像 Google SRE 一样 OnCall
在 Google SRE 的著作《Google运维解密》(原作名:Site Reliability Engineering: How Google Runs Production Systems)中,Google SRE 的关键成员们几乎不惜用了三个章节的篇幅描述了在 Google 他们是如何 OnCall 的。
Google SRE 实践中,有一个广为人知的理念:减少琐事,用软件工程的方式解决运维问题。具体到实际操作层面,Google SRE 设定了一个重要的、公开的目标:保持每个SRE的工作时间中琐事比例低于50%,SRE 至少花 50% 的时间在工程项目上,以减少未来的琐事或为服务增加新功能。
Google SRE 团队认为,琐事过多,会产生以下不利的后果:
- 职业停滞:如果花在工程项目上的时间太少,你的职业发展会变慢,甚至停滞。Google确实会奖励做那些脏活累活的人,但是仅仅是该工作是不可避免,并有巨大的正面影响的时候才会这样做。没有人可以通过不停地做脏活累活满足自己的职业发展。
- 士气低落:每个人对自己可以承担的琐事限度有所不同,但是一定有个限度。过多的琐事会导致过度劳累、厌倦和不满。
- 造成误解:我们努力确保每个SRE以及每个与SRE一起工作的人都理解SRE是一个工程组织。如果个人或者团队过度参与琐事,会破坏这种角色,造成误解。
- 进展缓慢:琐事过多会导致团队生产力下降。如果SRE团队忙于为手工操作和导出数据救火,新功能的发布就会变慢。
- 开创先河:如果SRE过于愿意承担琐事,研发同事就更倾向于加入更多的琐事,有时候甚至将本来应该由研发团队承担的运维工作转给SRE来承担。其他团队也会开始指望SRE接受这样的工作,这显然是不好的。
- 促进摩擦产生:即使你个人对琐事没有怨言,你现在的或未来的队友可能会很不开心。如果团队中引入了太多的琐事,其实就是在鼓励团队里最好的工程师开始寻找其他地方提供的更有价值的工作。
- 违反承诺:那些为了项目工程工作而新入职的员工,以及转入SRE的老员工会有被欺骗的感觉,这非常不利于公司的士气。
根据统计数据显示,琐事的第一大来源是中断性工作,另一个主要来源是OnCall。前者大多为与服务相关的非紧急事务,后者则为紧急的应急事务。在 Google,一个 SRE 团队至少要保持6~8人的规模,才能保证因 OnCall 轮值产生的琐事低于30%。
管中窥豹,Google SRE 的工作方式,不是谁都有条件学,也不是谁都可以学的来的。需要从文化 机制 工具层面综合考虑,以国内的运维现状来看,这是有一些实际困难和阻力的。
文化
首先,在文化层面,Google SRE 倡导以人为本,关注人的发展,着眼长期结果。在国内加班文化盛行,996甚嚣尘上。具体到 IT 运维领域,表现为:
技术人员工作和生活很难平衡,上班与下班没有明确界限,最终变成了只有值班,没有轮换,7x24小时响应。工作规划以短期目标驱动,缺乏长期主义,导致技术人员每天忙于“战术性”的工作,琐事缠身,而无暇通过软件工程的手段一劳永逸的解决长期问题,久而久之堆积为技术债务。35岁IT打工人困境较为普遍。归根结底,是人的发展,没有得到足够的重视,由于不断的有大量新人进入到 IT 行业,使得很多企业选择了不断“汰换人”而非“发展人”这样的路线,自然也就无从谈起“费力减少琐事”了。
机制
其次,在机制层面,Google SRE 明确执行“琐事不能超过50%”的机制,确保一个独立的 SRE team 最少保持6人的规模,以支撑轮换 OnCall,同时给予工作时间之外的 OnCall 工作以额外的补贴。
在国内这个操作难度很大,国内的大多数企业,SRE人数 vs 研发总人数的比例普遍接近1:100,要保持6人的SRE team,几乎是不可能的。
工具
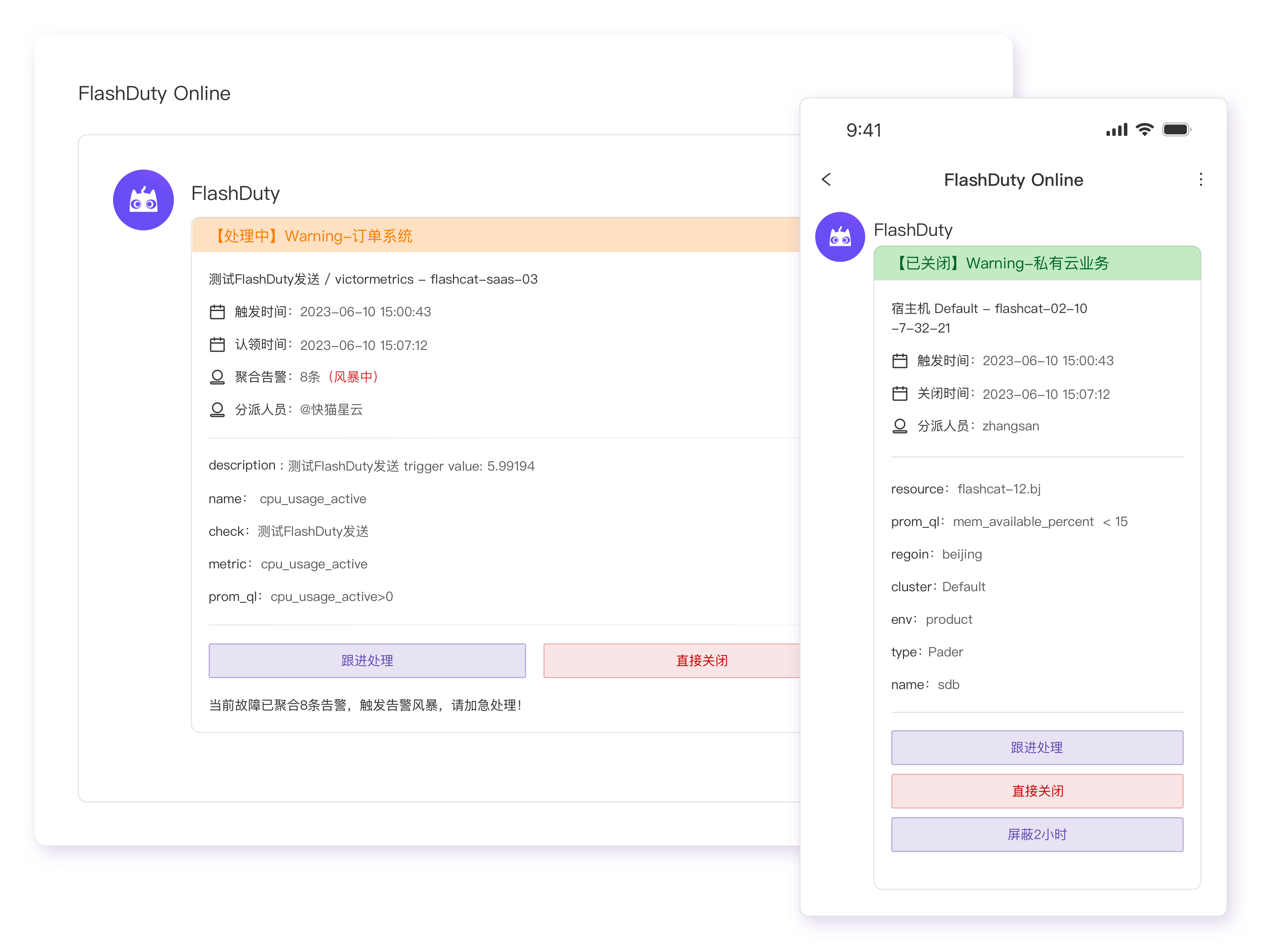
最后,在工具层面,Google SRE 内部使用的 OnCall 工具为 Outalator。在 Outalator 中,SRE 们在一个集中的平台上,管理着告警的全生命周期过程,具体的来讲,功能包括:
- 告警聚合:将多个告警信息“聚合”成一个单独的故障,SRE 以“故障”为维度来跟进和处理,大大降低了告警的发送量,避免重复性工作,降低了告警中的噪音,提高处理效率,以及减少工作失误。
- 加标签:给不同的故障,加上标签,用来额外描述故障的信息,方便SRE 以标签为维度来筛选、统计、分析,提高告警处理效率。
- 提供告警数据分析能力:从不同的维度,比如团队、个人、服务、机房等不同的维度,分析告警的数量变化趋势、告警的响应效率、处理效率,以便SRE能从宏观层面分析OnCall工作的不足之处,并有针对性的加以改进。
- 一键生成报告和公告:Outalator 中对一线SRE更有用的功能是可以选择一系列故障,将它们的标题、标签和“重要的”记录信息用邮件格式发送给下一个OnCall工程师(也可以CC其他人或邮件列表)。这样可以很容易地进行交接工作。Outalator同时支持一种“报告模式”,为周期性的生产服务评审(大部分团队每周进行一次)提供帮助。
Outalator 大概长下面这样: 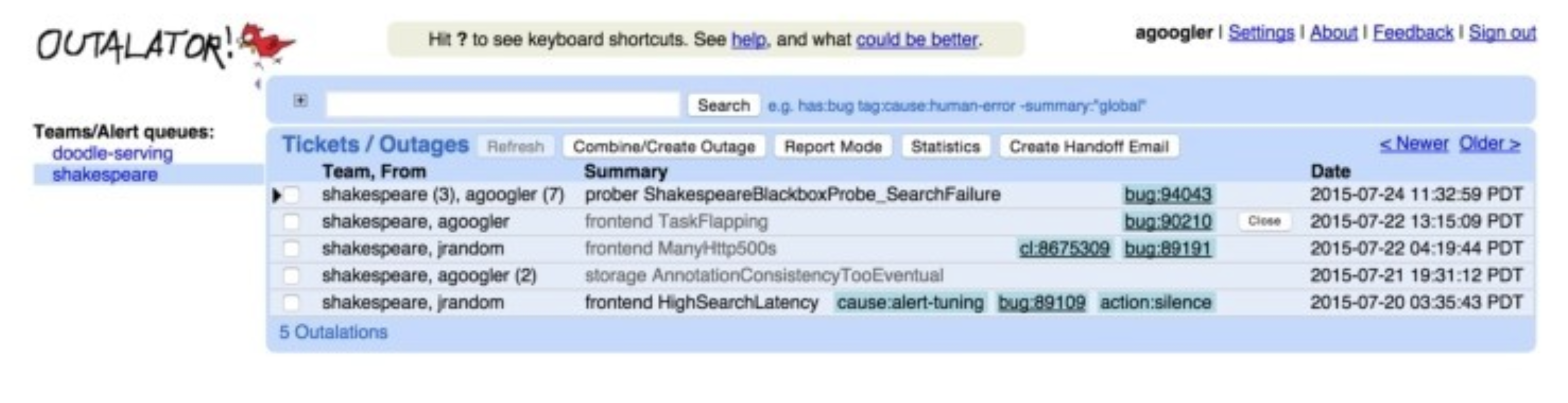
总结来讲,通过使用专业的 OnCall 工具,可以有效的解决日常工作中运维和研发人员面临的以下困扰:
- 技术团队每天接收到大量的告警。
- 很多告警长时间无响应,长期无人问津。
- 告警与告警之间缺乏关联性,处理效率低下。
- 告警处理缺乏协同,处理过程不透明,信息难以共享,知识难以沉淀。
- 很多告警并未准确反应实际情况,无谓的消耗技术团队精力。
- 客户/用户往往先于技术团队发现故障,客户满意度持续走低。
- 无法量化的衡量应急响应的现状和效率,无法制定出改进和优化路线。
我们可以像 Google SRE 一样 OnCall 吗?
通过以上的分析,坏消息是文化和机制层面,学起来有阻力,好消息是工具层面,Google 的 OnCall 工具可选项还不少。
我们熟知的 Kubernetes 是 Google 内部容器编排工具 Borg 的开源实现,Prometheus 是 Google 内部监控工具 Borgmon 的开源版本。那么 Google 内部的 OnCall 工具 Outalator 有没有相关的产品呢?今天就给大家带来市面上两款典型的 OnCall 工具的介绍和分析。
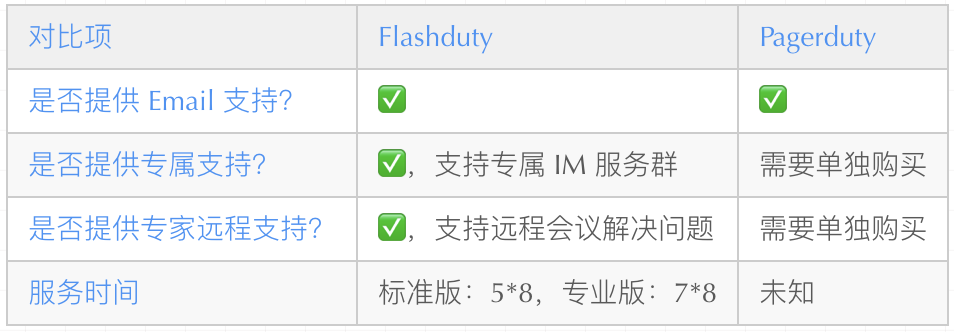
- PagerDuty 是全球范围内OnCall产品的领导者,可以仅以21$/人/月的价格,就可以用起来。
- FlashDuty 是开源监控工具夜莺背后的开发者团队推出的 OnCall 产品,相比 PagerDuty 对国内的各种监控工具、IM工具适配性更好,产品体验也更简洁。
没有度量就没有改进,在实际工作中,运维负责人表面看到的是告警太多、团队成员疲于奔命,但苦于看不清告警处理的工作量,没法规划协调补充人力,更严重的是看不清优化告警的方向,导致情况持续恶化,最终团队散了,故障频发。一个好的 OnCall 工具,需要透出下面 5 个关键的度量指标:
- 降噪比:即告警的压缩比,通过算法、规则将众多相关的告警聚合后,再通知到值班人员。告警聚合能有效降低告警风暴,减少值班人员的工作量,提高信息处理的效率(
该指标越高越好)。 - 响应比:被认领的告警占所有告警的比例。在告警管理领域,需要响应或者认领的告警,才是有用的告警,因此通过统计和观察“响应比“,能整体的评估告警是否足够有效和有用,并持续的推动提升告警”响应比“(
该指标越高越好)。 - 告警总量:一段时间窗口内产生的告警数量。过高的告警总量,意味着值班的压力越大,对技术团队注意力的干扰越多,潜在的意味着告警的噪音可能也过大,因此过多的告警,会让整个系统处于不可运维的状态,应该该尽力的降低告警总量,譬如采用基于SLO的告警,就可以答复降低该指标(
该指标越低越好)。 - MTTA(平均响应或认领用时):从告警发生到值班人员响应或者认领的时间间隔。越快的 MTTA,标志着越高的告警处理效率,潜在的代表着越高的服务稳定性。通过MTTA我们可以有效的度量团队的工作压力,以便决策合适的资源投入,确保团队始终处于可持续发展的状态(
该指标合适就好)。 - MTTR(平均恢复或解决用时):从告警发生到问题解决的时间间隔。越快的 MTTR,往往意味着团队拥有更先进的观测技术、更强大的基础设施平台、更熟练的工作技能、以及对业务系统有更深入的理解(
该指标越快越好)。
下面笔者将从产品、价格与服务三个维度,来探讨国内外这两款 OnCall 产品 Flashduty 和 Pagerduty 的差异。
产品
集成能力
故障管理系统作为流程处置中心,存储了全部的告警和故障数据。此类系统应该支持强大的数据接入和外呼能力,以便和其他各类系统或工作流集成,加速响应、增强协同。

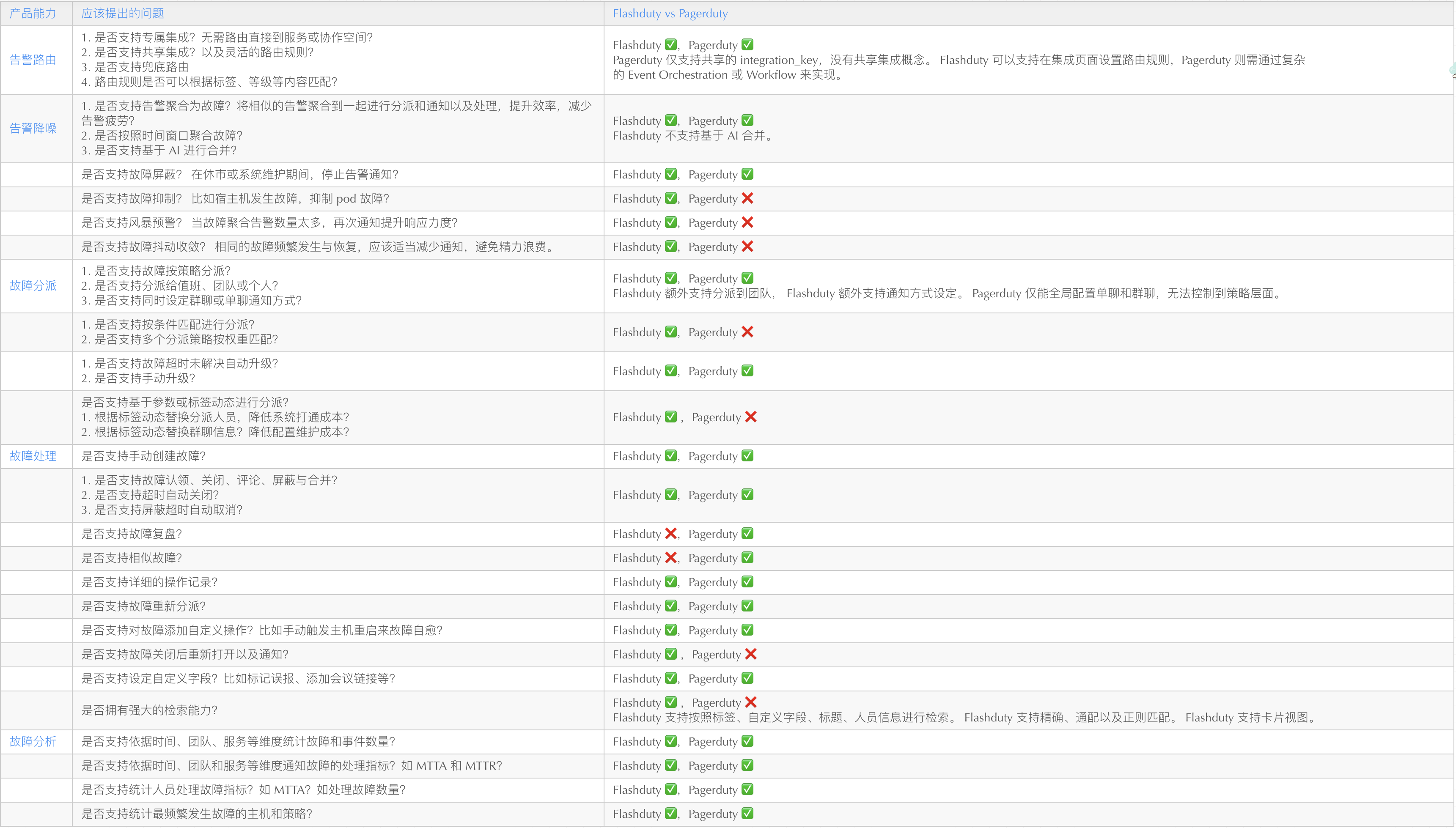
故障处置
故障处置为系统的核心操作,该维度下主要考察产品功能的丰富度和灵活性。
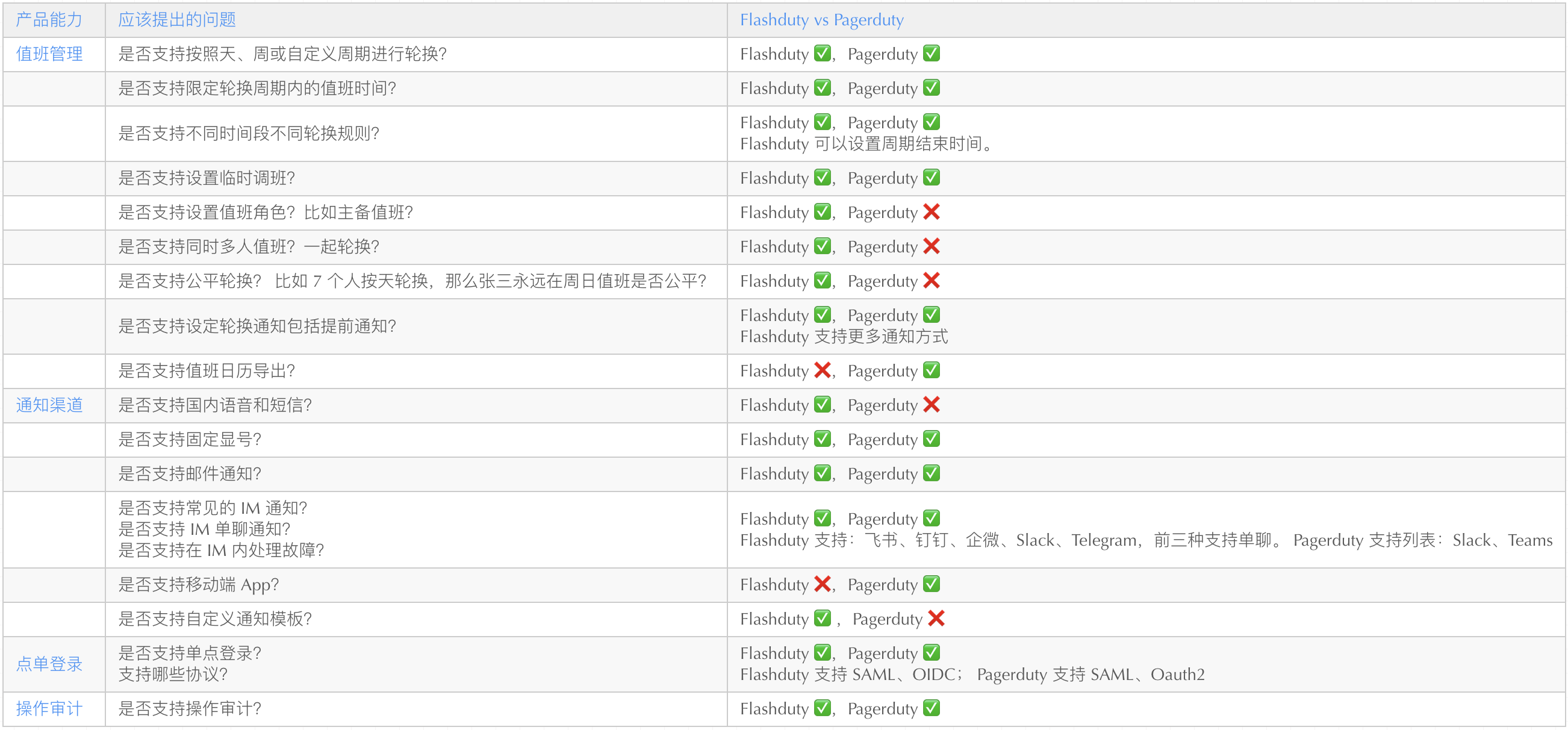
平台能力
平台能力主要在成员管理、值班响应和通知能力层面,系统要具备基本的审计和单点登录功能。通知渠道越丰富越好,本地化支持越多越好,值班管理最好能满足组织内的特殊场景。
价格
PagerDuty 和 FlashDuty都提供多种订阅方式。选择的时候在满足自身需求的情况下,哪一款更具性价比,确保实际使用不超预算,计价方式的简单性都很重要。
- Pagerduty 价格页:https://www.pagerduty.com/pricing/incident-response/
- Flashduty 价格页:https://flashcat.cloud/flashduty/price/

服务
服务维度主要考察供应商服务响应的方式、专业性、及时效性。
注册
现在点击专属链接 完成注册,立即开始在 IM 中处理告警。
像 Google SRE 一样 OnCall的更多相关文章
- Google SRE 读书笔记 扒一扒SRE用的那些工具
写在前面 最近花了一点时间阅读了<SRE Goolge运维解密>这本书,对于书的内容大家可以看看豆瓣上的介绍.总体而言,这本书是首次比较系统的披露Google内部SRE运作的一些指导思想. ...
- soft deletion Google SRE 保障数据完整性的手段
w http://www.infoq.com/cn/articles/GoogleSRE-BookChapter26 Google SRE 保障数据完整性的手段 就像我们假设Google 的底层系统经 ...
- SRE SLO On-Call 流程机制 系统稳定性
开篇词|SRE是解决系统稳定性问题的灵丹妙药吗? https://time.geekbang.org/column/article/212686 这两年,近距离地接触了很多不同类型.不同规模的企业 I ...
- 《Google SRE》读后感
注:这是去年国庆时的一篇读书笔记,最近线上故障频繁,重新读了下这篇读书笔记,觉得<Google SRE>非常棒,遂从简书再搬家到博客园,希望大家受益.我的简书地址:daoqidelv 国庆 ...
- Google SRE
SRE_百度百科 https://baike.baidu.com/item/SRE/1141123 我们离Google SRE还有多远? - 简书https://www.jianshu.com/p/6 ...
- 如何做监控?Google SRE 解密
监控值班室: @隔壁老王头 SQL执行耗时时间过长,达到了报警阈值[5000ms] 隔壁老王头: @监控值班室 少量报警请忽略,批量关注即可. 监控值班室: @隔壁老王头 订单号[88886666]状 ...
- [置顶]
来自 Google 的高可用架构理念与实践
转自: https://mp.weixin.qq.com/s?__biz=MzAwMDU1MTE1OQ==&mid=402738153&idx=1&sn=af5e76aad ...
- 谷歌的SRE和开发是如何合作的
本文是一篇比较有价值的.介绍SRE的文章.国内的所谓SRE职责其实并不明确,大部分其实还是干普通运维的事.但文中介绍的谷歌的运作方式起点还是相对比较高的,无论对SRE.对开发,甚至对公司都有很高的要求 ...
- Uber SRE 实践:运维大型分布式系统的一些心得
本文是 Uber 的工程师 Gergely Orosz 的文章,原文地址在:https://blog.pragmaticengineer.com/operating-a-high-scale-dist ...
- SRE之道:创造软件系统来维护系统运行
引言:本文作者Ben Treynor Sloss,Google 运维团队的高级副总裁,SRE 名称的发明者,在这里提供了他对SRE 的定义. 本文选自<SRE:Google运维解密>. ...
随机推荐
- 3 种发布策略,解决 K8s 中快速交付应用的难题
作者 | 郝树伟(流生)阿里云高级研发工程师 前言 软件技术更新换代很快,但我们追求的目标是一直不变的,那就是在安全稳定的前提下,增加应用的部署频率,缩短产品功能的迭代周期,这样的好处就是企业可以在更 ...
- EventBridge 集成云服务实践
简介:本篇文章主要向大家分享了通过 EventBridge 如何集成云产品事件源,如何集成云产品事件目标以及通过事件流如何集成消息产品. 作者:李凯(凯易) EvenBridge 集成概述 Even ...
- 3月2日,阿里云开源 PolarDB 企业级架构将迎来重磅发布
简介:2022年3月2日,开源 PolarDB 企业级架构将迎来重磅发布!本次发布会将首次公开开源 PolarDB 的总体结构设计和企业级特性,对 PolarDB for PostgreSQL 的存储 ...
- 配置审计(Config)变配报警设置
简介: 本文作者[紫极zj],本篇将主要介绍通过配置审计的自定义规则等服务,对负载均衡进行预警行为的相关介绍. 前言 配置审计(Config)将您分散在各地域的资源整合为全局资源列表,可便捷地搜索全局 ...
- Dataphin核心功能(四):安全——基于数据权限分类分级和敏感数据保护,保障企业数据安全
简介:<数据安全法>的发布,对企业的数据安全使用和管理提出了更高的要求.Dataphin提供基于数据分级分类和数据脱敏的敏感数据识别和保护能力,助力企业建立合规的数据安全体系,保障企业数据 ...
- dotnet 修复在 Linux 上使用 SkiaSharp 提示找不到 libSkiaSharp 库
本文告诉大家如何简单修复在 Linux 上使用 SkiaSharp 提示找不到 libSkiaSharp 库 我的应用在 Windows 上跑的好好的,放在 Linux 上一运行就炸掉了,异常内容如下 ...
- Golang 爬虫02
验证邮箱 目标站点: https://movie.douban.com/top250
- jeecg-boot中导出excel冲突问题
jeecg-boot自带的库是autopoi,如果自定义导出excel引入poi,则需要POI版本要保持一致,否则会出现冲突的情况,导致这2个都用不了的情况. Autopoi底层用的是POI库,poi ...
- postgresql数据库清理
大量update或者delete后 磁盘空间会猛增.原理是postgresql并没有真正的删除 只是将删除数据的状态置为已删除,该空间不能记录被从新使用.若是删除的记录位于表的末端,其所占用的空间将会 ...
- C语言:将有顺序的数组进行逆序排序
//设计逆向排序之,数字有序排列,进行逆向排序 主要思想就是头和尾进行交换,前提是------数字必须是排好序的才能进行逆序排 /*假设数组为: 7,8,9,10,11 1 N ...