Llama2-Chinese项目:8-TRL资料整理
TRL(Transformer Reinforcement Learning)是一个使用强化学习来训练Transformer语言模型和Stable Diffusion模型的Python类库工具集,听上去很抽象,但如果说主要是做SFT(Supervised Fine-tuning)、RM(Reward Modeling)、RLHF(Reinforcement Learning from Human Feedback)和PPO(Proximal Policy Optimization)等的话,肯定就很熟悉了。最重要的是TRL构建于transformers库之上,两者均由Hugging Face公司开发。
一.TRL类库
1.TRL类库介绍
简单理解就是可以通过TRL库做RLHF训练,如下所示:
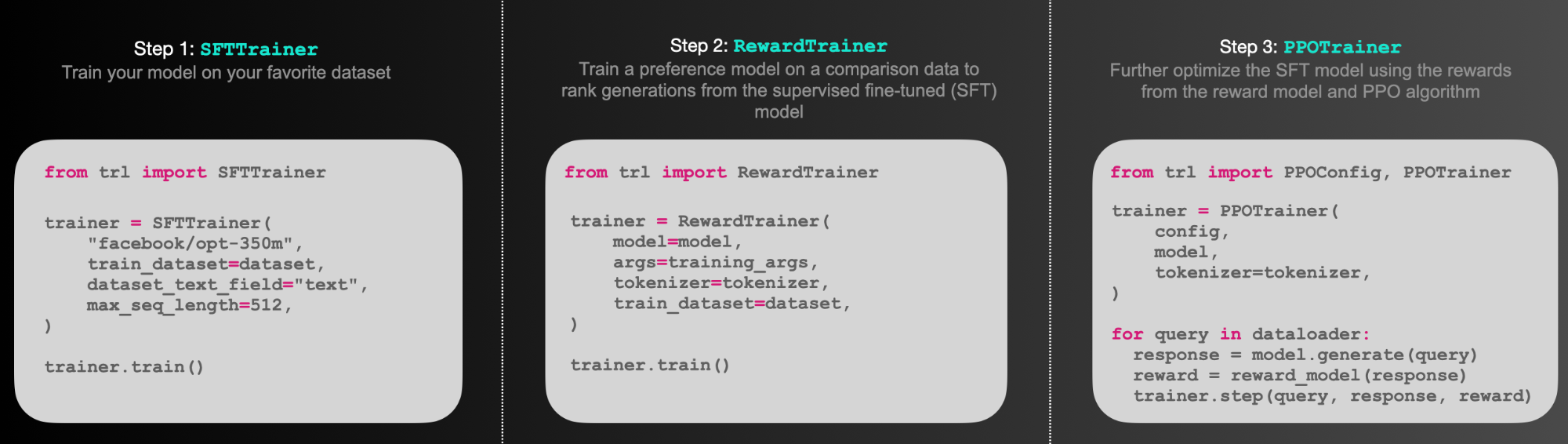
(1)SFTTrainer:是一个轻量级、友好的transformers Trainer包装器,可轻松在自定义数据集上微调语言模型或适配器。
(2)RewardTrainer:是一个轻量级的transformers Trainer包装器,可轻松为人类偏好(奖励建模)微调语言模型。
(3)PPOTrainer:一个PPO训练器,用于语言模型,只需要(query, response, reward)三元组来优化语言模型。
(4)AutoModelForCausalLMWithValueHead & AutoModelForSeq2SeqLMWithValueHead:一个带有额外标量输出的transformer模型,每个token都可以用作强化学习中的值函数。
(5)Examples:使用BERT情感分类器训练GPT2生成积极的电影评论,仅使用适配器的完整RLHF,训练GPT-j以减少毒性,Stack-Llama例子等。
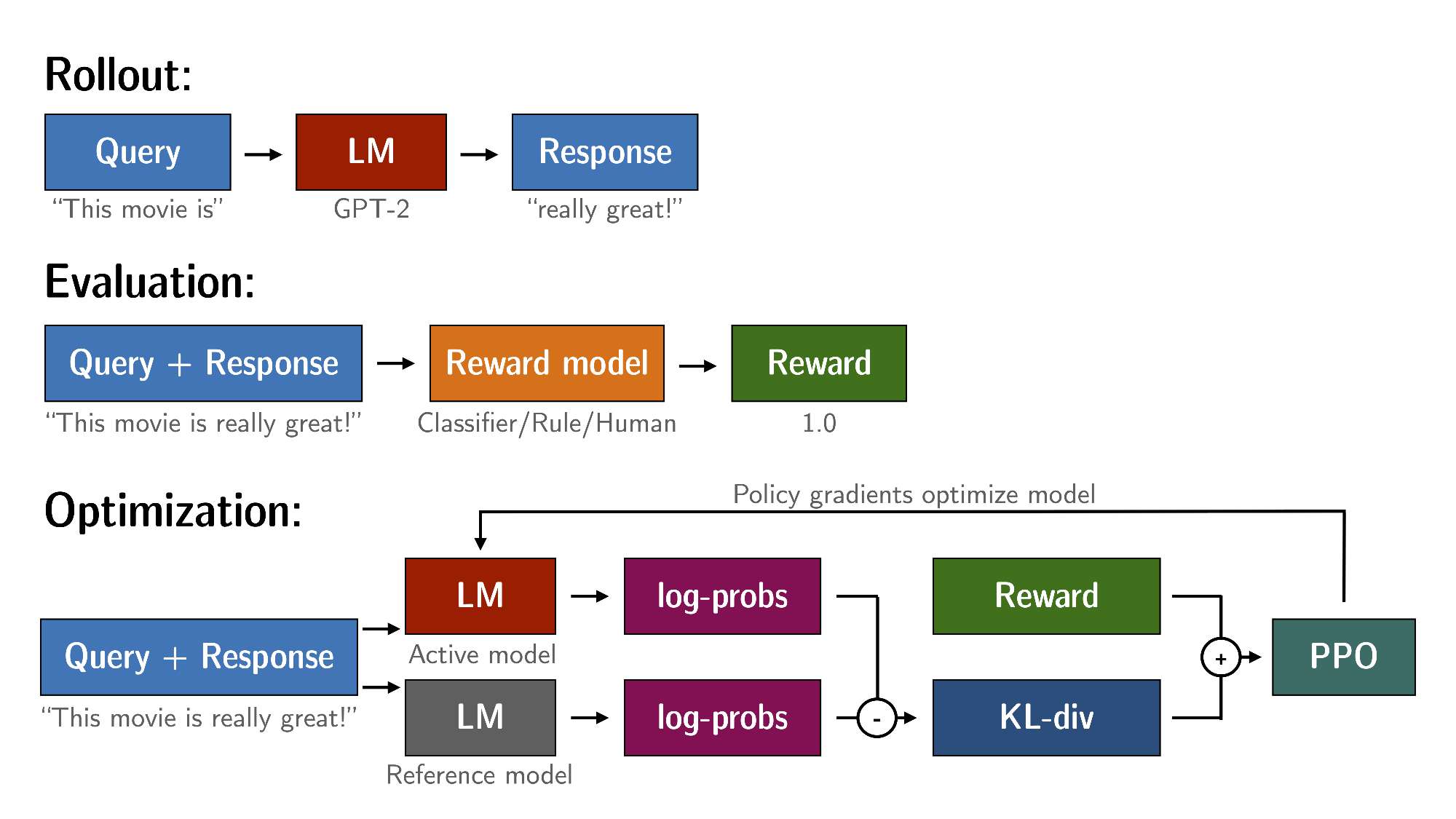
2.PPO工作原理
通过PPO对语言模型进行微调大致包括三个步骤:
(1)Rollout:语言模型根据query生成response或continuation,query可以是一个句子的开头。
(2)Evaluation:使用函数、模型、人类反馈或它们的某些组合对查询和响应进行评估。重要的是,此过程应为每个query/response对生成一个标量值。
(3)Optimization:这是最复杂的部分。在优化步骤中,query/response对用于计算序列中token的对数概率。这是使用经过训练的模型和Reference model完成的,Reference model通常是微调前的预训练模型。两个输出之间的KL散度用作额外的奖励信号,以确保生成的response不会偏离Reference model太远。然后使用PPO训练Active model。
二.TRL安装和使用方式
1.TRL安装
# 直接安装包
pip install trl
# 从源码安装
git clone https://github.com/huggingface/trl.git
cd trl/
pip install .
2.SFTTrainer使用方式
SFTTrainer是围绕transformer Trainer的轻量级封装,可以轻松微调自定义数据集上的语言模型或适配器。如下所示:
# 导入Python包
from datasets import load_dataset
from trl import SFTTrainer
# 加载imdb数据集
dataset = load_dataset("imdb", split="train")
# 得到trainer
trainer = SFTTrainer(
"facebook/opt-350m",
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=512,
)
# 开始训练
trainer.train()
3.RewardTrainer使用方式
RewardTrainer是围绕transformers Trainer的封装,可以轻松在自定义偏好数据集上微调奖励模型或适配器。如下所示:
# 导入Python包
from transformers import AutoModelForSequenceClassification, AutoTokenizer
from trl import RewardTrainer
# 加载模型和数据集,数据集需要为指定格式
model = AutoModelForSequenceClassification.from_pretrained("gpt2", num_labels=1)
tokenizer = AutoTokenizer.from_pretrained("gpt2")
...
# 得到trainer
trainer = RewardTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
)
# 开始训练
trainer.train()
4.PPOTrainer使用方式
query通过语言模型输出一个response,然后对其进行评估。评估可以人类反馈,也可以是另一个模型的输出。如下所示:
# 导入Python包
import torch
from transformers import AutoTokenizer
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead, create_reference_model
from trl.core import respond_to_batch
# 首先加载模型,然后创建参考模型
model = AutoModelForCausalLMWithValueHead.from_pretrained('gpt2')
model_ref = create_reference_model(model)
tokenizer = AutoTokenizer.from_pretrained('gpt2')
# 初始化ppo配置对象
ppo_config = PPOConfig(
batch_size=1,
)
# 编码一个query
query_txt = "This morning I went to the "
query_tensor = tokenizer.encode(query_txt, return_tensors="pt")
# 得到模型response
response_tensor = respond_to_batch(model, query_tensor)
# 创建一个ppo trainer
ppo_trainer = PPOTrainer(ppo_config, model, model_ref, tokenizer)
# 为response定义一个reward(人类反馈或模型输出奖励)
reward = [torch.tensor(1.0)]
# 使用ppo训练一步模型
train_stats = ppo_trainer.step([query_tensor[0]], [response_tensor[0]], reward)
参考文献:
[1]https://github.com/huggingface/trl
[2]https://huggingface.co/docs/trl/v0.7.1/en/index
Llama2-Chinese项目:8-TRL资料整理的更多相关文章
- iOS 开发学习资料整理(持续更新)
“如果说我看得比别人远些,那是因为我站在巨人们的肩膀上.” ---牛顿 iOS及Mac开源项目和学习资料[超级全面] http://www.kancloud.cn/digest/ios-mac ...
- zz 圣诞丨太阁所有的免费算法视频资料整理
首发于 太阁实验室 关注专栏 写文章 圣诞丨太阁所有的免费算法视频资料整理 Ray Cao· 12 小时前 感谢大家一年以来对太阁实验室的支持,我们特地整理了在过去一年中我们所有的原创算法 ...
- 【转】iOS超全开源框架、项目和学习资料汇总
iOS超全开源框架.项目和学习资料汇总(1)UI篇iOS超全开源框架.项目和学习资料汇总(2)动画篇iOS超全开源框架.项目和学习资料汇总(3)网络和Model篇iOS超全开源框架.项目和学习资料汇总 ...
- H.264的一些资料整理
本文转载自 http://blog.csdn.net/ljzcom/article/details/7258978, 如有需要,请移步查看. Technorati 标签: H.264 资料整理 --- ...
- Java 学习资料整理
Java 学习资料整理 Java 精品学习视频教程下载汇总 Java视频教程 孙鑫Java无难事 (全12CD) Java视频教程 即学即会java 上海交大 Java初级编程基础 共25讲下载 av ...
- word2vec剖析,资料整理备存
声明:word2vec剖析,资料整理备存,以下资料均为转载,膜拜大神,仅作学术交流之用. word2vec是google最新发布的深度学习工具,它利用神经网络将单词映射到低维连续实数空间,又称为单词嵌 ...
- F4NNIU 的 Docker 学习资料整理
F4NNIU 的 Docker 学习资料整理 Docker 介绍 以下来自 Wikipedia Docker是一个开放源代码软件项目,让应用程序部署在软件货柜下的工作可以自动化进行,借此在Linux操 ...
- Burpsuite 资料整理
Burpsuite 资料整理, 整到一起比较方便.大家有更多关于Burpsuite的Tip请一起增量.谢谢! 插件 序号 名称 功能 参考文档 1 Turbo intruder 并发 https:// ...
- iOS 学习资料整理
iOS学习资料整理 https://github.com/NunchakusHuang/trip-to-iOS 很好的个人博客 http://www.cnblogs.com/ygm900/ 开发笔记 ...
- 转:基于IOS上MDM技术相关资料整理及汇总
一.MDM相关知识: MDM (Mobile Device Management ),即移动设备管理.在21世纪的今天,数据是企业宝贵的资产,安全问题更是重中之重,在移动互联网时代,员工个人的设备接入 ...
随机推荐
- 【Unity3D】Shader Graph简介
1 Shader Graph 简介 Shader Graph 是 Unity 官方在 2018 年推出的 Shader 制作插件,是图形化的 Shader 制作工具,类似于 Blender 中的 ...
- 用xshell连接vmware虚拟机
主要是为了方便写命令,我的vmware不管怎样都没办法粘贴命令,写建表sql更是折磨. 开启虚拟机用ifconfig查看内网ip地址. 然后在用户身份验证填用户名和密码. 连接成功. 这样就可以开多个 ...
- 数据结构与算法 | 深搜(DFS)与广搜(BFS)
深搜(DFS)与广搜(BFS) 在查找二叉树某个节点时,如果把二叉树所有节点理理解为解空间,待找到那个节点理解为满足特定条件的解,对此解答可以抽象描述为: 在解空间中搜索满足特定条件的解,这其实就是搜 ...
- Mach-O Inside: 命令行工具集 otool objdump od 与 dwarfdump
1 otool otool 命令行工具用来查看 Mach-O 文件的结构. 1.1 查看文件头 otool -h -v 文件路径 -h选项表明查看 Mach-O 文件头. -v 选项表明将展示的内容进 ...
- 如何去掉桌面快捷方式左下角的小箭头(Win11)
在对系统重命名之后,在快捷方式的左下角莫名的出现了小图标 如果想要去掉这个小图标 (1)首先在桌面上创建一个txt文件 (2)打开后输入指令 reg add "HKEY_LOCAL_MACH ...
- HTTP工具类文件request.js的完善和优化
request.js 在现代前端项目中通常被称为一个HTTP请求工具或HTTP工具类文件.它的主要作用是对项目中用到的HTTP请求进行统一的配置和处理. 应用示例: // 查询用户列表 export ...
- golang在win10安装、环境配置 和 goland开发工具golang配置 及Terminal的git配置
前言 本人在使用goland软件开发go时,对于goland软件配置网上资料少,为了方便自己遗忘.也为了希望和我一样的小白能够更好的使用,所以就写下这篇博客,废话不多说开搞. 一.查看自己电脑系统版本 ...
- Excel 使用 VLOOKUP 函数匹配特定列
前言 工作有一项内容,是根据新的表格的某一列的内容一对一匹配,生成一列新的表格.这就用到了 Excel 的 VLOOKUP 函数. 函数使用 函数体: =VLOOKUP(lookup_value,ta ...
- DFT与ATE IP TEST
IP的DFT设计测试与ATE IP TEST是一个设计,测试活动吗? 不是. 这两个设计对于前端工农村很容易搞混,认为是同一个人负责,同一个活动.实际情不是. DFT主要空DSC控制器对IP进行扫描, ...
- [ABC309G] Ban Permutation
Problem Statement Find the number, modulo $998244353$, of permutations $P=(P_1,P_2,\dots,P_N)$ of $( ...