文档理解的新时代:LayOutLM模型的全方位解读
一、引言
在现代文档处理和信息提取领域,机器学习模型的作用日益凸显。特别是在自然语言处理(NLP)技术快速发展的背景下,如何让机器更加精准地理解和处理复杂文档成为了一个挑战。文档不仅包含文本信息,还包括布局、图像等非文本元素,这些元素在传递信息时起着至关重要的作用。传统的NLP模型通常忽略了这些视觉元素,但LayOutLM模型的出现改变了这一局面。
LayOutLM模型是一种创新的深度学习模型,它结合了传统的文本处理能力和对文档布局的理解,从而在处理包含丰富布局信息的文档时表现出色。这种模型的设计思想源于对现实世界文档处理需求的深刻理解。例如,在处理一份报告时,我们不仅关注报告中的文字内容,还会关注图表、标题、段落布局等视觉信息。这些信息帮助我们更好地理解文档的结构和内容重点。
为了说明LayOutLM模型的重要性和实用性,我们可以考虑一份含有多种元素(如文本、表格、图片)的商业合同。在这样的文档中,合同的条款可能以不同的字体或布局突出显示,而关键的图表和数据则以特定的方式呈现。传统的文本分析模型可能无法有效地识别和处理这些复杂的布局和视觉信息,导致信息提取不完整或不准确。而LayOutLM模型则能够识别这些元素,准确提取关键信息,从而大大提高文档处理的效率和准确性。
在接下来的章节中,我们将详细探讨LayOutLM模型的架构、技术实现细节以及在实际场景中的应用。通过深入了解LayOutLM模型,读者将能够更好地理解其在现代文档理解领域的独特价值和广泛应用前景。
二、LayOutLM模型详解
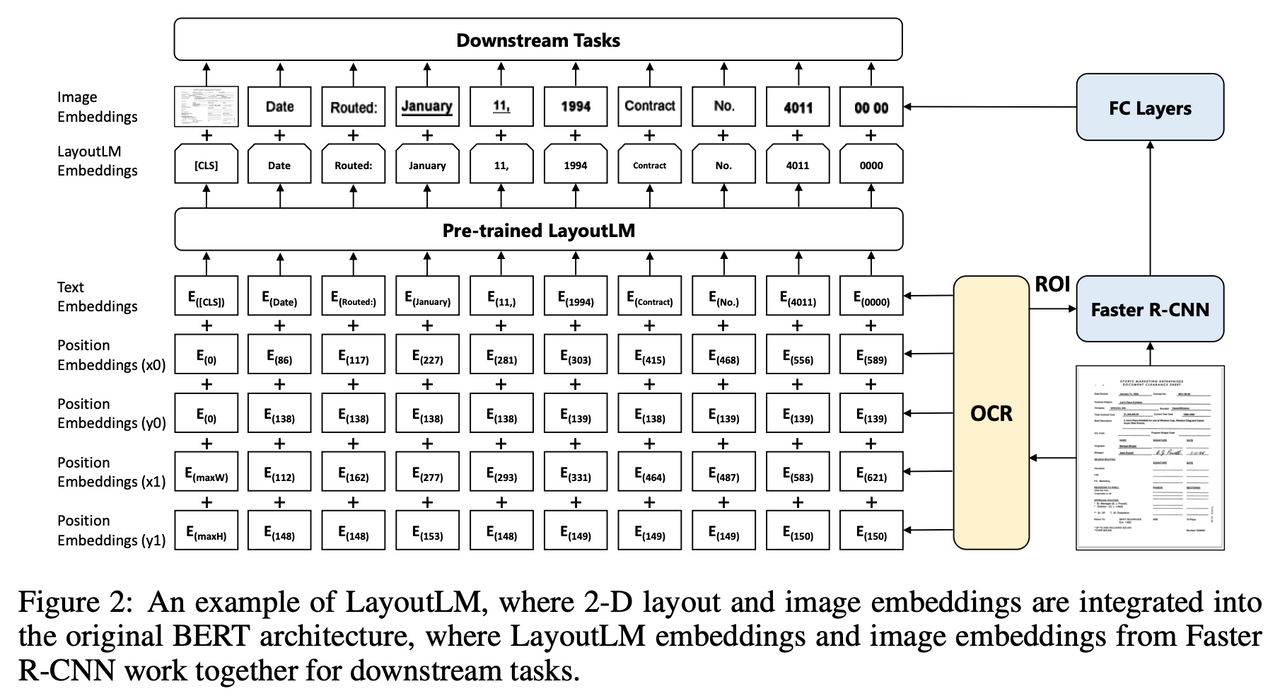
LayOutLM模型代表了自然语言处理(NLP)与计算机视觉(CV)交叉领域的一大步。它不仅理解文本内容,还融入了文档的布局信息,为文档理解带来了革新性的进步。接下来,我们将深入探讨LayOutLM模型的关键组成部分、工作原理和实际应用。
模型架构概览
LayOutLM采用了与BERT类似的架构,但它在输入表示中加入了视觉特征。这些视觉特征来自文档中的每个词的布局信息,如位置坐标和页面信息。LayOutLM利用这些信息来理解文本在视觉页面上的分布,这在处理表格、表单和其他布局密集型文档时特别有用。
输入表示方法
在LayOutLM中,每个词的输入表示由以下几部分组成:
- 文本嵌入: 类似于传统的NLP模型,使用词嵌入来表示文本信息。
- 位置嵌入: 表示词在文本序列中的位置。
- 布局嵌入: 新增加的特征,包括词在页面上的相对位置(例如左上角坐标和右下角坐标)。
例如,考虑一个简单的发票文档,包含“发票号码”和具体的数字。LayOutLM不仅理解这些词的语义,还能通过布局嵌入识别数字是紧跟在“发票号码”标签后面的,从而有效地提取信息。
预训练任务和过程
LayOutLM的预训练包括多种任务,旨在同时提高模型的语言理解和布局理解能力。这些任务包括:
- 掩码语言模型(MLM): 类似于BERT,部分词被掩盖,模型需要预测它们。
- 布局预测: 模型不仅预测掩盖的词,还预测它们的布局信息。
微调和应用
在预训练完成后,LayOutLM可以针对特定任务进行微调。例如,在表单理解任务中,可以用具有标注的表单数据对模型进行微调,使其更好地理解和提取表单中的信息。
# 示例代码: LayOutLM模型微调
from transformers import LayoutLMForTokenClassification
# 加载预训练的LayOutLM模型
model = LayoutLMForTokenClassification.from_pretrained('microsoft/layoutlm-base-uncased')
# 微调模型(伪代码)
train_dataloader = ... # 定义训练数据
optimizer = ... # 定义优化器
for epoch in range(num_epochs):
for batch in train_dataloader:
inputs = batch['input_ids']
labels = batch['labels']
outputs = model(inputs, labels=labels)
loss = outputs.loss
loss.backward()
optimizer.step()
在这一部分,我们通过深入分析LayOutLM模型的架构和工作机制,展示了其在理解包含丰富布局信息的文档方面的强大能力。通过举例和代码展示,我们希望读者能够更全面地理解LayOutLM模型的工作原理和应用场景。在接下来的章节中,我们将进一步探讨LayOutLM在实际应用中的表现和实战指南。
三、LayOutLM在实际中的应用
LayOutLM模型不仅在理论上具有创新性,更在实际应用中显示出其强大的能力。本节将探讨LayOutLM在多个实际场景中的应用,通过具体的例证来阐明其在解决实际问题中的有效性和灵活性。
文档分类与排序
在企业和机构的日常工作中,大量的文档需要被分类和归档。传统方法依赖于文本内容的关键词搜索,但LayOutLM可以进一步利用文档的布局信息。例如,不同类型的报告、发票或合同通常具有独特的布局特征。LayOutLM能够识别这些特征,从而更准确地将文档分类。
信息提取
信息提取是LayOutLM的另一个重要应用场景。在处理发票、收据等文档时,关键信息(如总金额、日期、项目列表)通常分布在不同的位置,且每个文档的布局可能略有不同。LayOutLM利用其对布局的理解,能够准确地从这些文档中提取所需信息。例如,从一堆杂乱的发票中提取出所有的发票号码和金额,即便它们的布局不尽相同。
表单处理
在表单处理中,LayOutLM的应用尤为突出。不同于传统的基于规则的处理方法,LayOutLM可以理解表单中的问题和答案的布局关系。这使得在自动化处理问卷调查或申请表时,模型可以更加高效和准确地提取出关键信息。
自动化文档审核
在法律和金融领域,文档审核是一项关键任务。LayOutLM可以辅助审核人员快速地找出文档中的关键条款或可能存在的问题。例如,在一份合同中,模型可以快速定位到关键的责任条款或特殊的免责声明,辅助法律专业人士进行深入分析。
通过上述应用案例,可以看出LayOutLM模型在实际中的广泛应用和显著效果。这些例证不仅展示了LayOutLM在处理具有复杂布局的文档方面的能力,也说明了其在提高工作效率和准确性方面的巨大潜力。接下来的章节将进一步提供实战指南,帮助读者了解如何在自己的项目中实施和优化LayOutLM模型。
四、实战指南
在本节中,我们将提供一个基于Python和PyTorch的实战指南,展示如何使用LayOutLM模型进行文档理解任务。我们将通过一个实际场景——从一组商业发票中提取关键信息——来演示LayOutLM的实现和应用。
场景描述
假设我们有一批不同格式的商业发票,需要从中提取关键信息,如发票号、日期、总金额等。这些发票在布局上有所差异,但都包含了上述关键信息。
输入和输出
- 输入: 一批包含文本和布局信息的发票图像。
- 输出: 提取的关键信息,如发票号、日期和总金额。
处理过程
环境准备: 安装必要的库。
pip install transformers torch torchvision
模型加载: 加载预训练的LayOutLM模型。
from transformers import LayoutLMForTokenClassification, LayoutLMTokenizer model_name = 'microsoft/layoutlm-base-uncased'
model = LayoutLMForTokenClassification.from_pretrained(model_name)
tokenizer = LayoutLMTokenizer.from_pretrained(model_name)
数据准备: 对发票图像进行预处理,提取文本和布局信息。
# 这里是一个示例函数,用于将发票图像转换为模型输入
def preprocess_invoice(image_path):
# 实现图像的加载和预处理,提取文本和布局信息
# 返回模型所需的输入格式,如tokenized text, attention masks, 和token type ids
pass # 示例:处理单个发票图像
input_data = preprocess_invoice("path_to_invoice_image.jpg")
信息提取: 使用LayOutLM模型提取关键信息。
import torch # 调整输入数据以适应模型
input_ids = torch.tensor([input_data["input_ids"]])
token_type_ids = torch.tensor([input_data["token_type_ids"]])
attention_mask = torch.tensor([input_data["attention_mask"]]) with torch.no_grad():
outputs = model(input_ids, token_type_ids=token_type_ids, attention_mask=attention_mask)
predictions = outputs.logits.argmax(dim=2)
结果解析: 解析模型输出,提取和整理关键信息。
# 示例函数,用于解析模型的输出并提取信息
def extract_info(predictions, tokens):
# 实现提取关键信息的逻辑
# 返回结构化的信息,如发票号、日期和金额
pass tokens = input_data["tokens"]
extracted_info = extract_info(predictions, tokens)
后处理: 根据需要对提取的信息进行格式化和存储。
在以上步骤中,我们描述了使用LayOutLM模型从商业发票中提取关键信息的完整过程。请注意,数据预处理和结果解析步骤将依赖于具体的应用场景和数据格式。通过这个实战指南,读者应该能够理解如何在实际项目中部署和使用LayOutLM模型,从而解决复杂的文档理解任务。
五、结论
随着人工智能领域的迅速发展,模型如LayOutLM的出现不仅是技术进步的象征,更代表了我们对于信息处理方式的深刻理解和创新。LayOutLM模型在NLP和CV的交汇点上打开了新的可能性,为处理和理解复杂文档提供了新的视角和工具。这一点在处理具有丰富布局信息的文档时尤为明显,它不仅提升了信息提取的准确性,还极大地增强了处理效率。
域的独特洞见
跨领域融合的趋势: LayOutLM的成功展示了跨领域(如NLP和CV)融合的巨大潜力。这种跨学科的方法为解决复杂问题提供了新的思路,预示着未来人工智能发展的一个重要趋势。
对复杂数据的深层次理解: 传统的NLP模型在处理仅包含文本的数据时表现出色,但在面对包含多种数据类型(如文本、图像、布局)的复杂文档时则显得力不从心。LayOutLM的出现弥补了这一空缺,它的能力在于不仅理解文本内容,还能解读文档的视觉布局,展示了对更复杂数据的深层次理解。
实用性与应用广泛性: LayOutLM不仅在理论上具有创新性,而且在实际应用中表现出色。从商业发票的信息提取到法律文档的自动审核,这些应用案例证明了其在多个行业的广泛适用性和实用价值。
持续的创新与优化: 正如LayOutLM在现有技术上的进步,未来的研究可能会继续在模型的精度、速度和灵活性上进行优化。这可能包括更高效的训练方法、对更多种类的文档格式的支持,以及更加智能的上下文理解能力。
综上所述,LayOutLM模型不仅在技术上取得了显著的进展,更重要的是它为我们提供了一种全新的视角来看待和处理文档信息。随着人工智能技术的不断发展,我们可以预见到更多类似LayOutLM这样的模型将出现,并在各个领域发挥重要作用。在此过程中,对技术的深入理解和创新思维将是推动这一领域发展的关键。
如有帮助,请多关注
TeahLead KrisChang,10+年的互联网和人工智能从业经验,10年+技术和业务团队管理经验,同济软件工程本科,复旦工程管理硕士,阿里云认证云服务资深架构师,上亿营收AI产品业务负责人。
文档理解的新时代:LayOutLM模型的全方位解读的更多相关文章
- C#如何向word文档插入一个新段落及隐藏段落
编辑Word文档时,我们有时会突然想增加一段新内容:而将word文档给他人浏览时,有些信息我们是不想让他人看到的.那么如何运用C#编程的方式巧妙地插入或隐藏段落呢?本文将与大家分享一种向Word文档插 ...
- 23----2013.07.01---Div和Span区别,Css常用属性,选择器,使用css的方式,脱离文档流,div+css布局,盒子模型,框架,js基本介绍
01 复习内容 复习之前的知识点 02演示VS创建元素 03div和span区别 通过display属性进行DIV与Span之间的转换.div->span 设置display:inline ...
- SharePoint 2016 文档库的新功能简介
今天,重装了一下SharePoint 2016,想多了解了解,看到一些自己平时没注意的功能,或者新的功能,分享一下给大家. 1.界面上操作的变换,多了一排按钮,更像SharePoint Online了 ...
- Java 在 Word 文档中使用新文本替换指定文本
创作一份文案,经常会高频率地使用某些词汇,如地名.人名.人物职位等,若表述有误,就需要整体撤换.文本将介绍如何使用Spire.Doc for Java,在Java程序中对Word文档中的指定文本进行替 ...
- NPOI word文档表格在新的文档中多次使用
最近有一个项目,涉及到文档操作,有一个固定的模版,模版中有文字和表格,表格会在新的文档中使用n多次 //获取模版中的表格FileStream stream = new FileStream(strPa ...
- GIt帮助文档之创建新的Git仓库——现有目录下,通过导入所有文件来创建
1.新建仓库初始化操作 1.1打开Git Bash命令窗口,切换到项目文件夹目录: $ cd weixin 1.2执行命令: $ git init 初始化操作,把项目weixin纳入Git管理.初始化 ...
- PowerDesigner(九)-模型文档编辑器(生成项目文档)(转)
模型文档编辑器 PowerDesigner的模型文档(Model Report)是基于模型的,面向项目的概览文档,提供了灵活,丰富的模型文档编辑界面,实现了设计,修改和输出模型文档的全过程. 模型文 ...
- PowerDesigner 模型文档 说明
PowerDesigner 模型文档 说明 目录(?)[+] 一. 模型文档说明 在前面几篇里介绍了PowerDesigner 的几种模型,如果我们项目里用到的模型较多,亦或者项目牵涉的部门很 ...
- 从零开始编写自己的C#框架(4)——文档编写说明
在写本系列的过程中,了解得越多越不知道从哪里做为切入点来写,几乎每个知识点展开来说都可以写成一本书.而自己在写作与文档编写方面来说,还是一个初鸟级别,所以只能从大方面说说,在本框架开发所需的范围内来讲 ...
- 百度大脑UNIT3.0解读之对话式文档问答——上传文档获取对话能力
在日常生活中,用户会经常碰到很多复杂的规章制度.规则条款.比如:乘坐飞机时,能不能带宠物上飞机,3岁小朋友是否需要买票等.在工作中,也会面对公司多样的规定制度和报销政策.比如:商业保险理赔需要什么材料 ...
随机推荐
- Ubuntu Linux 更换国内源
Ubuntu的官方源对于国内用户来说是比较慢的,可以将它的源换成国内的源,用起来就快很多了. # Ubuntu server 环境 ubuntu@ubuntu:~$ sudo su - [ sudo ...
- 关闭Google"阻止了登录尝试"方法, 其他设备也能登录Gmail等谷歌服务
首先登录谷歌账户, 访问 https://www.google.com/settings/security/lesssecureapps 把"不够安全的应用的访问权限" 启用打勾 ...
- BZ全景编辑器(KRPano全景可视化编辑器, 无需编写代码, 图形化制作全景漫游)
软件简介 BZ全景编辑器是一款KRPano全景可视化编辑工具,下载安装即可使用,无需拥有任何KRPano代码基础,便可以制作生成精美的全景漫游作品. BZ全景编辑器群:882083973 最新版软件下 ...
- MySQL高级12-事务原理
一.事务概念 事务是一组操作的集合,他是一个不可分割的工作单位,事务会把所有操作作为一个整体一起向系统提交或者撤销请求操作,即这些操作要么同时成功,要么同时失败. 二.事务特性 原子性(Atomici ...
- Towards Network Anomaly Detection Using Graph Embedding笔记
Towards Network Anomaly Detection Using Graph Embedding 目录 Towards Network Anomaly Detection Using G ...
- Dubbo3应用开发—Dubbo3注册中心(zookeeper、nacos、consul)的使用
Dubbo3注册中心的使用 zookeeper注册中心的使用 依赖引入 <dependency> <groupId>org.apache.dubbo</groupId&g ...
- 编译python为可执行文件遇到的问题:使用python-oracledb连接oracle数据库时出现错误:DPY-3010
错误原文: DPY-3010: connections to this database server version are not supported by python-oracledb in ...
- 时髦称呼:SQL递归"语法糖"的用法
Oracle函数sys_connect_by_path 详解 语法:Oracle函数:sys_connect_by_path 主要用于树查询(层次查询) 以及 多列转行.其语法一般为: s ...
- 研发三维GIS系统笔记/框架改造/智能指针重构框架-003
1. 使用智能指针重构系统 原有的系统都是裸指针,在跨模块与多线程中使用裸指针管理起来很麻烦,尤其是多任务系统中会出现野指针 1 class CELLTileTask :public CELLTask ...
- 聊聊基于Alink库的特征工程方法
示例代码及相关内容来源于<Alink权威指南(Java版)> 独热编码 OneHotEncoder 是用于将类别型特征转换为独热编码的类.独热编码是一种常用的特征编码方式,特别适用于处理类 ...