【Java 进阶篇】使用 Stream 流和 Lambda 组装复杂父子树形结构(List 集合形式)
前言
在最近的开发中,一星期内遇到了两个类似的需求:返回组装好的部门树、返回组装好的地区信息树,最终都需要返回 List 集合对象给前端。
于是在经过需求分析和探索实践后,我对于这种基于 Stream 和 List 结构的父、子树形结构的操作有了新的认识,现在拿出来和大家作分享交流。
一般来说完成这样的需求大多数人会想到递归,但递归的方式弊端过于明显:方法多次自调用效率很低、数据量大容易导致堆栈溢出、随着树深度的增加其时间复杂度会呈指数级增加等。
核心思路如下:
一次数据库查询全部数据(几万条),其它全是内存操作、性能高;
同时熟练使用 stream 流操作、Lambda 表达式、Java 地址引用,完成组装。
一、以部门结构为例
这里的实体是放在 MySQL 里的,使用简单的封装好的查询语句,这个很简单,剩下的就是内存操作了。
1.1实体
租户表:租户就是一个组织或者公司,所以每个租户都有自己的部门。下面的表结构我只列了一些核心的字段,其它不重要。
@Data
public class PmTenant {
/**
* 主键Id
*/
@TableId(type = IdType.ASSIGN_ID)
private Long id;
/**
* 租户名称
*/
private String tenantName;
/**
* 租户唯一编码,对外暴露
*/
private String tenantCode;
/**
* 租户Id
*/
private String tenantId;
/**
* 租户状态,0可用,1禁用
*/
private Integer status;
}
部门表:公司里都会有许多的部门,一个部门里还有部门。从最顶层公司到你所在的的部门,可能会有多达六、七层。以下同样只展示核心字段:
@Data
public class PmDept {
/**
* 主键id
*/
@TableId(type = IdType.ASSIGN_ID)
private Integer id;
/**
* 父部门Id
*/
private Integer parentDeptId;
/**
* 部门id,全局唯一,所有系统用
*/
private Integer deptId;
/**
* 部门名称
*/
private String deptName;
/**
* 部门所处的排序
*/
private Integer orderNum;
/**
* 部门所处的层级
*/
private Integer depth;
/**
* 部门状态,0可用,1删除
*/
private Integer status;
/**
* 租户id
*/
private String tenantId;
/**
* 租户编码
*/
private String tenantCode;
}
1.2返回VO
这个返回的VO是给前端的,里面的子节点集合属性 childrenNodeList ,是一个关键字段,所有该方式返回树结构的 VO 都需要有该字段来”封装自己“。
@Data
public class DeptTreeNodeVO implements Serializable {
/**
* 子节点 list 集合,封装自己
*/
private List<DeptTreeNodeVO> childrenNodeList;
/**
* 部门Id
*/
protected Integer deptId;
/**
* 父部门Id
*/
protected Integer parentDeptId;
/**
* 部门名称
*/
protected String deptName;
}
1.3具体实现
下面直接上代码,注释已经说的比较清楚了:
@Resource
private PmTenantService pmTenantService;
@Resource
private PmDeptMapper pmDeptMapper;
@Override
public List<DeptTreeNodeVO> assembleTree(){
//租户信息列表,这里是两个租户
List<PmTenant> tenantList = this.pmTenantService.list();
//step1:最外层根据租户去组装,有两个租户那么 Stream 就会遍历组装两次;换句话说,如果只有一个租户,就不需要最外层的 Stream
List<DeptTreeNodeVO> resultList = tenantList.stream().map(tenant -> {
//注:这里 map 只是简单转换了返回的对象属性(返回需要的类型),本质还是该租户下的所有部门数据
List<DeptTreeNodeVO> deptTreeNodeVOList = this.selectAllDeptByTenantCode(tenant.getTenantCode())
.stream().map(val -> val.convertExt(DeptTreeNodeVO.class)).collect(Collectors.toList());
//step2:利用父节点分组,即按照该租户下的所有部门的父Id进行分组,把所有的子节点List集合都找出来并一层层分好组
Map<Integer, List<DeptTreeNodeVO>> listMap = deptTreeNodeVOList.parallelStream()
.collect(Collectors.groupingBy(DeptTreeNodeVO::getParentDeptId));
//step3:关键一步,关联上子部门,将子部门的List集合经过遍历一层层地放置好,最终会得到完整的部门父子关系List集合
deptTreeNodeVOList.forEach(val -> val.setChildrenNodeList(listMap.get(val.getDeptId())));
//step4:过滤出顶级部门,即所有的子部门数据都归属于一个顶级父Id
List<DeptTreeNodeVO> allChildrenList = deptTreeNodeVOList.stream()
.filter(val -> val.getParentDeptId().equals(NumberUtils.INTEGER_ZERO)).collect(Collectors.toList());
//组装最外层关于租户需要的数据,实质已经不是处理部门数据了
DeptTreeNodeVO node = new DeptTreeNodeVO();
node.setChildrenNodeList(allChildrenList);
node.setDeptName(tenant.getTenantName());
return node;
}).collect(Collectors.toList());
return Optional.of(resultList).orElse(null);
}
/**
* 获取某个租户下的所有部门信息
*
* @return
*/
public List<PmDept> selectAllDeptByTenantCode(String tenantCode) {
return pmDeptMapper.selectList(new LambdaQueryWrapper<PmDept>()
.eq(PmDept::getTenantCode, tenantCode)
.eq(PmDept::getStatus, PmDeptStatus.DISABLE.getStatus()));
}
1.4效果展示
我这里测试的例子是只有三层,数据也没有完全展开,当然五六层也是没问题的。
只要总的部门数据量在一两万条以内(啥情况部门数量会有几万个?部门表一般是独立于其它表的)速度都是比较快的,服务器性能(主要内存给力)好的话,基本整个请求/响应(抛开网络I/O消耗)可以在一秒内完成。
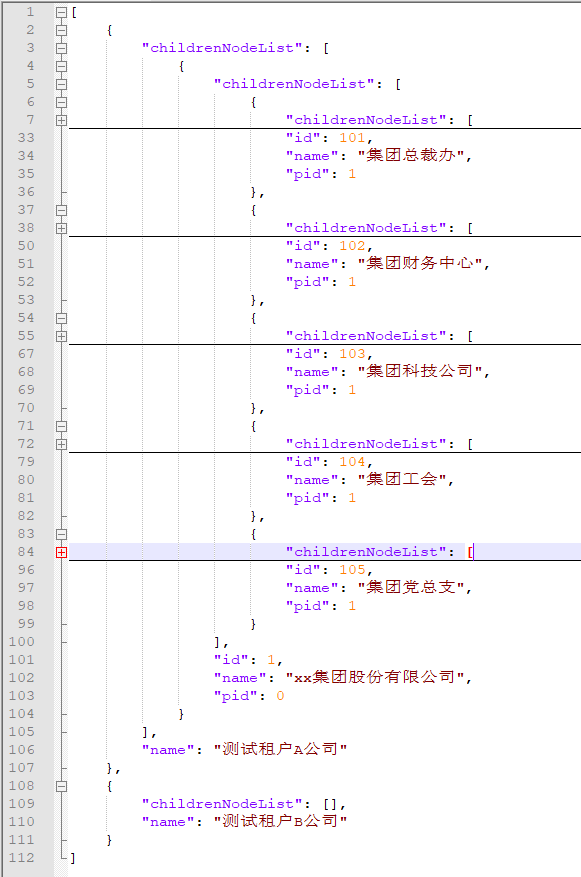
部门树结构效果图
二、以省市县结构为例
这里的实体是放在 MongoDB 里的,不熟悉 MongoDB 也不要紧,这里只需要使用一次查全量的语句。
2.1实体
全国行政区表:全国的行政区包括省/直辖市/自治区、地级市、区/县级市/县这三级,再往下的街道/镇、以及下面的村/小组就不包含了。同样也是只留关键属性:
@Data
public class Region {
/**
* 区域id
*/
@Id
public Long id;
/**
* 父Id
*/
public Long parentId;
/**
* 地区名称
*/
public String name;
/**
* 地区全称
*/
public String district;
/**
* 所属省
*/
public String province;
/**
* 所属地级市
*/
public String city;
/**
* 所属省Id
*/
public Long provinceId;
/**
* 所属地级市Id
*/
public Long cityId;
/**
* 所处层级
*/
public Integer depth;
}
2.2返回VO
同样,这个里面的子节点集合属性 childrenRegionList,是一个关键字段,所有该方式返回树结构的 VO 都需要有该字段来”封装自己“。
@Data
public class RegionCascadeVO extends RegionVO {
/**
* 子节点 list 集合
*/
private List<RegionCascadeVO> childrenRegionList;
/**
* 区域id
*/
public Long id;
/**
* 地区名称
*/
public String name;
/**
* 所处层级
*/
public Integer depth;
/**
* 省
*/
public String province;
/**
* 城市
*/
public String city;
/**
* 地区全称
*/
public String district;
/**
* 父Id
*/
public Long parentId;
/**
* 所属省Id
*/
public Long provinceId;
/**
* 所属地级市Id
*/
public Long cityId;
}
2.3具体实现
下面同样直接上代码,注释比较详细:
@Resource
private RegionRepository regionRepository;
@Override
public List<RegionCascadeVO> quickAllTree() {
//第一步,从数据库中查出所有数据,按照排序条件进行排序,本质上还是这个所有数据的 List 集合
List<RegionCascadeVO> regionCascadeVOList = this.regionRepository.findAll().stream()
//注:这里使用 map 映射了需要返回的VO,即相同的属性字段就会转换
.map(val -> val.convertExt(RegionCascadeVO.class))
//业务需要的排序规则,使用工具来处理
.sorted((s1, s2) -> RegionSortUtil.citySort(s1.getName(), s2.getName()))
.sorted((s1, s2) -> RegionSortUtil.countySort(s1.getName(), s2.getName()))
.collect(Collectors.toList());
//第二步,根据父Id 字段进行分组,即所有数据都会按照第一层至最后一层都按照父子关系进行分组;注意,是对所有数据分组
Map<Long, List<RegionCascadeVO>> listMap = regionCascadeVOList.parallelStream().collect(Collectors.groupingBy(RegionCascadeVO::getParentId));
//第三步,也是最关键的一步,将父Id下面的所有子数据List集合,经过遍历后都一层层地放置好,最终会得到一个包含父子关系的完整List
regionCascadeVOList.forEach(val -> val.setChildrenRegionList(listMap.get(val.getId())));
//第四步,过滤出符合顶层父Id的所有数据,即所有数据都归属于一个顶层父Id
return regionCascadeVOList.stream().filter(val -> RegionConstant.CHINA_ID.equals(val.getParentId())).collect(Collectors.toList());
}
2.4效果展示
我这里测试环境的例子是只有省/直辖市/自治区、地级市、区/县级市/县这三级,数据也没有完全展开,当然到下面的镇/街道,乃至村/小组也是没问题的。
这里总的测试数据量是几千条,如果加上镇/街道应该得有几万条,速度也还是是比较快的,服务器性能(主要内存给力)好的话,基本整个请求/响应(抛开网络I/O消耗)可以在一秒内完成。
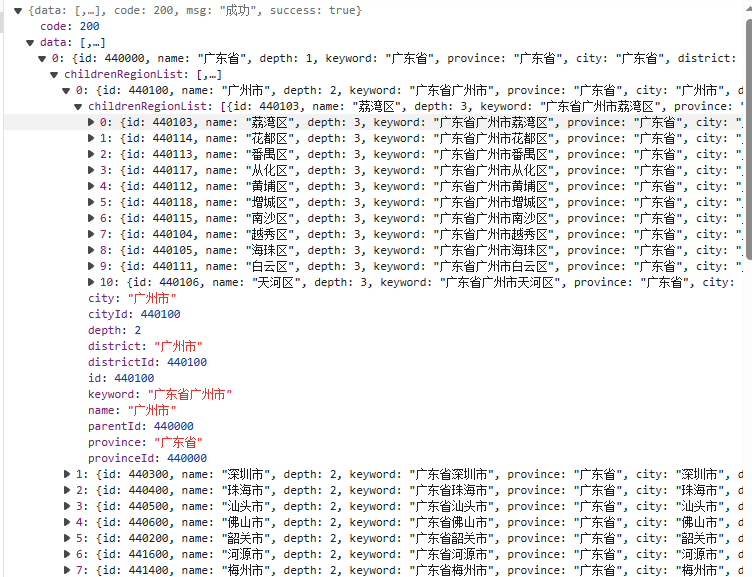
中国行政区域信息层次结构效果
时间消耗,这里响应只有两百多毫秒,如下图的接口的性能展示:

接口性能展示
原因只有一个:数据库只查一次,把查到的全部数据放内存里,剩下的就是 Stream 的内存操作,都是地址的引用,性能是比较高的。
三、文章小结
使用 Stream 流组装复杂父子树形结构(List 集合形式)的分享到这里就结束了,编码没有捷径,都是项目实践里出真知,一点点摸索攒经验。
如有不足和错误,或者你有更好的解决思路,欢迎大家的指正和交流!
【Java 进阶篇】使用 Stream 流和 Lambda 组装复杂父子树形结构(List 集合形式)的更多相关文章
- 【Java SE进阶】Day13 Stream流、方法引用
〇.总结 Stream流的方法:forEach.filter.map.count.limit.skip.concat(结合之前的Collectors接口) 方法引用:Lambda的其他类方法体相同,如 ...
- Java进阶篇之十五 ----- JDK1.8的Lambda、Stream和日期的使用详解(很详细)
前言 本篇主要讲述是Java中JDK1.8的一些新语法特性使用,主要是Lambda.Stream和LocalDate日期的一些使用讲解. Lambda Lambda介绍 Lambda 表达式(lamb ...
- java进阶篇——Stream流编程
Stream流 函数式接口 1.消费型接口--Consumer @FunctionalInterface public interface Consumer<T> { /** * 对给定的 ...
- Java提升四:Stream流
1.Stream流的定义 Stream是Java中的一个接口.它的作用类似于迭代器,但其功能比迭代器强大,主要用于对数组和集合的操作. Stream中的流式思想:每一步只操作,不存储. 2.Strea ...
- Java进阶篇(六)——Swing程序设计(下)
三.布局管理器 Swing中,每个组件在容器中都有一个具体的位置和大小,在容器中摆放各自组件时很难判断其具体位置和大小,这里我们就要引入布局管理器了,它提供了基本的布局功能,可以有效的处理整个窗体的布 ...
- 再来看看Java的新特性——Stream流
半年前开始试着使用Java的新特性,给我印象最深的就是Stream流和Optional.其中Stream提高了看法效率,让代码看起来十分清爽. 为什么要使用流? 摘要中已经说明了,为了提高开发效率.流 ...
- Stream流、lambda表达式、方法引用、构造引用
函数式接口 函数接口为lambda表达式和方法引用提供目标类型,就是提供支持的接口里面只有且必须只有一个抽象方法, 如果接口只有一个抽象方法,java默认他为函数式接口 @FunctionalInte ...
- Java进阶篇(六)——Swing程序设计(上)
Swing是GUI(图形用户界面)开发工具包,内容有很多,这里会分块编写,但在进阶篇中只编写Swing中的基本要素,包括容器.组件和布局等,更深入的内容会在高级篇中出现.想深入学习的朋友们可查阅有关资 ...
- Java进阶篇(一)——接口、继承与多态
前几篇是Java的入门篇,主要是了解一下Java语言的相关知识,从本篇开始是Java的进阶篇,这部分内容可以帮助大家用Java开发一些小型应用程序,或者一些小游戏等等. 本篇的主题是接口.继承与多态, ...
- Java进阶篇设计模式之六 ----- 组合模式和过滤器模式
前言 在上一篇中我们学习了结构型模式的外观模式和装饰器模式.本篇则来学习下组合模式和过滤器模式. 组合模式 简介 组合模式是用于把一组相似的对象当作一个单一的对象.组合模式依据树形结构来组合对象,用来 ...
随机推荐
- 聊聊如何在Java应用中发送短信
很多业务场景里,我们都需要发送短信,比如登陆验证码.告警.营销通知.节日祝福等等. 这篇文章,我们聊聊 Java 应用中如何优雅的发送短信. 1 客户端/服务端两种模式 Java 应用中发送短信通常需 ...
- Rasa NLU中的组件
Rasa NLU部分主要是解决NER(序列建模)和意图识别(分类建模)这2个任务.Rasa NLP是一个基于DAG的通用框架,图中的顶点即组件.组件特征包括有顺序关系.可相互替换.可互斥和可同时使 ...
- JAVA学习week2
这周:根据老师在群里面推荐的JAV学习路线,初步规划了一下学习方案 并找到了相关的视频,目前来说在学习SE.学习内容:环境变量的配置和简单的hello world程序书写的注意点 下周:打算进行简单的 ...
- 从0到1,手把手带你开发截图工具ScreenCap------001实现基本的截图功能
ScreenCap---Version:001 说明 从0到1,手把手带你开发windows端的截屏软件ScreenCap 当前版本:ScreenCap---001 支持全屏截图 支持鼠标拖动截图区域 ...
- Reactor实战,创建一个简单的单线程Reactor(理解了就相当于理解了多线程的Reactor)
单线程Reactor package org.example.utils.echo.single; import java.io.IOException; import java.net.InetSo ...
- [ARC158D] Equation
Problem Statement You are given a positive integer $n$, and a prime number $p$ at least $5$. Find a ...
- MyBatisPlus简介
MyBatisPlus特性 国内的一个网站 网站地址简介 | MyBatis-Plus (baomidou.com)
- Vue2路由嵌套是注意子路由path问题
1.当子路由以/开始时,它会被视为根路由,并且会显示在URL的根路径中 2.当子路由不以/开始时,它将被视为相对路径,相对于父路由的路径
- 三种方式查询三级分类Tree
话不多说,直接上代码 方式一:for循环嵌套一下 /** * 查询三级分类 * * @return */ @Override public List<GoodsType> findNode ...
- C++ 核心指南 —— 性能
C++ 核心指南 -- 性能 阅读建议:先阅读 <性能优化的一般策略及方法> 截至目前,C++ Core Guidelines 中关于性能优化的建议共有 18 条,而其中很大一部分是告诫你 ...