【scikit-learn基础】--『分类模型评估』之评估报告
分类模型评估时,scikit-learn提供了混淆矩阵和分类报告是两个非常实用且常用的工具。
它们为我们提供了详细的信息,帮助我们了解模型的优缺点,从而进一步优化模型。
这两个工具之所以单独出来介绍,是因为它们的输出内容特别适合用在模型的评估报告中。
1. 混淆矩阵
混淆矩阵(Confusion Matrix)用于直观地展示模型预测结果与实际标签之间的对应关系。
它是一个表格,其行表示实际的类别标签,而列表示模型预测的类别标签。
通过混淆矩阵,可以清晰地看到模型的哪些预测是正确的,哪些是错误的,以及错误预测的具体分布情况。
1.1. 使用示例
下面用手写数字识别的示例,演示最后如何用混淆矩阵来可视化的评估模型训练结果的。
首先,读取手写数字数据集(这个数据集是scikit-learn中自带的):
import matplotlib.pyplot as plt
from sklearn import datasets
# 加载手写数据集
data = datasets.load_digits()
_, axes = plt.subplots(nrows=2, ncols=4, figsize=(10, 6))
for ax, image, label in zip(np.append(axes[0], axes[1]), data.images, data.target):
ax.set_axis_off()
ax.imshow(image, cmap=plt.cm.gray_r, interpolation="nearest")
ax.set_title("目标值: {}".format(label))

然后,用支持向量机来训练数据,得到一个分类模型(reg):
from sklearn.svm import SVC
n_samples = len(data.images)
X = data.images.reshape((n_samples, -1))
y = data.target
# 定义
reg = SVC()
# 训练模型
reg.fit(X, y)
最后,用得到的分类模型来预测数据,再用混淆矩阵来分析预测值和真实值。
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
# 用训练好的模型进行预测
y_pred = reg.predict(X)
cm = confusion_matrix(y, y_pred)
g = ConfusionMatrixDisplay(confusion_matrix=cm)
g.plot()
plt.show()
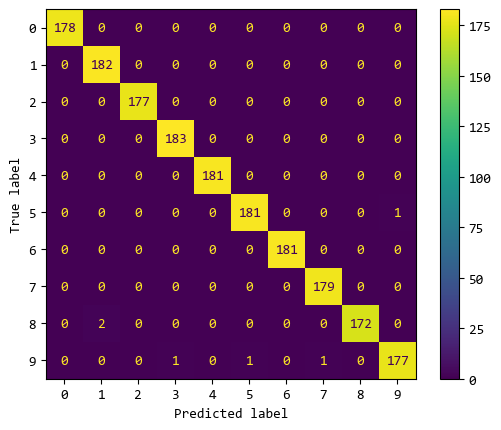
混淆矩阵中,横轴是预测值,纵轴是真实值。
对角线上预测值与真实值符合的情况,可以看出模型分类效果不错,大部分数据都能正确分类的。
也有极个别分类错误的情况,比如:
8被识别成1的错误有2个;5被识别成9的错误有1个;9被识别成3的错误有1个;- ... ... 等等
2. 分类报告
分类报告提供了模型在各个类别上的详细性能指标。
通常包括准确率(Precision)、召回率(Recall)、F1分数(F1-Score)等评估指标,这些指标能够帮助我们更全面地了解模型的性能。
2.1. 使用示例
基于上面训练的手写数字识别模型,看看模型的各项指标。
from sklearn.metrics import classification_report
# 这里的y 和 y_pred 是上一节示例中的值
report = classification_report(y, y_pred)
print(report)
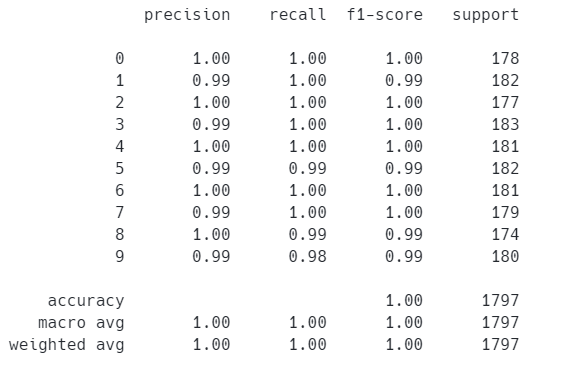
报告中列出了手写数字0~9的识别情况。
3. 总结
总的来说,分类报告与混淆矩阵一起使用,能够更全面地评估模型的性能,指导模型的优化和改进。
而且它们生成的评估表格和图形,也能够应用于我们的分析报告中。
【scikit-learn基础】--『分类模型评估』之评估报告的更多相关文章
- 分类模型评估之ROC-AUC曲线和PRC曲线
http://blog.csdn.net/pipisorry/article/details/51788927 在样本分布及其不均匀的情况下,建议用PRC...可以看下这个精确率.召回率.F1 值.R ...
- 笔记︱风控分类模型种类(决策、排序)比较与模型评估体系(ROC/gini/KS/lift)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 本笔记源于CDA-DSC课程,由常国珍老师主讲 ...
- 风控分类模型种类(决策、排序)比较与模型评估体系(ROC/gini/KS/lift)
python信用评分卡建模(附代码,博主录制) https://study.163.com/course/introduction.htm?courseId=1005214003&utm_ca ...
- Scikit-learn:模型评估Model evaluation
http://blog.csdn.net/pipisorry/article/details/52250760 模型评估Model evaluation: quantifying the qualit ...
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- 『高性能模型』轻量级网络ShuffleNet_v1及v2
项目实现:GitHub 参考博客:CNN模型之ShuffleNet v1论文:ShuffleNet: An Extremely Efficient Convolutional Neural Netwo ...
- 2017-2018-2 20155303『网络对抗技术』Exp9:Web安全基础
2017-2018-2 『网络对抗技术』Exp9:Web安全基础 --------CONTENTS-------- 一.基础问题回答 1.SQL注入攻击原理,如何防御? 2.XSS攻击的原理,如何防御 ...
- 『高性能模型』HetConv: HeterogeneousKernel-BasedConvolutionsforDeepCNNs
论文地址:HetConv 一.现有网络加速技术 1.卷积加速技术 作者对已有的新型卷积划分如下:标准卷积.Depthwise 卷积.Pointwise 卷积.群卷积(相关介绍见『高性能模型』深度可分离 ...
- 『高性能模型』轻量级网络MobileNet_v2
论文地址:MobileNetV2: Inverted Residuals and Linear Bottlenecks 前文链接:『高性能模型』深度可分离卷积和MobileNet_v1 一.Mobil ...
随机推荐
- Tomcat 9.0.26 高并发场景下DeadLock问题排查与修复
本文首发于 vivo互联网技术 微信公众号 链接:https://mp.weixin.qq.com/s/-OcCDI4L5GR8vVXSYhXJ7w作者:黄卫兵.陈锦霞 一.Tomcat容器 9.0. ...
- springboot启动类源码探索一波
举个例子: 这是一个原始的Spring IOC容器启动方法,我们需要AnnotationConfigApplicationContext这个类有如下几个步骤 1. 创建构造方法,根据我们所传入的Ap ...
- KVM 核心功能:磁盘虚拟化
1 磁盘虚拟化简介 QEMU-KVM 提供磁盘虚拟化,从虚拟机角度看其自身拥有的磁盘即是实际的物理磁盘.实际上,虚拟机读写的磁盘数据保存在 host 上的物理磁盘. QEMU-KVM 主要有如下几 ...
- OpenKruise :Kubernetes背后的托底
本文分享自华为云社区<OpenKruise核心能力和工作原理>,作者:可以交个朋友. 一. 诞生背景 Kubernetes 自身提供的应用部署管理功能,无法满足大规模应用场景的需求,例如应 ...
- [转帖]字符集 AL32UTF8 和 UTF8
https://blog.51cto.com/comtv/383254# 文章标签职场休闲字符集 AL32UTF8 和 UTF8文章分类数据库阅读数1992 The difference betwee ...
- [转帖]rsync原理
简介: Rsync(remote synchronize)是一个远程数据同步工具,可通过LAN/WAN快速同步多台主机间的文件.Rsync使用所谓的"Rsync算法"来使本地和远 ...
- Oracle session的sid与serial的简单学习
Oracle session的sid与serial的简单学习 ITPUB vage的说法 这样说吧,Oracle允许的会话数(或者说连接数)是固定的,比如是3000个.假设每个会话要占1K字节,哪一共 ...
- [转帖]云数据库是杀猪盘么,去掉中间商赚差价,aws数据库性能提升 10 倍!价格便宜十倍。
https://tidb.net/blog/021059f1 于是乎dba中的冯大嘴喊出了云数据库就是杀猪盘.让每个公司自建数据库. 那么有没有一种数据库又便宜又好用呢.有 哪就是tidb数据库. 之 ...
- [转帖]TiDB 数据库核心原理与架构 [TiDB v6](101)笔记
https://www.jianshu.com/p/01e49a93f671 description: "本课程专为将在工作中使用 TiDB 数据库的开发人员.DBA 和架构师设计. 本门课 ...
- [转帖]TiKV & TiFlash 加速复杂业务查询
https://tidb.net/book/tidb-monthly/2022/2022-07/usercase/tikv-tiflash 背景 在互联网公司或传统公司的 CRM 系统中,最常用的功 ...