5分钟教你从爬虫到数据处理到图形化一个界面实现山西理科分数查学校-Python
5分钟教你从爬虫到数据处理到图形化一个界面实现山西理科分数查学校-Python
引言
在高考结束后,学生们面临的一大挑战是如何根据自己的分数找到合适的大学。这是一个挑战性的任务,因为它涉及大量的数据和复杂的决策过程。大量的信息需要被过滤和解析,以便学生们能对可能的大学选择有一个清晰的认识。这个过程可以通过计算机程序来大大简化,给学生带来便利。本实验报告将详细描述如何使用Python,一种强大而灵活的编程语言,来实现一个服务,该服务可以根据学生的分数,从网站上爬取数据,然后分析这些数据,最后提供一个用户友好的界面,使学生能够方便地查询分数对应的可能学校。
Python是一种强大的编程语言,因其丰富的第三方库和易用性,被广大数据科学家和程序员所喜欢。Python丰富的第三方库,如requests、BeautifulSoup、pandas和Tkinter,使得我们能顺利完成从数据获取到用户界面设计的整个过程。本报告将以“山西省2023年普通高校招生第一批本科A类院校投档最低分”网站为例,详细介绍整个实现过程。
数据获取
- 注:山西招生考试网使用js禁用了网页端的复制以及右键菜单,无法直接复制表格,所以我们先保存html源码再做分析。
在本项目中,我们的数据来自山西省的招生网站。首先,我们需要通过Python的requests库向目标网站发送GET请求,获得网页的HTML内容。requests库是Python中最常用的HTTP请求库,它的API设计的简单易用,可以轻松完成各种复杂的HTTP请求。
在发送GET请求时,我们需要提供目标网站的URL。在收到请求后,服务器将返回包含网页内容的HTML文本。这个过程可能会遇到网络延迟、服务器错误等问题,我们需要使用try/except语句来处理这些可能的错误,确保程序的稳定运行。
数据解析
获取到网页数据后,下一步是解析这些数据,提取出我们需要的信息。解析HTML并不是一件容易的事,因为HTML的结构通常很复杂,有许多嵌套的标签。幸运的是,我们有BeautifulSoup库,它可以帮助我们轻松地解析HTML。
在本项目中,我们需要提取表格中的数据。表格数据通常包含在<tr>和<td>标签中。我们首先使用BeautifulSoup的find_all方法找到所有的<tr>元素,然后对每个<tr>元素,我们提取其所有<td>子元素的文本。这些文本是我们需要的数据,我们将它们组合成一个列表,然后将这个列表添加到一个大的列表中,这个大列表将包含所有的数据。
数据处理
得到原始数据后,我们需要进行一些处理,以便后续的分析。数据处理是数据科学的一个重要部分,它包括清洗数据、整理数据和过滤数据等。
在本项目中,我们使用pandas库来处理数据。pandas是Python中最常用的数据处理库,它提供了许多强大的功能,如数据过滤、排序和聚合等。我们首先使用pandas的read_csv函数读取CSV文件,然后使用布尔索引方法过滤出我们需要的数据。具体来说,我们需要找出所有最低分低于输入分数的学校。这可以通过创建一个布尔索引实现,该索引对应于最低分低于输入分数的行。我们还需要对数据进行排序,以便用户能够更容易地查看数据。
GUI编程
有了处理好的数据,我们接下来需要创建一个图形用户界面(GUI),让用户能够方便地输入分数并查看对应的学校。Python的Tkinter库提供了一种简单而强大的方式来创建GUI。
我们首先创建一个窗口,然后在窗口中添加一些控件,如文本框、按钮和列表框。用户可以在文本框中输入分数,然后点击按钮进行查询。查询结果将显示在列表框中。
为了使GUI更加友好,我们还需要处理一些细节,如输入验证、错误提示和结果显示格式等。这些细节虽小,但却对用户体验有着重要的影响。
打包应用
最后,我们使用PyInstaller库将Python脚本打包成一个独立的可执行文件。这样,用户就可以在没有Python环境的电脑上运行这个程序。PyInstaller是一个强大的打包工具,它可以将Python脚本及其依赖的库打包成一个单一的可执行文件,使得分发和使用变得非常方便。
结论
这个过程涵盖了数据获取、解析、处理和GUI编程等多个步骤,展示了Python在处理实际问题中的强大能力。
通过这个实验,我们可以看到Python在数据获取、处理和GUI编程方面的强大能力。Python的丰富的第三方库使得这些任务变得简单而直接。这个实验也展示了Python在实际问题中的应用,如何从网页获取数据,然后处理这些数据,并创建一个用户友好的接口供用户查询数据。
总的来说,Python是一种强大的工具,不仅可以用于科学计算和数据分析,也可以用于创建实用的应用程序。本实验只是展示了Python的一小部分能力,Python的真正潜力远不止于此。
附:pyqt源码:
import sys
import pandas as pd
from PyQt5.QtGui import QIcon
from PyQt5.QtWidgets import QApplication, QWidget, QLabel, QLineEdit, QPushButton, QVBoxLayout, QScrollArea
class MainWindow(QWidget):
def __init__(self):
super().__init__()
# 设置窗口图标
self.setWindowIcon(QIcon('favicon.ico'))
# 创建界面元素
self.score_label = QLabel('请输入分数:')
self.score_input = QLineEdit()
self.result_label = QLabel('查询结果:')
self.result_output = QLabel()
self.search_button = QPushButton('查询')
# 创建滚动区域
self.scroll_area = QScrollArea()
self.scroll_area.setWidgetResizable(True)
self.scroll_area_content = QWidget(self.scroll_area)
self.scroll_area_layout = QVBoxLayout(self.scroll_area_content)
self.scroll_area.setWidget(self.scroll_area_content)
# 设置界面布局
layout = QVBoxLayout()
layout.addWidget(self.score_label)
layout.addWidget(self.score_input)
layout.addWidget(self.search_button)
layout.addWidget(self.result_label)
layout.addWidget(self.scroll_area)
self.setLayout(layout)
# 绑定按钮点击事件
self.search_button.clicked.connect(self.search)
# 设置窗口大小
self.setFixedSize(300, 700)
def search(self):
# 读取CSV文件
df = pd.read_csv('理工.csv')
# 过滤数据
score = float(self.score_input.text())
filtered_df = df[df['最低分'] < score]
# 显示结果
# result = '\n'.join(filtered_df['院校名称'].tolist())
result = '\n'.join(filtered_df.apply(lambda row: '{}: {}'.format(row['院校名称'], row['最低分']), axis=1).tolist())
self.result_output.setText(result)
self.scroll_area_content.setMinimumWidth(self.result_output.width())
self.scroll_area_layout.addWidget(self.result_output)
if __name__ == '__main__':
# 创建应用程序和主窗口
app = QApplication(sys.argv)
window = MainWindow()
# 显示主窗口
window.show()
# 运行应用程序
sys.exit(app.exec_())
运行界面:
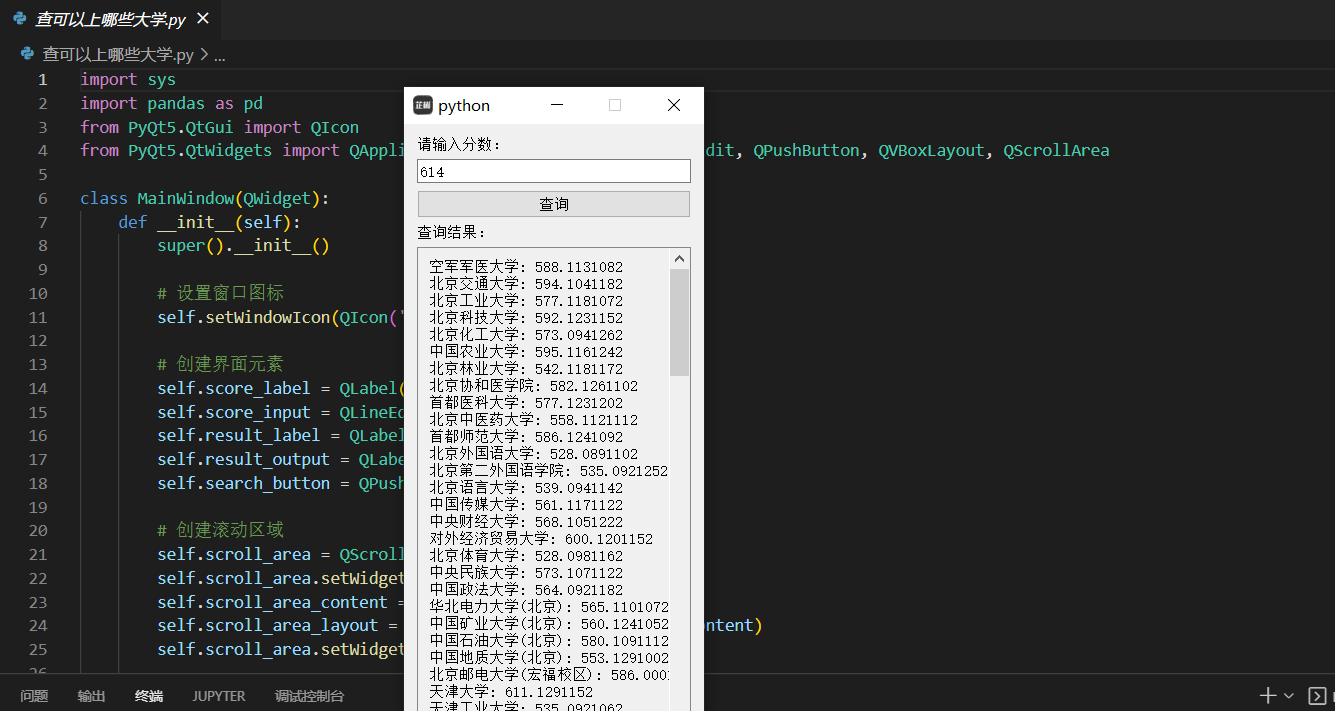
源码以及数据下载地址:
5分钟教你从爬虫到数据处理到图形化一个界面实现山西理科分数查学校-Python的更多相关文章
- 10分钟 教你学会Linux/Unix下的vi文本编辑器
10分钟 教你学会Linux/Unix下的vi文本编辑器 vi编辑器是Unix/Linux系统管理员必须学会使用的编辑器.看了不少关于vi的资料,终于得到这个总结.不敢独享,和你们共享. 首先,记住v ...
- 3分钟教你做一个iphone手机浏览器
3分钟教你做一个iphone手机浏览器 第一步:新建一个Single View工程: 第二步:新建好工程,关闭arc. 第三步:拖放一个Text Field 一个UIButton 和一个 UIWebV ...
- GC算法精解(五分钟教你终极算法---分代搜集算法)
GC算法精解(五分钟教你终极算法---分代搜集算法) 引言 何为终极算法? 其实就是现在的JVM采用的算法,并非真正的终极.说不定若干年以后,还会有新的终极算法,而且几乎是一定会有,因为LZ相信高人们 ...
- 【python】10分钟教你用python打造贪吃蛇超详细教程
10分钟教你用python打造贪吃蛇超详细教程 在家闲着没妹子约, 刚好最近又学了一下python,听说pygame挺好玩的.今天就在家研究一下, 弄了个贪吃蛇出来.希望大家喜欢. 先看程序效果: 0 ...
- 10分钟教你用Python打造天气机器人+关键字自动回复+定时发送
01 前言 Hello,各位小伙伴.自上次我们介绍了Python实现天气预报的功能以后,那个小程序还有诸多不完善的地方,今天,我们再次来完善一下我们的小程序.比如我们想给机器人发“天气”等关键字,它就 ...
- 10分钟教你用Python打造微信天气预报机器人
01 前言 最近武汉的天气越来越恶劣了.动不动就下雨,所以,拥有一款好的天气预报工具,对于我们大学生来说,还真是挺重要的了.好了,自己动手,丰衣足食,我们来用Python打造一个天气预报的微信机器人吧 ...
- 10分钟教你用Python玩转微信之好友性别比例统计分析
01 前言+效果展示 想必,微信对于大家来说,是再熟悉不过的了.那么,大家想不想探索一下微信上的各种奥秘呢?今天,我们一起来简单分析一下微信上的好友性别比例吧~废话不多说,开始干活. 结果如下: 02 ...
- 10分钟教你用Python玩转微信之抓取好友个性签名制作词云
01 前言+展示 各位小伙伴我又来啦.今天带大家玩点好玩的东西,用Python抓取我们的微信好友个性签名,然后制作词云.怎样,有趣吧~好了,下面开始干活.我知道你们还是想先看看效果的. 后台登录: 词 ...
- 10分钟教你用VS2017将代码上传到GitHub
前言 关于微软的Visual Studio系列,真可谓是宇宙最强IDE了.不过,像小编这样的菜鸟级别也用不到几个功能.今天给大家介绍一个比较实用的功能吧,把Visual Studio 2017里面写好 ...
- 【C/C++】10分钟教你用C++写一个贪吃蛇附带AI功能(附源代码详解和下载)
C++编写贪吃蛇小游戏快速入门 刚学完C++.一时兴起,就花几天时间手动做了个贪吃蛇,后来觉得不过瘾,于是又加入了AI功能.希望大家Enjoy It. 效果图示 AI模式演示 imageimage 整 ...
随机推荐
- 将字符串变成数组split
字符串变成数组,常用来获取数组中我们需要的值. var str="http://op/adfie/life.png"; let arr=str.split('.'); consol ...
- 【JS 逆向百例】Fiddler 插件 Hook 实战,某创帮登录逆向
关注微信公众号:K哥爬虫,QQ交流群:808574309,持续分享爬虫进阶.JS/安卓逆向等技术干货! 声明 本文章中所有内容仅供学习交流,抓包内容.敏感网址.数据接口均已做脱敏处理,严禁用于商业用途 ...
- Go Plugin介绍
以下内容来自官方文档. go version: 1.17.5 综述 plugin包实现了Go插件的加载和符号解析. Go插件是一个包括了可导出函数和变量的main包(可以没有main()函数),构建时 ...
- python代码的tab和空格缩进互转
代码规范 在我们项目中python代码使用tab缩进,并统一大家的编辑器设置. 如果同一个python文件中即有空格又有tab缩进,那么运行此文件会报错. 关于使用空格还是tab,这里就不展开讨论了, ...
- 微信小程序-应用程序生命周期方法
官方文档地址:https://developers.weixin.qq.com/miniprogram/dev/reference/api/App.html // app.js App({ onLau ...
- 如何控制Tomcat的catalina.out的大小
catalina.out文件,数据主要来源为:System.out 和 System.err 在控制台上直接输出的信息. 编码时应避免使用System.out.println()和e.printSta ...
- centos6.5安装MongoDB4.4.23
前言 1.目前MongoDB最新稳定版本是:6.0.8 2.MongoDB 5+和6+版本已不支持centos6.2+系统,参考https://docs.mongoing.com/install-mo ...
- P7167 [eJOI2020 Day1] Fountain 题解
题目链接:Fountain 很不错的基础算法组合题:单调栈+倍增 首先考虑到一个事实,就是下面第一个比当前半径大的位置会成为移动的第一次落脚点,抽象下就是下面出现的第一次比自身大的半径,这个问题显然可 ...
- Java - CodeForces - 266A
题目: 桌子上有n块石头排成一行,每一块都可以是红色.绿色或蓝色.计算从表中取出的石头的最小数量,以便相邻的任何两块石头具有不同的颜色.如果一排石头之间没有其他石头,则认为它们相邻. 输入: 第一行包 ...
- 一个关于用netty的小错误反思
一个关于用netty的小认知 在使用netty时,观看了黑马的netty网课,没想就直接用他的依赖了 依赖如下 <dependency> <groupId>io.netty&l ...