An expression evaluator
An expression evaluatorTwo weeks ago, I saw an article on codeproject that really nicely solve an old and very known issue. Why it is nice is because it is short, simple, sequential In the mean time, I needed an expression evaluator for a product I am making, and I needed not only to extend the principles of evaluation, but also add a few features. This article describes what I have done in order to write a general purpose expression evaluator, that goes beyond evaluating the 4 primary operations. In fact it can be regarded as a complement to the mentioned article for three reasons :
The principles of expression parsingIt's an old problem because although separating operators from numbers or other tokens is an easy task, the fact that operators are either infix or not, and have algebric prevalence relations between them forces the parser to pay a particular attention to The good news is that, when it comes to usual mathematical expressions, there are only a tiny set of rules. Here they are :
What prevalent means is that if operator a is prevalent over operator b, then a will be performed before b. For instance, multiplications must be performed before additions. Of course, parenthesis help solve prevalence Other than prevalence, we need to build a tree of operations to perform in order to get a result out of the evaluation. Typical trees are binary trees where operands are leaves, and operators are tree nodes. Of course, because operators can chain up each
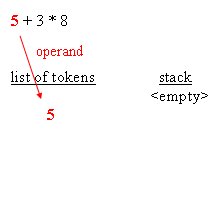
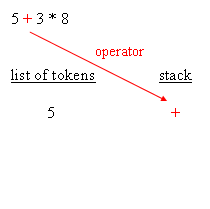
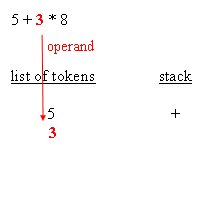
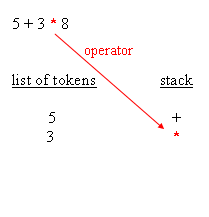
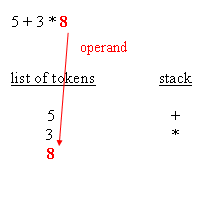
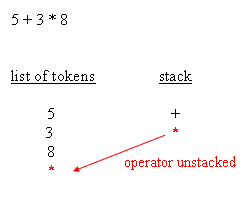
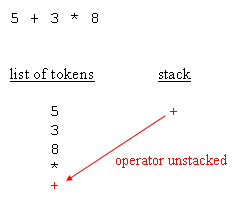
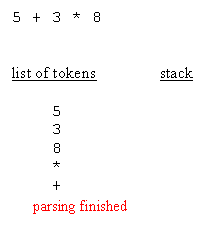
When an evaluation tree is built, evaluation can be done by traversing the nodes from the root down to leaves. Doing the evaluation is a matter of knowing, for each operator, how many arguments are expected, and retrieve them recursively going down the tree. That being said, and that's the main point of RPN (Reverse Polish Notation), an actual tree need not be created. Having an expression in which operators are suffixes of their arguments is enough to have the equivalent of the tree and, as a result, enough For instance, the parsing phase not only distinguishes operator arguments, better known as operands, and operators themselves, the parsing phase also repurposes the expression so that it's in RPN style. For the sample expressions, RPN makes evaluation straight forwardWhy RPN is so useful is that, given such order, it is possible to have a really simple algorithm that reads tokens from left to right, stacks all operands, and then unstacks those whenever an operator is retrieved. After the operation is performed, the resulting
Please note that, during the evaluation process, it is possible to check the expected number of arguments against the amount of arguments available in the operand stack. This leads to typical execution errors, where the user is expected to correct the impaired A typical algorithm for expression parsing is as follows :for each char of the expression This is a general algorithm and it's easy to figure out that a typical implementation remains under 200 lines of source code. The following blocks depict how the parsing works :
If the expression was = 5 * 3 + 8, instead of = 5 + 3 * 8, then when the parser retrieves the + operator, it unstacks the * operator and append it to the list of tokens, before the + operator is stacked. Since parenthesis are of maximum prevalence, they have to be taken into account as such. While open and closed parenthesis behave like any other normal operators, they are paid a special attention. Parenthesis are not appended in the list of tokens. What In the implementation provided in this article, a more granular level of object manipulation was considered. If we limit ourselves to what has been said above, then this expression evaluator is limited to the simple operators. We neither support functions Implementing the list of tokens is a matter of having a base class, wzelement, whose derived classes either hold numbers, strings, operators, or whatever might be required by the client application. As a result, the list of tokens is an array of wzelement typedef enum {_operator, _litteral} elementtype;
wzarray<wzelement*> m_arrelements; // list of tokens
Just to show how this is brought together, below is the declarations for those classes : class wzelement Function supportSupporting functions is a matter of :
Adding support to functions gives a good opportunity to declare operators openly in a table, rather than hardcode them in the parser. Among important flags required by either the parser or the evaluator are :
Below is a sample table showing exactly that : _structoperator operators[] = {
Although the table above (and by the way the source code provided) implements functions that play with numbers, it need not be the case. As a matter of fact, arguments can be strings, imbricated functions or operators, etc. For instance, this source code Last but not least, the argument separator, Variables supportSupporting variables is only a matter of replacing litteral tokens that are not numbers, strings or other litterals with actual numbers or strings or whatever is suited to performing operations. In order to call the evaluator more than once, either the list of tokens must be saved somewhere, and then restored, or variables being replaced with their value need to put back their original name, in the evaluation clean up. In the provided source code, The variable class is declared as follows : class wzvariable : public wzelement Code samples1) sample codeThis sample code demoes the minimum code involved when parsing an expression. Variables not used. #include "util.h" 2) another sample codeThis sample code uses variables. Evaluation is done twice as to show how to iterate the process. #include "util.h" 3) what you need to reuse this codeYou need the following files :
in parser.cpp, the History
Stéphane Rodriguez |
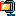

An expression evaluator的更多相关文章
- .NET平台开源项目速览(8)Expression Evaluator表达式计算组件使用
在文章:这些.NET开源项目你知道吗?让.NET开源来得更加猛烈些吧!(第二辑)中,给大家初步介绍了一下Expression Evaluator验证组件.那里只是概述了一下,并没有对其使用和强大功能做 ...
- 给 C# Expression Evaluator 增加中文变量名支持
由于一些特殊的原因,我的Expression里面需要支持中文变量名,但是C# Expression Evaluator会提示错误,在他的HelperMethods.IsAlpha()里面加上这么一段就 ...
- .NET 表达式计算:Expression Evaluator
Expression Evaluator 是一个轻量级的可以在运行时解析C#表达式的开源免费组件.表达式求值应该在很多地方使用,例如一些工资或者成本核算系统,就需要在后台动态配置计算表达式,从而进行计 ...
- (字符串的处理4.7.22)POJ 3337 Expression Evaluator(解析C风格的字符串)
/* * POJ_3337.cpp * * Created on: 2013年10月29日 * Author: Administrator */ #include <iostream> # ...
- 使用 Roslyn 编译器服务
.NET Core和 .NET 4.6中 的C# 6/7 中的编译器Roslyn 一个重要的特性就是"Compiler as a Service",简单的讲,就是就是将编译器开放为 ...
- 【目录】本博客其他.NET开源项目文章目录
本博客所有文章分类的总目录链接:本博客博文总目录-实时更新 1.本博客其他.NET开源项目文章目录 37..NET平台开源项目速览(17)FluentConsole让你的控制台酷起来 36..NET平 ...
- DotNet 资源大全中文版(Awesome最新版)
Awesome系列的.Net资源整理.awesome-dotnet是由quozd发起和维护.内容包括:编译器.压缩.应用框架.应用模板.加密.数据库.反编译.IDE.日志.风格指南等. 算法与数据结构 ...
- Index
我主要在研究.NET/C# 实现 PC IMERP 和 Android IMERP ,目的在解决企业通信中遇到的各类自动化问题 分布式缓存框架: Microsoft Velocity:微软自家分布 ...
- 《.NET开发资源大全》
目录 API 应用框架(Application Frameworks) 应用模板(Application Templates) 人工智能(Artificial Intelligence) 程序集处理( ...
- logback logback.xml常用配置详解 <filter>
<filter>: 过滤器,执行一个过滤器会有返回个枚举值,即DENY,NEUTRAL,ACCEPT其中之一.返回DENY,日志将立即被抛弃不再经过其他过滤器:返回NEUTRAL,有序列表 ...
随机推荐
- 【图文安装教程】在docker中安装ES
在docker中安装ES怎么安装?本文就教大家怎么安装 1.部署单点es 1.1.创建网络 因为我们还需要部署kibana容器,因此需要让es和kibana容器互联.这里先创建一个网络: docker ...
- OCI runtime exec failed: exec failed: container_linux.go:296: starting container process caused "exec: \"bash\": executable file not found in $PATH": unknown
使用如下两个命令均无法进入容器 docker exec -it xxx /bin/bash docker exec -it xxx bash 以为是docker的问题,所以重启 systemctl r ...
- [Udemy] AWS Certified Data Analytics Specialty - 6.Security
S3 加密 SSE-S3 SSE-KMS SSE-C Client Side Encryption SSL/TLS S3 支持http/https 两种协议 KMS KMS最大能加密4KB的数据,再大 ...
- 如何将图片转换为向量?(通过DashScope API调用)
本文介绍如何通过模型服务灵积DashScope将 图片转换为向量 ,并入库至向量检索服务DashVector中进行向量检索. 模型服务灵积DashScope,通过灵活.易用的模型API服务,让各种模态 ...
- Google – Cloud Translation API
前言 通常网站内容翻译,我们都不推荐使用 Google Translate.但网站中一些不那么重要的内容确实可以用 Google Translate.比如 Customer Reviews. 这篇是续 ...
- JavaScript – Object.groupBy & Map.groupBy
前言 group by 是一个很常见的功能,但 JS 却没有 build-in 的方法,一直到 es2024 才有 Object.groupBy (前生是 Array.prototype.group) ...
- Figma 学习笔记 – Layout Grid
前言 我原本以为, 在 Figma 只要用 Auto Layout 就可以打天下. 真的是 too young too simple. 要做一个简单的 7:3 比例, 用 Auto Layout 是做 ...
- 如何基于Java解析国密数字证书
一.说明 随着信息安全的重要性日益凸显,数字证书在各种安全通信场景中扮演着至关重要的角色.国密算法,作为我国自主研发的加密算法标准,其应用也愈发广泛.然而,在Java环境中解析使用国密算法的数字证书时 ...
- Flutter Engage 活动精彩回顾 | 中文字幕视频
在 Flutter Engage 预告之后,无数开发者充满期待并且在社区中积极讨论交流,分享见解.今天,我们正式发布 Flutter 2.0,并在 Flutter Engage 活动 中详细介绍了这一 ...
- 《Vue.js 设计与实现》读书笔记 - 第6章、原始值的响应式方案 & 响应式总结
第6章.原始值的响应式方案 6.1 引入 ref 的概念 既然原始值无法使用 Proxy 我们就只能把原始值包裹起来. function ref(val) { const wrapper = { va ...