大数据 - ODS&DWD&DIM-SQL分享
大数据 ODS&DWD&DIM-SQL分享 需求
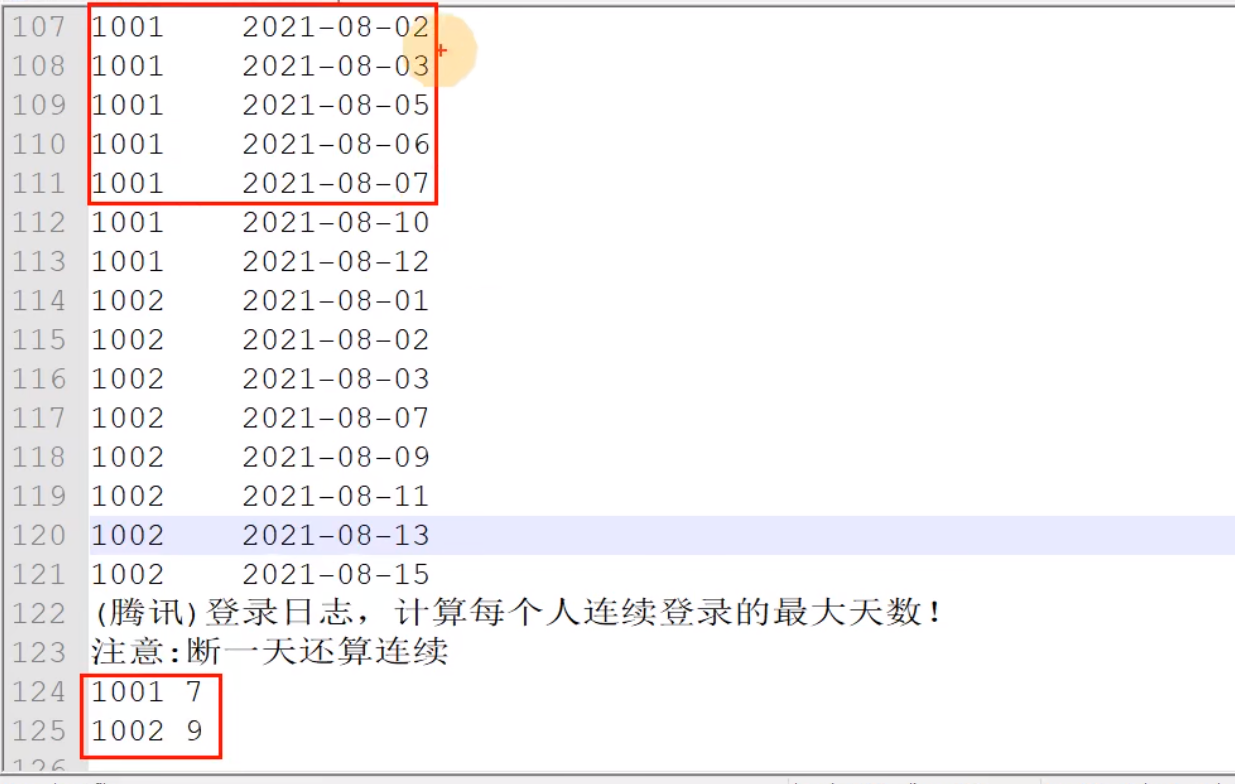
思路一:等差数列
断2天、3天,嵌套太多
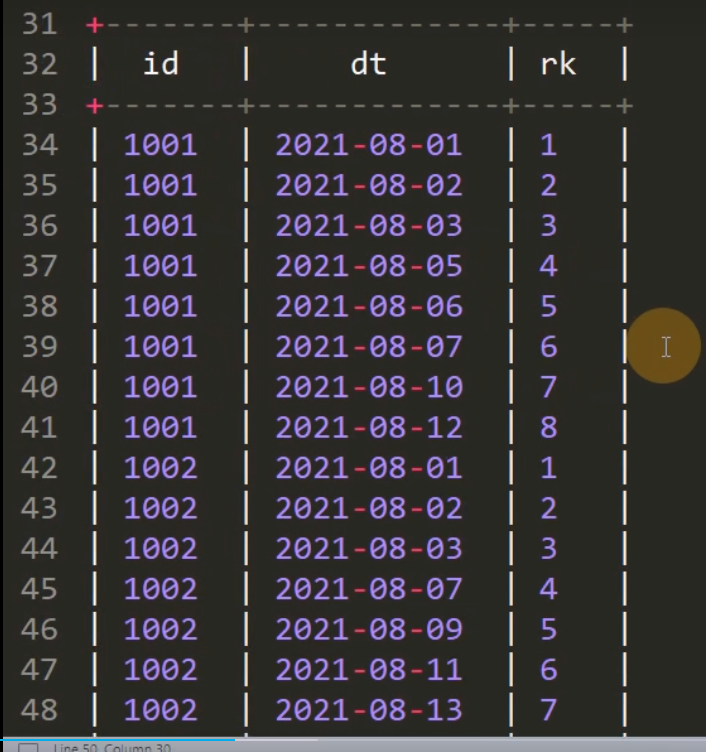
1.1 开窗,按照 id 分组,同时按照 dt 排序,求 Rank
-- linux 中空格不能用 tab 键
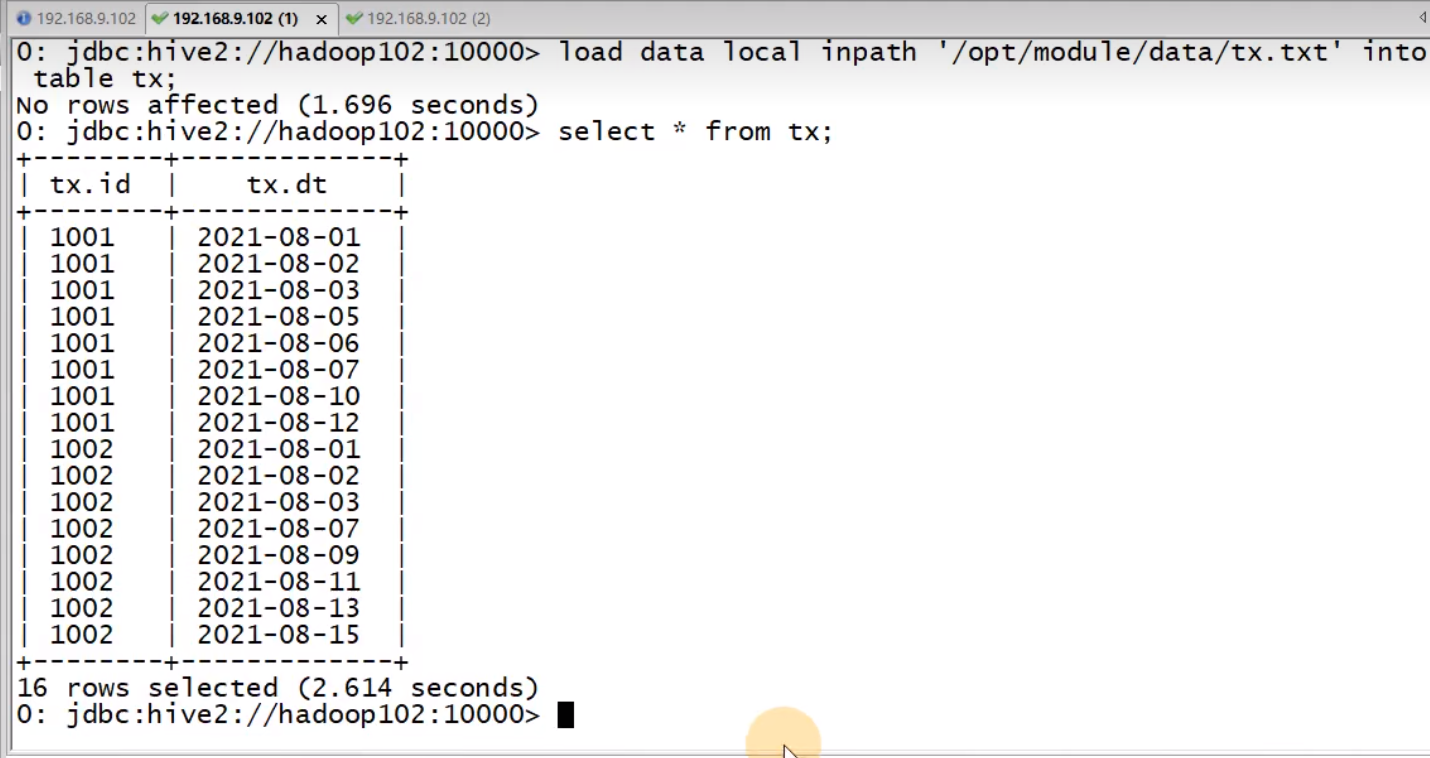
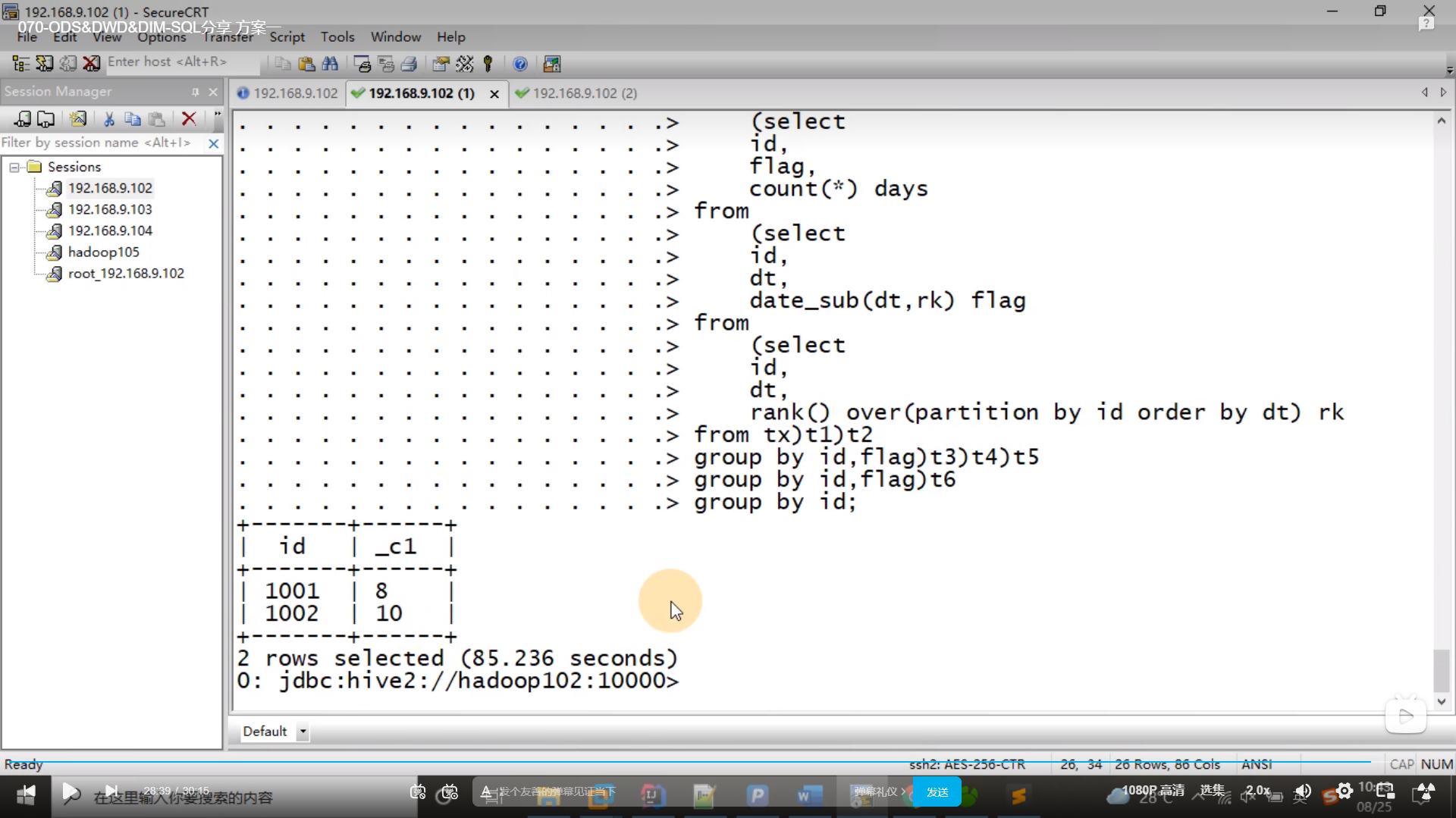
select id,dt,rank() over(partition by id order by dt) rk from tx;
1.2 将每行日期减去RK值,如果之前是连续的日期,则相减之后为相同日期
z: 等差
(x1+z)-(y1+z)=x1-y1
select id,dt,date_sub(dt,rk) flg
from (select id,dt,rank() over(partition by id order by dt) rk from tx) t1;
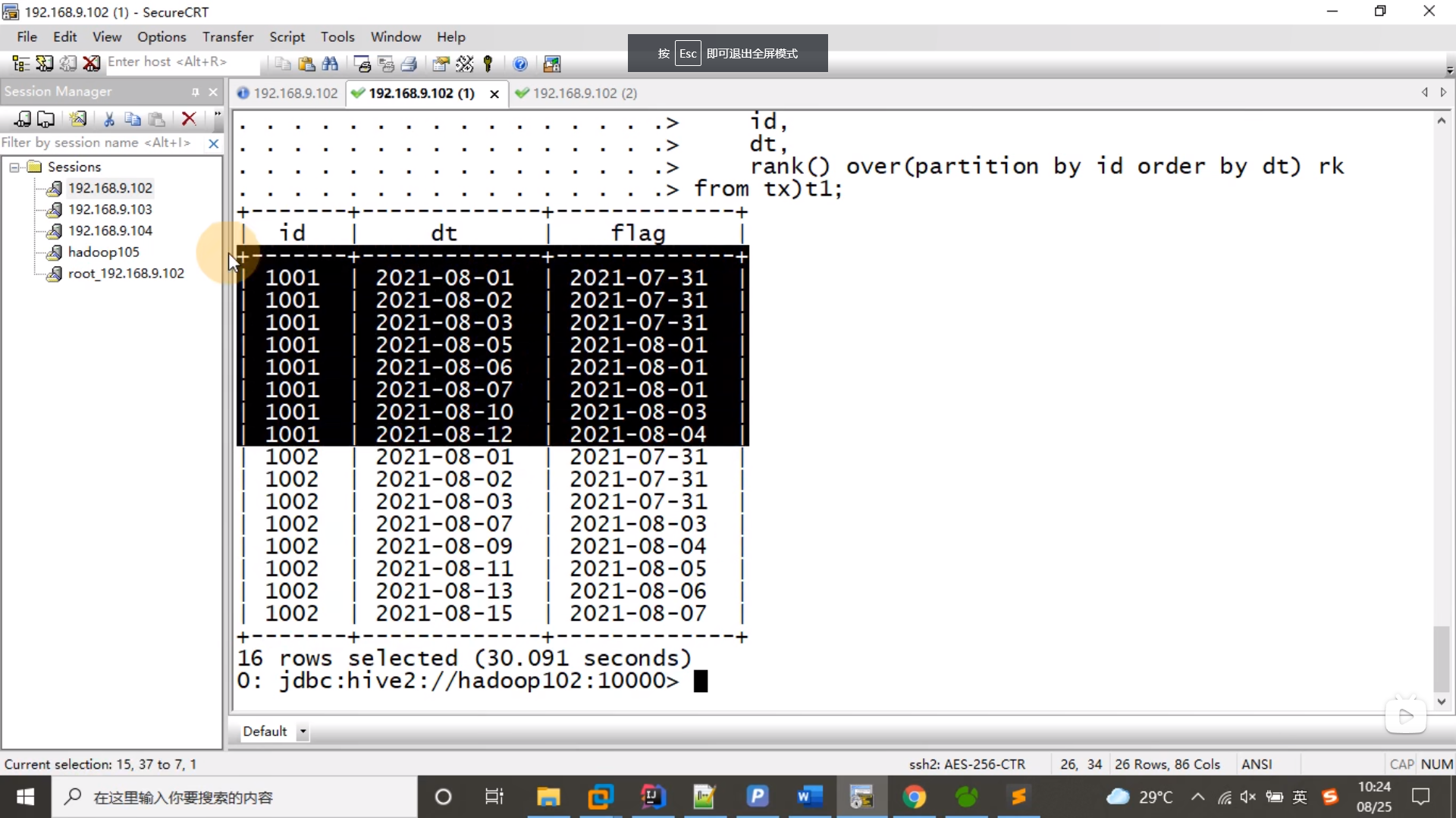
断一天的数据,flag 变成了连续
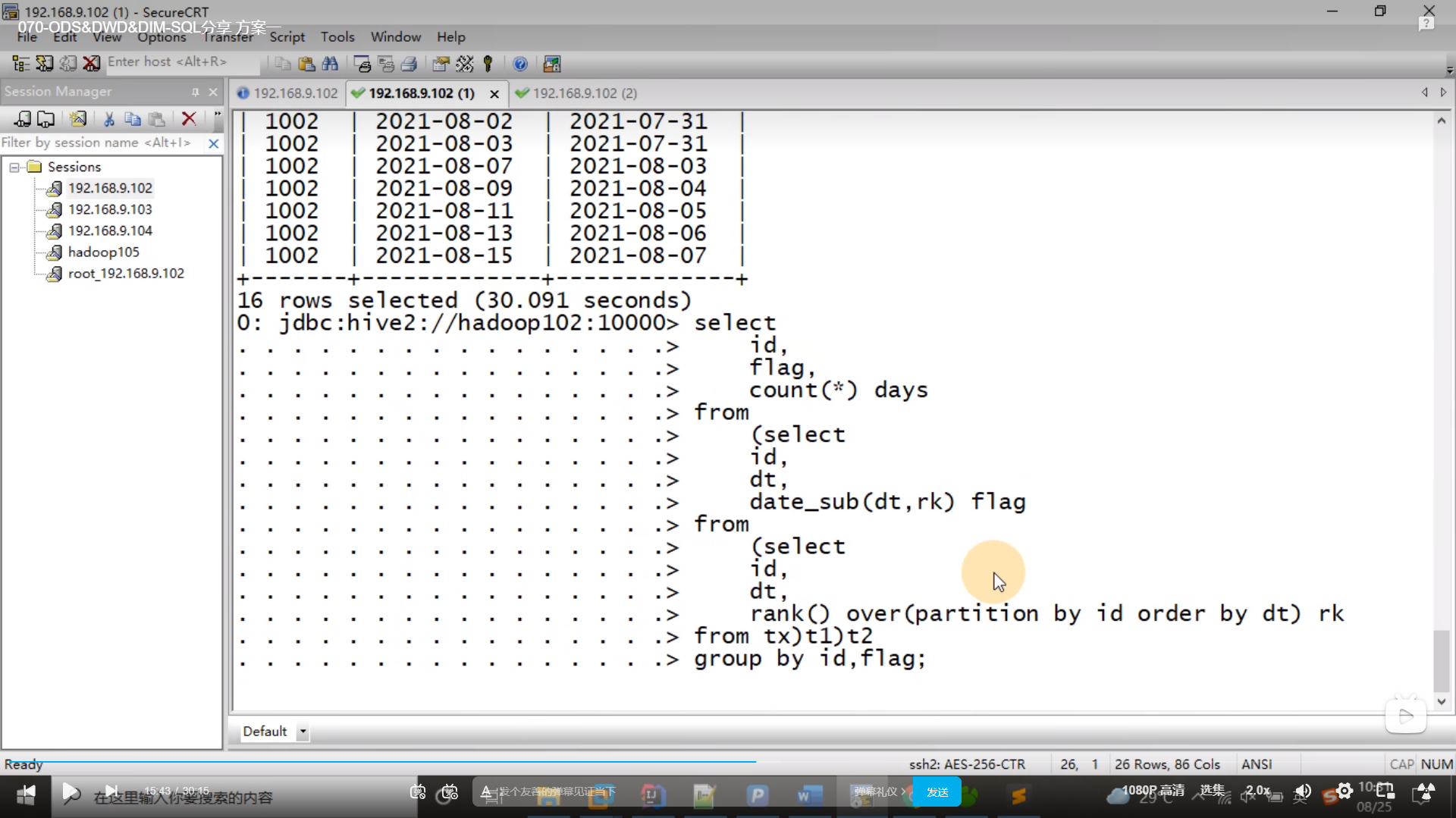
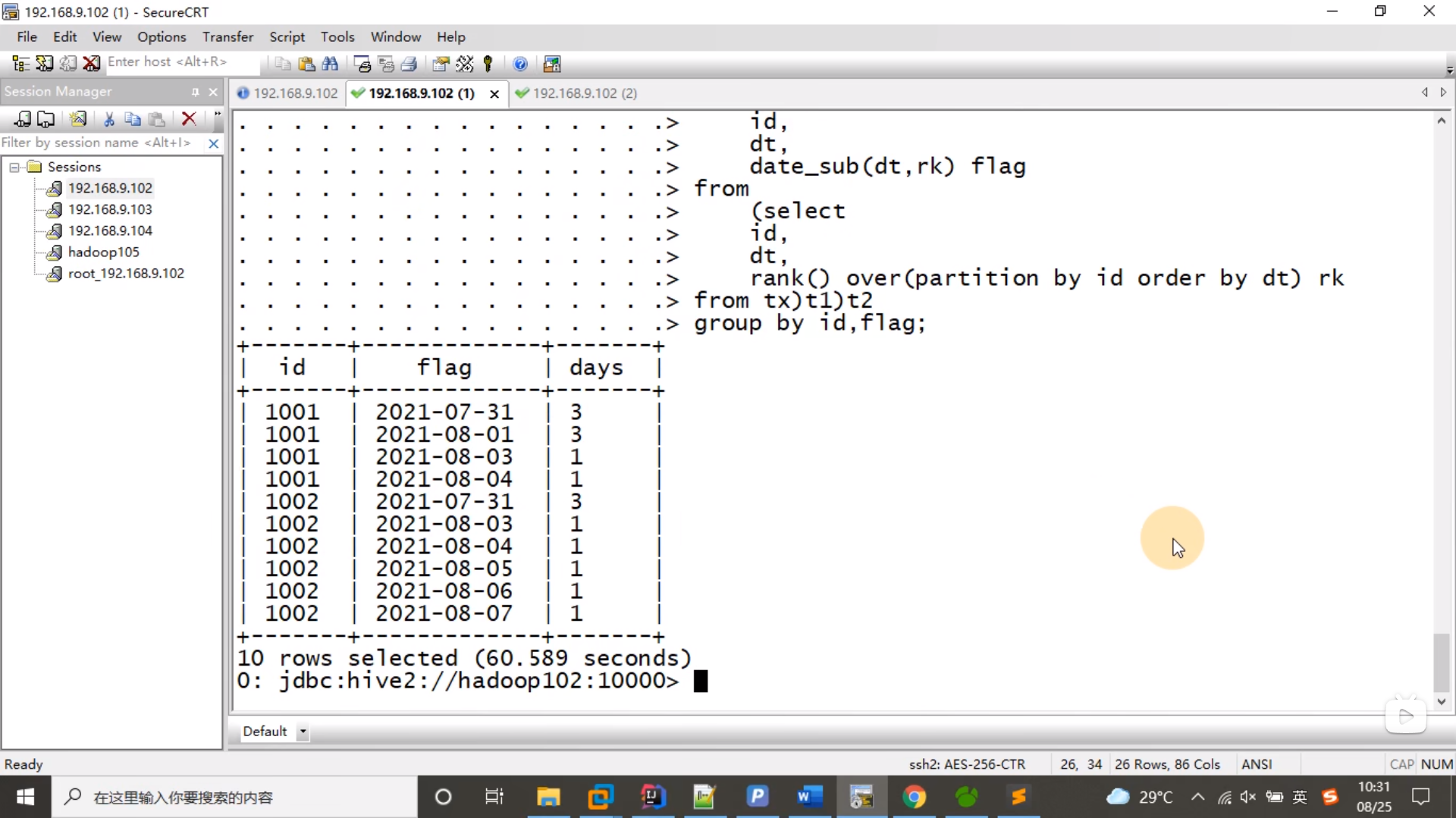
1.3 计算绝对连续的天数
select id,flag,count(*) days
from (
select id,dt,date_sub(dt,rk) flg
from (select id,dt,rank() over(partition by id order by dt) rk from tx) t1;
)t2 group by id,flag;
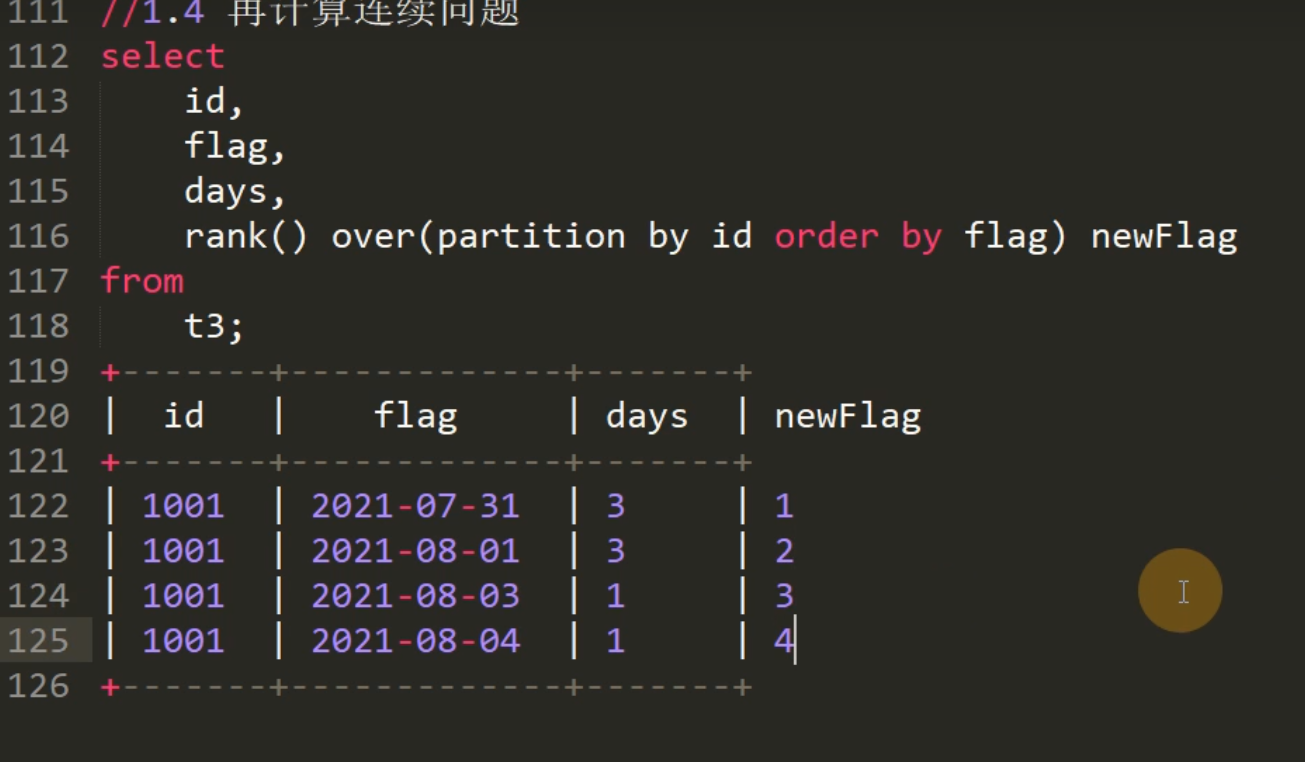
1.4 再计算连续问题
select id,flag,days,rank() over(partition by id order by flag) newFlag
from t3;
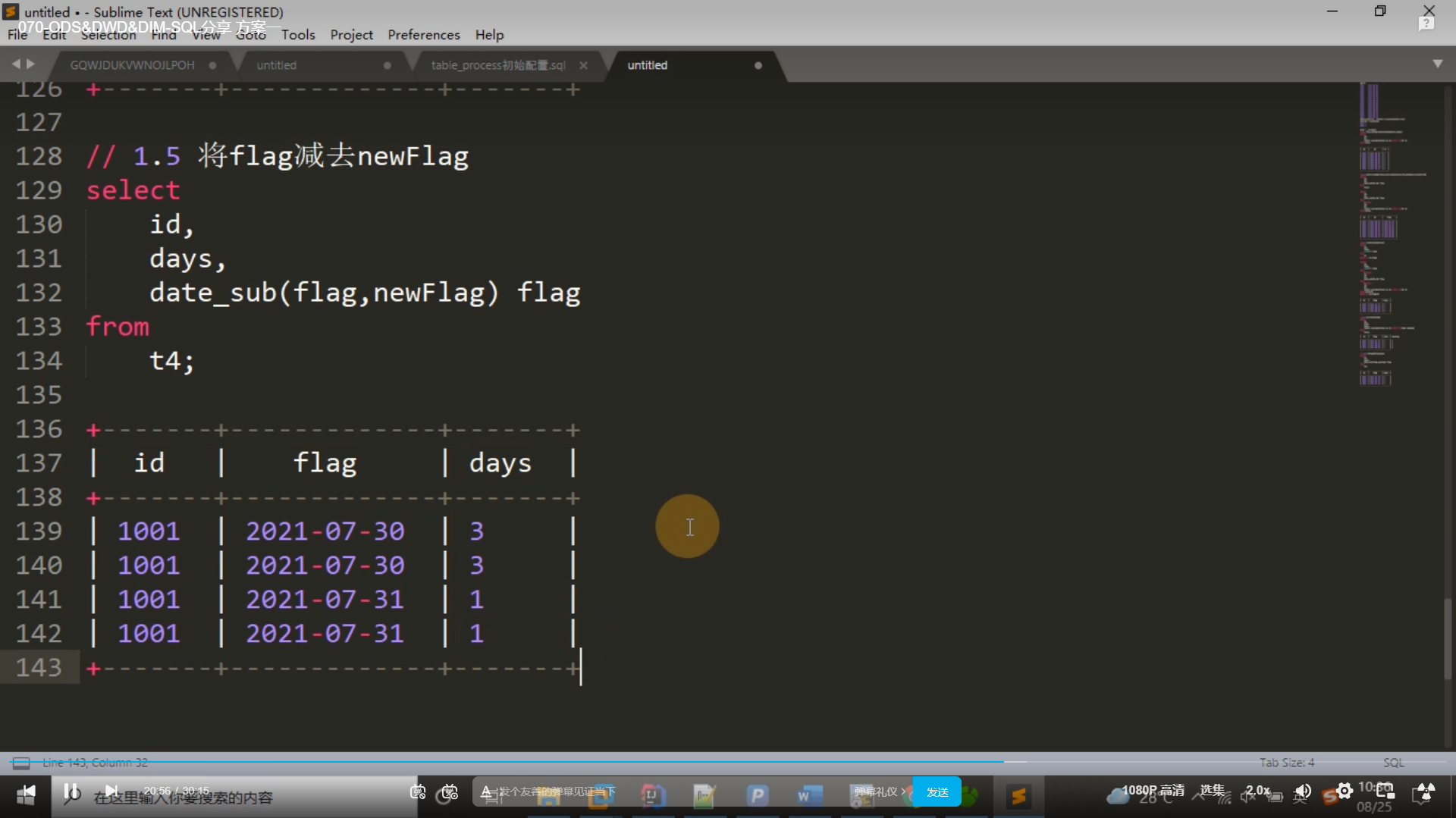
1.5 将 flag 减去 newflag
select id,days,date_sub(flag,newFlag) flag
from t4;t5
1.6 计算每个用户连续登录的天数,断一天也算
select id,sum(days)+count(1) days
from t5
group by id,flag;[t6]
1.7 计算最大连续天数
select id,max(days)
from t6
group by id;
准后再-1
思路二
2.1 将上一行数据下移
--下移默认值,一般给 1970-01-01,上移默认值一般 9999-01-01
select id,dt,lag(dt,1,'1970-01-01') over(partition by id order by dt) lagDt
from tx; t1
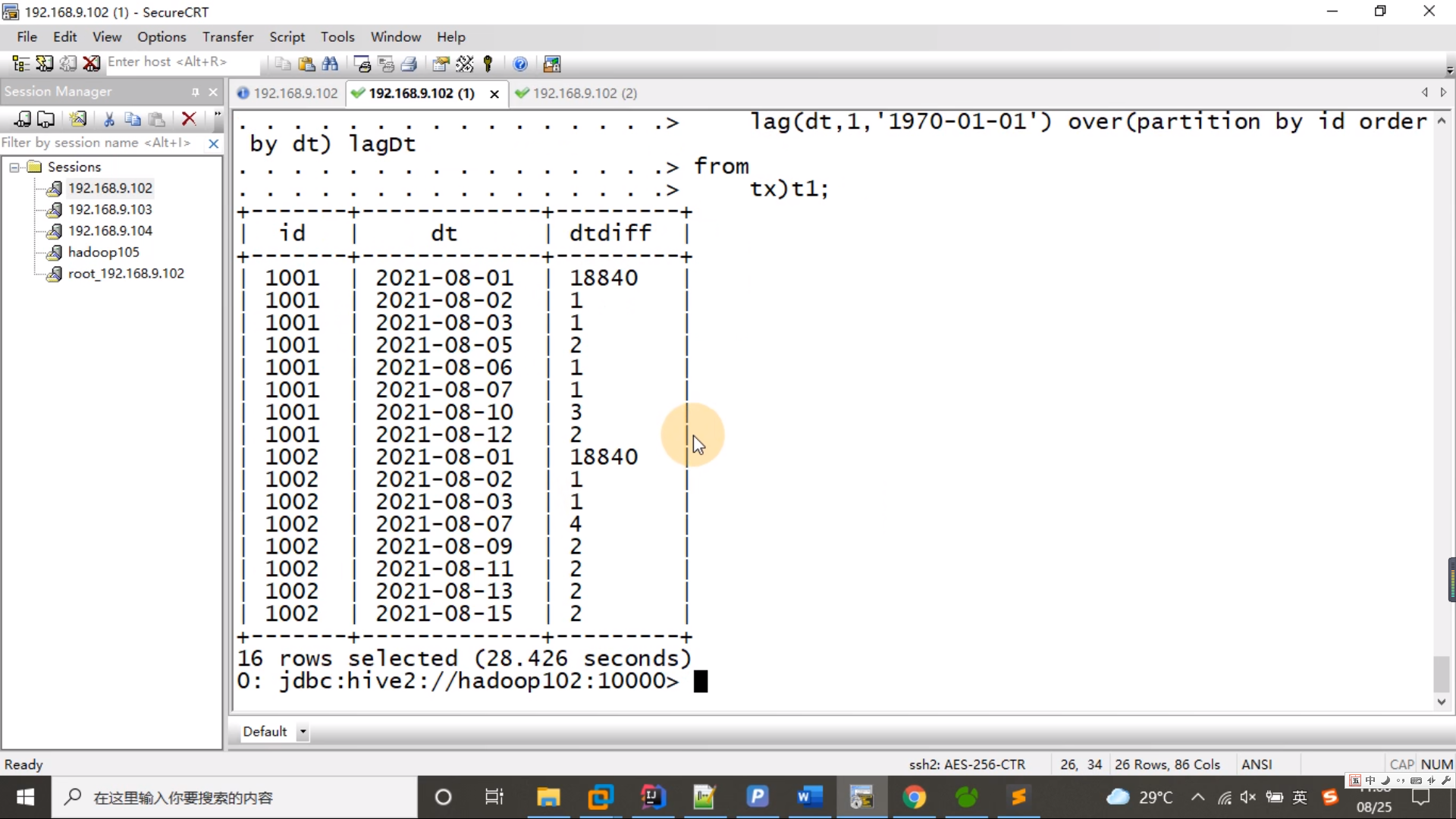
2.2 将当前行日期减去下移的日期
select id,dt,datediff(dt,lagDt) dtDiff
from t1; t2
执行
select id,dt,datediff(dt,lagDt) dtDiff
from (
select id,dt,lag(dt,1,'1970-01-01') over(partition by id order by dt) lagDt
from tx) t1;
每碰到一个 >2 的就分组 + 1
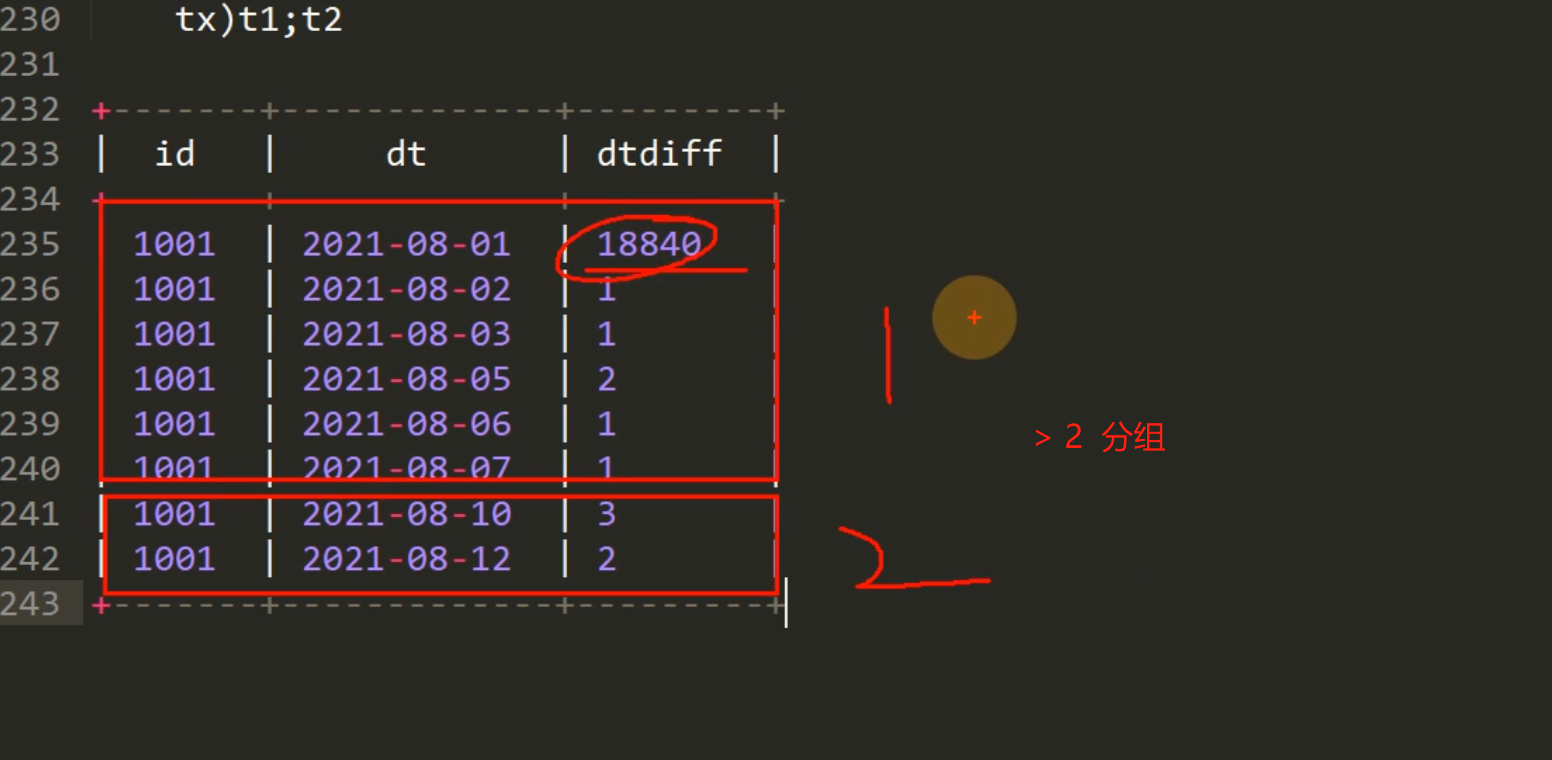
2.3 分组
select id,dt,sum(if(dtDiff>2,1,0)) over(partition by id order by dt) flag
from t2; t3
select id,dt,sum(if(dtDiff>2,1,0)) over(partition by id order by dt) flag
from (
select id,dt,datediff(dt,lagDt) dtDiff
from (
select id,dt,lag(dt,1,'1970-01-01') over(partition by id order by dt) lagDt
from tx) t1
) t2;
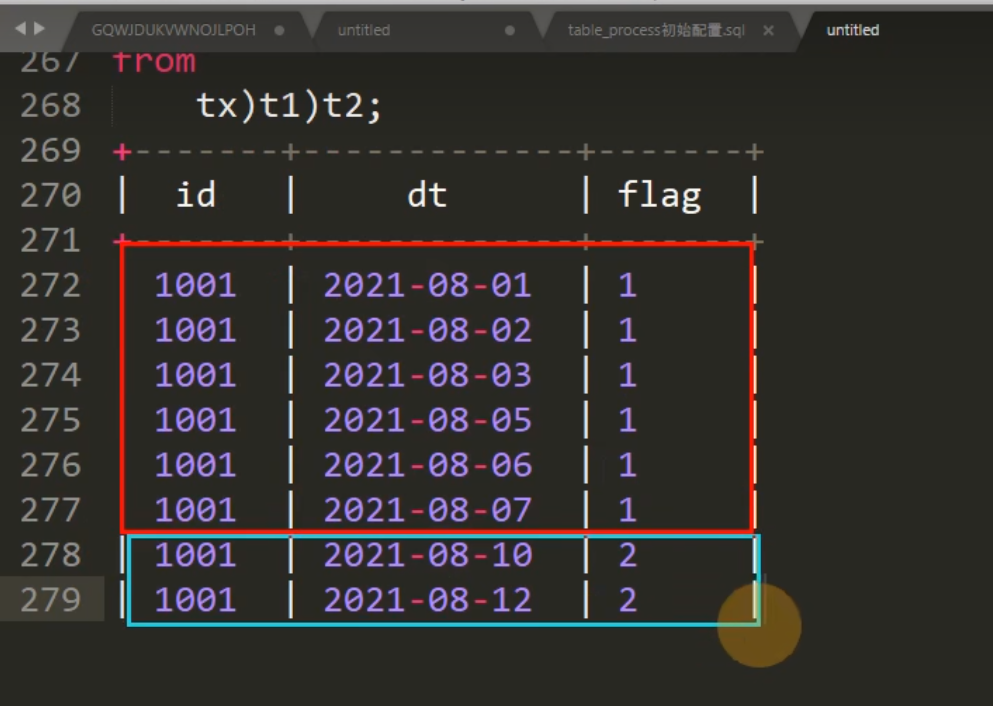
select id,flag,datediff(max(dt),min(dt))+1
from t3
group by id,flag;
带入执行
--断3天把2改成3,断4天把2改成4
select id,flag,datediff(max(dt),min(dt))+1
from (
select id,dt,sum(if(dtDiff>2,1,0)) over(partition by id order by dt) flag
from (
select id,dt,datediff(dt,lagDt) dtDiff
from (
select id,dt,lag(dt,1,'1970-01-01') over(partition by id order by dt) lagDt
from tx) t1
) t2
)t3
group by id,flag;
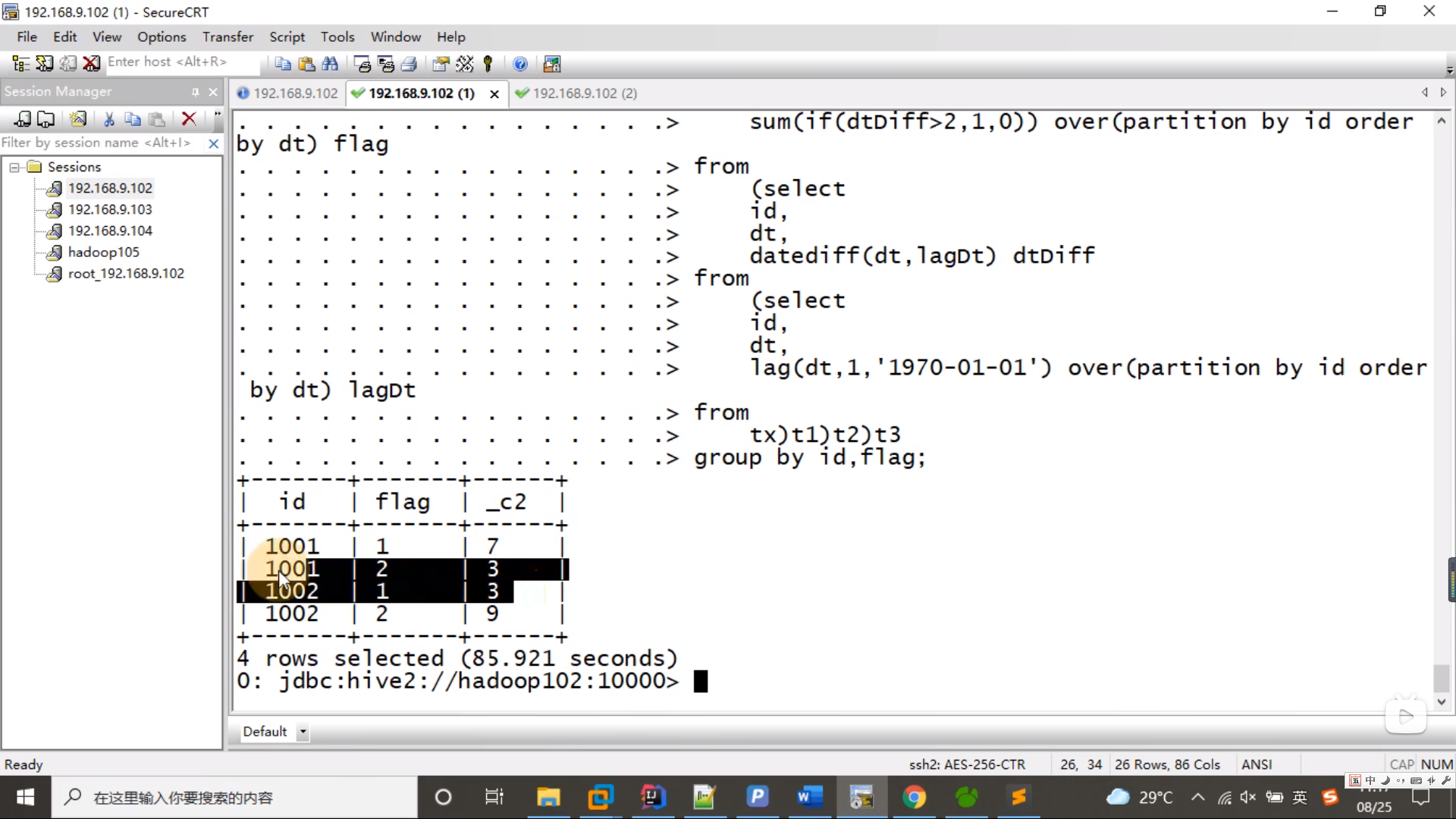
2.3 求分组后的最大值
HiveOnSpark: 有个BUG, datediff over 子查询 => null point
解决方案:
- 换MR引擎
- 将时间字段由 String 类型改成 Date 类型
https://www.bilibili.com/video/BV1Ju411o7f8/?p=69
大数据 - ODS&DWD&DIM-SQL分享的更多相关文章
- 大数据学习资料之SQL与NOSQL数据库
这几年的大数据热潮带动了一激活了一大批hadoop学习爱好者.有自学hadoop的,有报名培训班学习的.所有接触过hadoop的人都知道,单独搭建hadoop里每个组建都需要运行环境.修改配置文件测试 ...
- 大数据量下的SQL Server数据库自身优化
原文: http://www.d1net.com/bigdata/news/284983.html 1.1:增加次数据文件 从SQL SERVER 2005开始,数据库不默认生成NDF数据文件,一般情 ...
- 大数据不就是写SQL吗?
应届生小祖参加了个需求分析会回来后跟我说被产品怼了一句: "不就是写SQL吗,要那么久吗" 我去,欺负我小弟,这我肯定不能忍呀,于是我写了一篇文章发在了公司的wiki 贴出来给大家 ...
- 千万级大数据的Mysql数据库SQL语句优化
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- 大数据技术 - 为什么是SQL
在大数据处理以及分析中 SQL 的普及率非常高,几乎是每一个大数据工程师必须掌握的语言,甚至非数据处理岗位的人也在学习使用 SQL.今天这篇文章就聊聊 SQL 在数据分析中作用以及掌握 SQL 的必要 ...
- 大数据时代下的SQL Server第三方负载均衡方案----Moebius测试
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 架构原理(Architecture) 测试环境(Environment) 安装Moebius( ...
- (转)大数据时代下的SQL Server第三方负载均衡方案----Moebius测试
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 架构原理(Architecture) 测试环境(Environment) 安装Moebius( ...
- (转)大数据量下的SQL Server数据库优化
在SQL Server中,默认MDF文件初始大小为5MB,自增为1MB,不限增长,LDF初始为1MB,增长为10%,限制文件增长到一定的数目:一般设计中,使用SQL自带的设计即可,但是大型数据库设计 ...
- 大数据学习——hive的sql练习题
ABC三个hive表 每个表中都只有一列int类型且列名相同,求三个表中互不重复的数 create table a(age int) row format delimited fields termi ...
- 大数据学习——hive的sql练习
1新建一个数据库 create database db3; 2创建一个外部表 --外部表建表语句示例: create external table student_ext(Sno int,Sname ...
随机推荐
- 该如何选择ClickHouse的表引擎
该如何选择ClickHouse的表引擎 本文将介绍ClickHouse中一个非常重要的概念-表引擎(table engine).如果对MySQL熟悉的话,或许你应该听说过InnoDB和MyISAM存储 ...
- tcpdump必知必会
tcpdump原理 & 在tcp协议栈的位置 tcpdump用法 基于协议.主机.端口过滤 使用and or逻辑运算符做复杂的过滤操作 tcpdump flags 1. tcpdump原理 l ...
- SNN_TIPS
脉冲神经网络的研究思路: ANN2SNN 代表: 梯度下降法 代表: STDP 代表: 神经网络代差划分 以神经元实现功能为准: 优势 SNN是一个动态系统,在动态识别中发挥出色,比如语音识别和动态图 ...
- Linux TTY/PTS
转载:https://segmentfault.com/a/1190000009082089 当我们在键盘上敲下一个字母的时候,到底是怎么发送到相应的进程的呢?我们通过ps.who等命令看到的类似tt ...
- NOIP2023 游寄
NOIP2023 游寄 Day -2 遗憾生病离场回家. Day -1 速度赶往杭州,稍作复习. Day 1 正式开寄. 开题后,发现把所有题看了一遍,一如既往的又臭又长. T3 和 T4 感觉很不可 ...
- MySQL Group by 优化查询
Group by 未加索引 使用的是临时表,加文件排序(数据量小用内存排序) 加个索引(一般是联合索引) 注意:这里加的索引一般不会仅仅是group by后面的字段索引(大多数多少条件是一个以该字 ...
- VLOOKUP函数10种经典用法
VLOOKUP函数是Excel中非常常用的函数之一,可以用于在一个区域或表格中查找某个值,并返回该值所在行的另一个指定列中的数值.以下是VLOOKUP函数的10种经典用法: 基本的VLOOKUP用法: ...
- 叮咚,你的微信年度聊天报告请查收「GitHub 热点速览」
本周热点项目 WeChatMsg 是一个微信记录提取工具,据说它还能帮你分析聊天记录.生成你的年度聊天报告.而又到了年底,部分不幸的小伙伴要开始写年度总结了,这时候 self-operating-co ...
- 常见速率协议的CDR带宽情况
100G PAM4 4MHZ 802.3/OIF-CEI 50G PAM4 4MHZ 802.3/OIF-CEI 28G PAM4 4MHZ 802.3/OIF-CEI 28G PAM4 4MHZ 8 ...
- RAM 低功耗
常见的ram低功耗方法包括的shutdown信号,1 关闭,0不关闭正常功能. ls低睡眠,深度睡眠. 关闭时节省90%功耗,数据丢失. 重新启动需要50ns以上. ram clk +gate