87 GB 模型种子,GPT-4 缩小版,超越ChatGPT3.5,多平台在线体验
瞬间爆火的Mixtral 8x7B
大家好,我是老章
最近风头最盛的大模型当属Mistral AI 发布的Mixtral 8x7B了,火爆程度压过Google的Gemini。

缘起是MistralAI二话不说,直接在其推特账号上甩出了一个87GB的种子

随后Mixtral公布了模型的一些细节:
- 具有编程能力
- 相比 Llama 2 70B,运算速度快 6 倍
- 可处理 32k 令牌的上下文
- 可通过 API 接口使用
- 可自行部署(它使用 Apache 2.0 开源协议
- 在大多数标准基准测试中匹配或优于 GPT3.5
- 可以微调为遵循指令的模型,在 MT-Bench 测试中获得 8.3 分
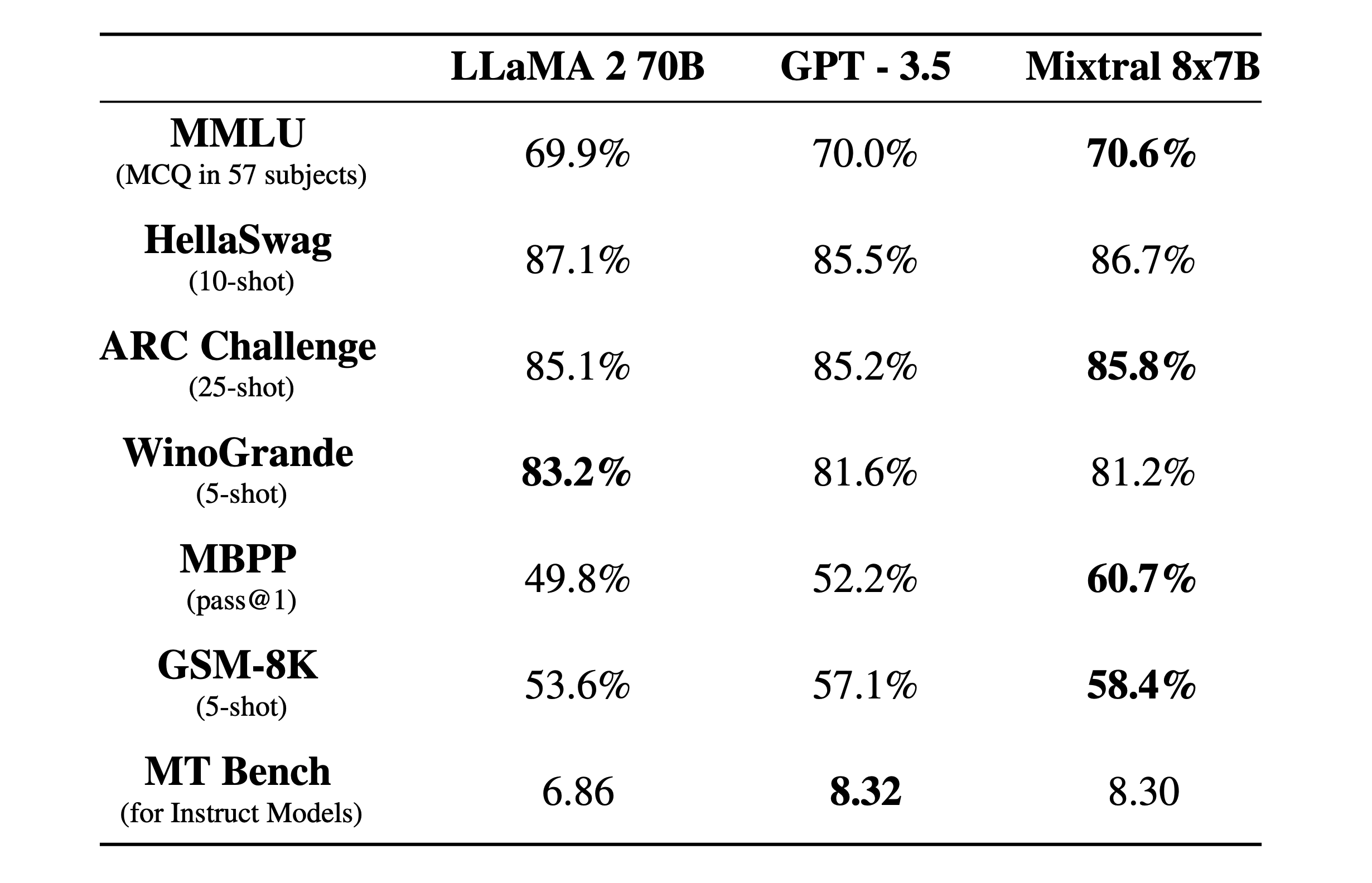
Mixtral 8x7B 技术细节
Mixtral 8x7B 是基于Mixture of Experts (专家混合,8x7B即 8 名专家,每个专家7B个参数 )的开源模型,
专家混合 (MoE) 是LLM中使用的一种技术,旨在提高其效率和准确性。这种方法的工作原理是将复杂的任务划分为更小、更易于管理的子任务,每个子任务都由专门的迷你模型或“专家”处理。
1、专家层:这些是较小的神经网络,经过训练,在特定领域具有高技能。每个专家处理相同的输入,但处理方式与其独特的专业相一致。
2、门控网络:这是MoE架构的决策者。它评估哪位专家最适合给定的输入数据。网络计算输入与每个专家之间的兼容性分数,然后使用这些分数来确定每个专家在任务中的参与程度。
Mixtral 是一个稀疏专家混合网络,仅包含解码器。其前馈网络从 8 组不同的参数中挑选,在每一层,对每个词元,路由网络会选择两组“专家”参数来处理该词元,并将其输出叠加。
这种技术在控制计算成本和延迟的同时扩大了模型规模,因为每个词元只使用参数总量的一小部分。具体来说,Mixtral 总参数量有 46.7 亿,但每个词元只使用 12.9 亿参数。因此,它的输入处理和输出生成速度与成本与 12.9 亿参数模型相当。
Mistral 8x7B 使用与 GPT-4 非常相似的架构,但缩小了:
- 总共 8 名专家,而不是 16 名(减少 2 倍)
- 每个专家 7B 个参数,而不是 166B(减少 24 倍)
- 42B 总参数(估计)而不是 1.8T(减少 42 倍)
- 与原始 GPT-4 相同的 32K 上下文
线上体验 Mixtral 8x7B
如果大家硬件资源真的很硬,可以下载这个87GB的模型种子本地运行

下载:https://twitter.com/MistralAI/status/1733150512395038967
玩法:https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2
我相信99%的同学应该没有这个实力,现在市面上已经有很多可以在线试玩的平台了。
1、replicate
https://replicate.com/nateraw/mixtral-8x7b-32kseqlen

replicate还服了api调用的方法:
pip install replicate
export REPLICATE_API_TOKEN=<paste-your-token-here>
#API token https://replicate.com/account/api-tokens
import replicate
output = replicate.run(
"nateraw/mixtral-8x7b-32kseqlen:f8125aef9cd96d879f4e5c5c1ff78618818e62939ab76ab1e07425ac75d453bc",
input={"prompt": "你好",
"top_p": 0.9,
"temperature": 0.6,
"max_new_tokens": 512
}
)
print(output)
2、POE
https://poe.com/chat/2t377k6re3os2ha7z1e

3、fireworks.ai
https://app.fireworks.ai/models/fireworks/mixtral-8x7b-fw-chat

4、perplexity_ai


87 GB 模型种子,GPT-4 缩小版,超越ChatGPT3.5,多平台在线体验的更多相关文章
- 流量录制与回放在vivo的落地实践
一.为什么要使用流量录制与回放? 1.1 vivo业务状况 近几年,vivo互联网领域处于高速发展状态,同时由于vivo手机出货量一直在国内名列前茅,经过多年积累,用户规模非常庞大.因此,vivo手机 ...
- Generative Pre-trained Transformer(GPT)模型技术初探
一.Transformer模型 2017年,Google在论文 Attention is All you need 中提出了 Transformer 模型,其使用 Self-Attention 结构取 ...
- 第五周-磁盘分区GPT、shell脚本练习、lvm详解
1. 描述GPT是什么,应该怎么使用 Linux中磁盘分区分为MBR和GPT. MBR全称为Master Boot Record,为主引导记录,是传统的分区机制,应用于绝大多数使用的BIOS的PC设备 ...
- 『高性能模型』Roofline Model与深度学习模型的性能分析
转载自知乎:Roofline Model与深度学习模型的性能分析 在真实世界中,任何模型(例如 VGG / MobileNet 等)都必须依赖于具体的计算平台(例如CPU / GPU / ASIC 等 ...
- 预训练语言模型整理(ELMo/GPT/BERT...)
目录 简介 预训练任务简介 自回归语言模型 自编码语言模型 预训练模型的简介与对比 ELMo 细节 ELMo的下游使用 GPT/GPT2 GPT 细节 微调 GPT2 优缺点 BERT BERT的预训 ...
- 腾讯 angel 3.0:高效处理模型
腾讯 angel 3.0:高效处理模型 紧跟华为宣布新的 AI 框架开源的消息,腾讯又带来了全新的全栈机器学习平台 angel3.0.新版本功能特性覆盖了机器学习的各个阶段,包括:特征工程.模型训练. ...
- Windows Phone 执行模型概述
Windows Phone 执行模型控制在 Windows Phone 上运行的应用程序的生命周期,该过程从启动应用程序开始,直至应用程序终止. 该执行模型旨在始终为最终用户提供快速响应的体验.为此, ...
- 图解I/O的五种模型
1.1 五种I/O模型 1)阻塞I/O 2)非阻塞I/O 3)I/O复用 4)事件(信号)驱动I/O 5)异步I/O 1.2 为什么要发起系统调用? 因为进程想要获取磁盘中的数据,而能和磁盘打交道的只 ...
- Jena 简介:通过 Jena Semantic Web Framework 在 Jave 应用程序中使用 RDF 模型
简介: RDF 越来越被认为是表示和处理半结构化数据的一种极好选择.本文中,Web 开发人员 Philip McCarthy 向您展示了如何使用 Jena Semantic Web Toolkit,以 ...
- 【java多线程系列】java内存模型与指令重排序
在多线程编程中,需要处理两个最核心的问题,线程之间如何通信及线程之间如何同步,线程之间通信指的是线程之间通过何种机制交换信息,同步指的是如何控制不同线程之间操作发生的相对顺序.很多读者可能会说这还不简 ...
随机推荐
- PanGu-Coder2:从排序中学习,激发大模型潜力
本文分享自华为云社区<PanGu-Coder2:从排序中学习,激发大模型潜力>,作者: 华为云软件分析Lab . 2022年7月,华为云PaaS技术创新Lab联合华为诺亚方舟语音语义实验室 ...
- SQL Server用户的设置与授权
SQL Server用户的设置与授权 SSMS 登陆方式有两种,一是直接使用Windows身份验证,二是SQL Server身份验证.使用SQL Server用户设置与授权不仅可以将不同的数据库开放给 ...
- assembleDebug太慢的问题调查以及其他
Preface 最近在做flutter上的音频和视频方面的探索. 需要用到一些视屏区域截取,视屏导出成序列图等等. 这是昨天晚上到今天早上解决的一些问题的汇总,可能先后顺序之类的会记错: 此文目的用于 ...
- Solution -「洛谷 P4688」「YunoOI 2016」掉进兔子洞
Description (Link)[https://www.luogu.com.cn/problem/P4688]. 每次询问三个区间,把三个区间中同时出现的数一个一个删掉,问最后三个区间剩下的数的 ...
- 聊聊基于Alink库的主成分分析(PCA)
概述 主成分分析(Principal Component Analysis,PCA)是一种常用的数据降维和特征提取技术,用于将高维数据转换为低维的特征空间.其目标是通过线性变换将原始特征转化为一组新的 ...
- 2023_10_09_MYSQL_DAY_01_笔记
2023_10_09_MYSQL_DAY_01 #运算符的优先级 SELECT ename, job, sal FROM emp WHERE ( job='SALESMAN' OR job='PRES ...
- Centos7下创建centos-home逻辑分区
1备份要挂载的文件夹 查看home文件夹有无文件,如有文件一定要记得备份 2创建逻辑分区 2.1查看已有逻辑分区 2.2查看磁盘分区情况 2.3查看磁盘PV 2.4创建逻辑分区 lvcreate -n ...
- .NET开源简单易用、内置集成化的控制台、支持持久性存储的任务调度框架 - Hangfire
前言 定时任务调度应该是平时业务开发中比较常见的需求,比如说微信文章定时发布.定时更新某一个业务状态.定时删除一些冗余数据等等.今天给推荐一个.NET开源简单易用.内置集成化的控制台.支持持久性存储的 ...
- 小景的Dba之路--Oracle用exp导出dmp文件很慢
小景最近在系统压测相关的工作,其中涉及了Oracle数据库相关的知识,之前考的OCP证书也在此地起了作用.今天的问题是:Oracle用exp导出dmp文件很慢,究竟是什么原因,具体的解决方案都有哪些呢 ...
- 轻巧的批量图片压缩工具imgfast
现在的手机拍照动辄2M3M,还有7M8m的,如果要把这些文件上传到网上应用,浪费网络,占用资源 所以2022年中秋写了这个小工具,可以批量进行图片文件压缩,支持jpg和png. 文件下载链接https ...