3000/
- 访问 TiDB 的 Dashboard:
通过 http://{pd-ip}:2379/dashboard 访问集群 TiDB Dashboard 监控页面,默认用户名为 root,密码为空。
http://10.186.65.41:2379/dashboard
- 执行以下命令确认当前已经部署的集群列表:
tiup cluster list
[root@tidb01 .tiup]# tiup cluster list
Starting component `cluster`: /root/.tiup/components/cluster/v1.4.2/tiup-cluster list
Name User Version Path PrivateKey
---- ---- ------- ---- ----------
barlow tidb v4.0.12 /root/.tiup/storage/cluster/clusters/barlow /root/.tiup/storage/cluster/clusters/barlow/ssh/id_rsa
- 执行以下命令查看集群的拓扑结构和状态:
tiup cluster display <cluster-name>
[root@tidb01 .tiup]# tiup cluster display barlow
Starting component `cluster`: /root/.tiup/components/cluster/v1.4.2/tiup-cluster display barlow
Cluster type: tidb
Cluster name: barlow
Cluster version: v4.0.12
SSH type: builtin
Dashboard URL: http://10.186.65.41:2379/dashboard
ID Role Host Ports OS/Arch Status Data Dir Deploy Dir
-- ---- ---- ----- ------- ------ -------- ----------
10.186.65.41:3000 grafana 10.186.65.41 3000 linux/x86_64 Up - /data/tidb-deploy/grafana-3000
10.186.65.41:2379 pd 10.186.65.41 2379/2380 linux/x86_64 Up|L|UI /data/tidb-data/pd-2379 /data/tidb-deploy/pd-2379
10.186.65.41:9090 prometheus 10.186.65.41 9090 linux/x86_64 Up /data/tidb-data/prometheus-9090 /data/tidb-deploy/prometheus-9090
10.186.65.41:4000 tidb 10.186.65.41 4000/10080 linux/x86_64 Up - /data/tidb-deploy/tidb-4000
10.186.65.41:9000 tiflash 10.186.65.41 9000/8123/3930/20170/20292/8234 linux/x86_64 Up /data/tidb-data/tiflash-9000 /data/tidb-deploy/tiflash-9000
10.186.65.41:20160 tikv 10.186.65.41 20160/20180 linux/x86_64 Up /data/tidb-data/tikv-20160 /data/tidb-deploy/tikv-20160
10.186.65.41:20161 tikv 10.186.65.41 20161/20181 linux/x86_64 Up /data/tidb-data/tikv-20161 /data/tidb-deploy/tikv-20161
10.186.65.41:20162 tikv 10.186.65.41 20162/20182 linux/x86_64 Up /data/tidb-data/tikv-20162 /data/tidb-deploy/tikv-20162
Total nodes: 8
因为有悔,所以披星戴月;因为有梦,所以奋不顾身! 个人博客首发:easydb.net 微信公众号:easydb 关注我,不走丢!
[转帖]使用 TiUP cluster 在单机上安装TiDB的更多相关文章
- 在单机上安装多个oracle实例
1 在 hp unix上安装 oracle 10g ,这个不解释,直接安装好. 创建组oinstall,dba,用户oracle [root@node1 ~]# groupadd oinstal ...
- 单机CentOS 安装 TiDB
目录 一.官网教程 二.安装步骤 1.下载并安装 TiUP: 2.声明一下环境变量,否则会找不到 tiup 命令 3.安装 TiUP 的 cluster 组件: 4.官方教程说,由于模拟多机部署,需要 ...
- (转)单机上配置hadoop
哈哈,几天连续收到百度两次电话,均是利好消息,于是乎不知不觉的自己的工作效率也提高了,几天折腾了好久终于在单机上配置好了hadoop,然后也成功的运行了一个用例,耶耶耶耶耶耶. 转自:http://w ...
- 田渊栋:AlphaGo系统即使在单机上也有职业水平
Facebook人工智能组研究员田渊栋博士在知乎专栏上更新了一篇文章,详细分析了AlphaGo在<自然>杂志上发表的论文,他认为AlphaGo整个系统即使在单机上也已具有了职业水平,与李世 ...
- RedHat6.5上安装Hadoop单机
版本号:RedHat6.5 JDK1.8 Hadoop2.7.3 hadoop 说明:从版本2开始加入了Yarn这个资源管理器,Yarn并不需要单独安装.只要在机器上安装了JDK就可以直接安 ...
- ZooKeeper:win7上安装单机及伪分布式安装
zookeeper是一个为分布式应用所设计的分布式的.开源的调度服务,它主要用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用,协调及其管理的难度,提高性能的分布式服务. 本章的目的:如何 ...
- VNware上安装虚拟机Ubuntu16.10 并安装petalinux(版本问题的坑 弃帖 另开一帖)
1.下载Ubuntu镜像文件 最新版本:https://ubuntu.com/download/desktop 老版本:http://old-releases.ubuntu.com/releases/ ...
- 1.如何在虚拟机ubuntu上安装hadoop多节点分布式集群
要想深入的学习hadoop数据分析技术,首要的任务是必须要将hadoop集群环境搭建起来,可以将hadoop简化地想象成一个小软件,通过在各个物理节点上安装这个小软件,然后将其运行起来,就是一个had ...
- Docker上安装Redis
Docker可以很方便的进行服务部署和管理,下面我们通过docker来搭建Redis的单机模式.Redis主从复制.Redis哨兵模式.Redis-Cluster模式 一.在Docker上安装单机版R ...
- Tiup离线安装TIDB集群4.0.16版本
环境:centos7.6 中控机:8.213.8.25(内网) 可用服务器8.213.8.25-8.213.8.29 一.准备 TiUP 离线组件包 方法1:外网下载离线安装包拷贝进内网服务器 在Ti ...
随机推荐
- 通过 KernelUtil.dll 劫持 QQ / TIM 客户端 QQClientkey / QQKey 详细教程(附源码)
前言 由于 QQ 9.7.20 版本后已经不能通过模拟网页快捷登录来截取 QQClientkey / QQKey,估计是针对访问的程序做了限制,然而经过多方面测试,诸多的地区.环境.机器也针对这种获取 ...
- GetView介绍 以及 GetxController生命周期
etView 只是对已注册的 Controller 有一个名为 controller 的getter的 const Stateless 的 Widget,如果我们只有单个控制器作为依赖项,那我们就可以 ...
- C#数据结构与算法系列(十三):递归——迷宫问题
1.示例 2.代码实现 public class Maze { public static void Test() { int[][] map = new int[8][]; for (int i = ...
- 原理一、Java中的HashMap的实现
文章从JDK1.7和JDK1.8两个版本解析HashMap的实现原理及其中常见的面试题(两个版本HashMap最大的区别,1.7版HashMap=数组+链表,1.8版HashMap=数组+红黑树+链表 ...
- 云图说丨带你了解GaussDB(for Redis)双活解决方案
摘要:GaussDB(for Redis)推出了双活解决方案,基于GaussDB NoSQL统一架构,通过两个数据库实例之间的数据同步,达成数据的一致性. 本文分享自华为云社区<[云图说]一张图 ...
- 带你认识MindSpore量子机器学习库MindQuantum
摘要:MindSpore在3.28日正式开源了量子机器学习库MindQuantum,本文介绍MindQuantum的关键技术. 本文分享自华为云社区<MindSpore量子机器学习库MindQu ...
- CANN 5.0黑科技解密 | 算力虚拟化,让AI算力“物尽其用”
摘要:算力虚拟化技术对消费者而言,可有效降低算力的使用成本,对于设备商或运营商而言,则可极大提升算力资源的利用率,降低设备运营成本. 为什么要做算力虚拟化 近年来,人工智能领域呈井喷式发展,算力就是生 ...
- DarkMode(4):css滤镜 颜色反转实现深色模式
在<DarkMode(1):产品应用深色模式分析>提过,单纯反转是不行的.但是,把不需要反转的,在反转过来.或者用js,给想要反转的,加上反转样式,再对其他的做微调.这样个人觉得,开发成本 ...
- Codeforces Round #719 (Div. 3) A~E题解
51鸽了几天,有几场比赛的题解还没发布,今天晚上会补上的 1520A. Do Not Be Distracted! 问题分析 模拟,如果存在已经出现的连续字母段则输出NO using ll = lon ...
- Serverless 年终技术盘点 :工业、学术、社区遍地开花,国内厂商迅速卡位
作者 | 刘宇(花名:江昱) 2021 年,Serverless 架构在权威咨询机构 Forrester 所发布的 < The Forrester Wave: Function-As-A-S ...