Flink学习(五) Flink 的核心语义和架构模型
Flink 的核心语义和架构模型
我们在讲解 Flink 程序的编程模型之前,先来了解一下 Flink 中的 Streams、State、Time 等核心概念和基础语义,以及 Flink 提供的不同层级的 API。
Flink 核心概念
Streams(流),流分为有界流和无界流。有界流指的是有固定大小,不随时间增加而增长的数据,比如我们保存在 Hive 中的一个表;而无界流指的是数据随着时间增加而增长,计算状态持续进行,比如我们消费 Kafka 中的消息,消息持续不断,那么计算也会持续进行不会结束。
State(状态),所谓的状态指的是在进行流式计算过程中的信息。一般用作容错恢复和持久化,流式计算在本质上是增量计算,也就是说需要不断地查询过去的状态。状态在 Flink 中有十分重要的作用,例如为了确保 Exactly-once 语义需要将数据写到状态中;此外,状态的持久化存储也是集群出现 Fail-over 的情况下自动重启的前提条件。
Time(时间),Flink 支持了 Event time、Ingestion time、Processing time 等多种时间语义,时间是我们在进行 Flink 程序开发时判断业务状态是否滞后和延迟的重要依据。
API:Flink 自身提供了不同级别的抽象来支持我们开发流式或者批量处理程序,由上而下可分为 SQL / Table API、DataStream API、ProcessFunction 三层,开发者可以根据需要选择不同层级的 API 进行开发。
Flink 编程模型和流式处理
Flink 程序的基础构建模块是流(Streams)和转换(Transformations),每一个数据流起始于一个或多个 Source,并终止于一个或多个 Sink。数据流类似于有向无环图(DAG)。
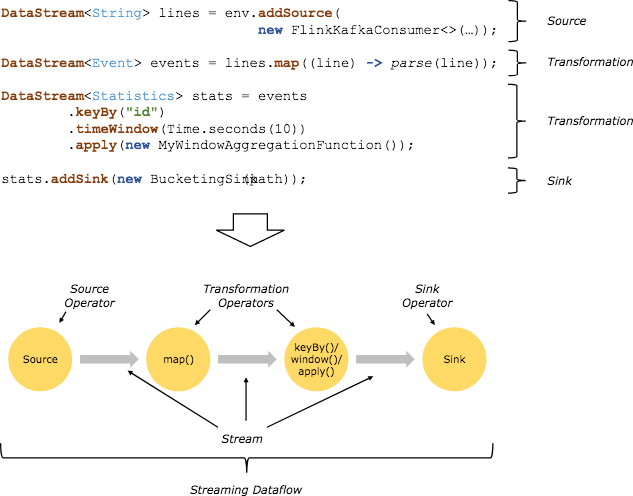
在分布式运行环境中,Flink 提出了算子链的概念,Flink 将多个算子放在一个任务中,由同一个线程执行,减少线程之间的切换、消息的序列化/反序列化、数据在缓冲区的交换,减少延迟的同时提高整体的吞吐量。
官网中给出的例子如下,在并行环境下,Flink 将多个 operator 的子任务链接在一起形成了一个task,每个 task 都有一个独立的线程执行。
Flink 集群模型和角色
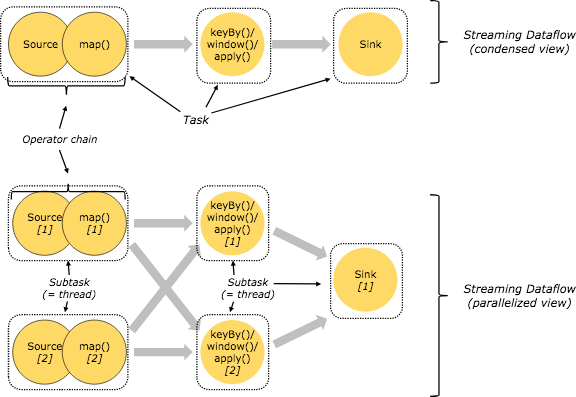
在实际生产中,Flink 都是以集群在运行,在运行的过程中包含了两类进程。
JobManager:它扮演的是集群管理者的角色,负责调度任务、协调 checkpoints、协调故障恢复、收集 Job 的状态信息,并管理 Flink 集群中的从节点 TaskManager。
TaskManager:实际负责执行计算的 Worker,在其上执行 Flink Job 的一组 Task;TaskManager 还是所在节点的管理员,它负责把该节点上的服务器信息比如内存、磁盘、任务运行情况等向 JobManager 汇报。
Client:用户在提交编写好的 Flink 工程时,会先创建一个客户端再进行提交,这个客户端就是 Client,Client 会根据用户传入的参数选择使用 yarn per job 模式、stand-alone 模式还是 yarn-session 模式将 Flink 程序提交到集群。
Flink 资源和资源组
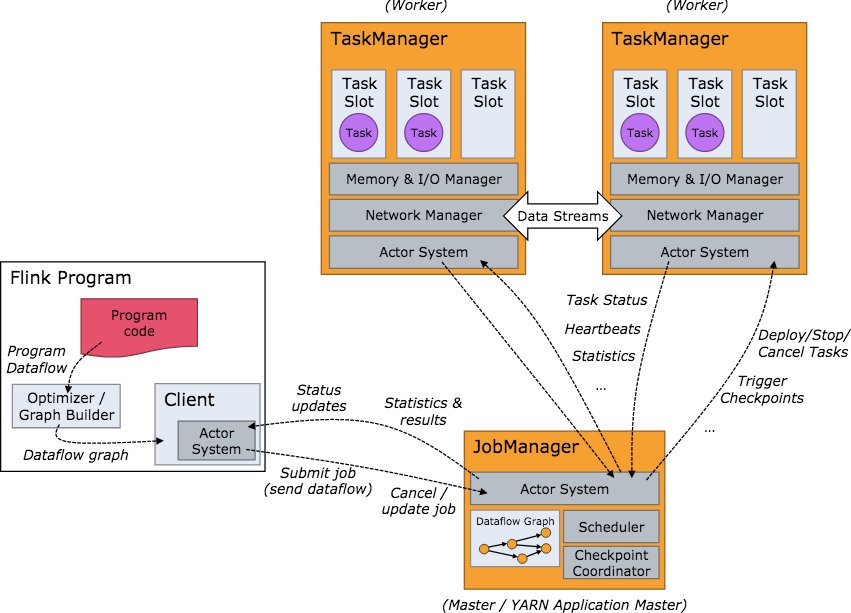
在 Flink 集群中,一个 TaskManger 就是一个 JVM 进程,并且会用独立的线程来执行 task,为了控制一个 TaskManger 能接受多少个 task,Flink 提出了 Task Slot 的概念。
我们可以简单的把 Task Slot 理解为 TaskManager 的计算资源子集。假如一个 TaskManager 拥有 3 个 slot,那么该 TaskManager 的计算资源会被平均分为 3 份,不同的 task 在不同的 slot 中执行,避免资源竞争。但是需要注意的是,slot 仅仅用来做内存的隔离,对 CPU 不起作用。那么运行在同一个 JVM 的 task 可以共享 TCP 连接,减少网络传输,在一定程度上提高了程序的运行效率,降低了资源消耗。
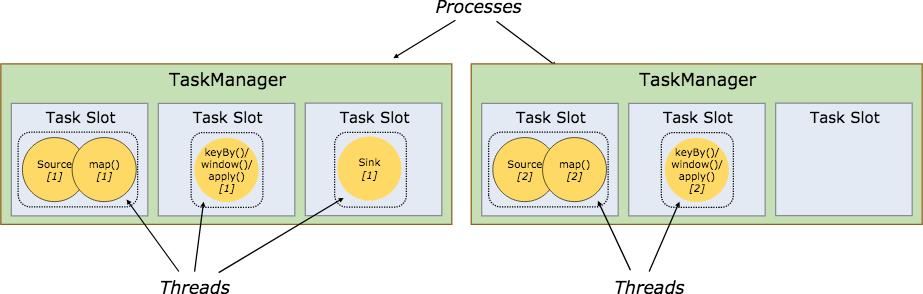
与此同时,Flink 还允许将不能形成算子链的两个操作,比如下图中的 flatmap 和 key&sink 放在一个 TaskSlot 里执行以达到资源共享的目的。

Flink 的优势及与其他框架的区别
Flink 在诞生之初,就以它独有的特点迅速风靡整个实时计算领域。在此之前,实时计算领域还有 Spark Streaming 和 Storm等框架,那么为什么 Flink 能够脱颖而出?我们将分别在架构、容错、语义处理等方面进行比较。
架构
Stom 的架构是经典的主从模式,并且强依赖 ZooKeeper;Spark Streaming 的架构是基于 Spark 的,它的本质是微批处理,每个 batch 都依赖 Driver,我们可以把 Spark Streaming 理解为时间维度上的 Spark DAG。
Flink 也采用了经典的主从模式,DataFlow Graph 与 Storm 形成的拓扑 Topology 结构类似,Flink 程序启动后,会根据用户的代码处理成 Stream Graph,然后优化成为 JobGraph,JobManager 会根据 JobGraph 生成 ExecutionGraph。ExecutionGraph 才是 Flink 真正能执行的数据结构,当很多个 ExecutionGraph 分布在集群中,就会形成一张网状的拓扑结构。
容错
Storm 在容错方面只支持了 Record 级别的 ACK-FAIL,发送出去的每一条消息,都可以确定是被成功处理或失败处理,因此 Storm 支持至少处理一次语义。
针对以前的 Spark Streaming 任务,我们可以配置对应的 checkpoint,也就是保存点。当任务出现 failover 的时候,会从 checkpoint 重新加载,使得数据不丢失。但是这个过程会导致原来的数据重复处理,不能做到“只处理一次”语义。
Flink 基于两阶段提交实现了精确的一次处理语义。
反压(BackPressure)
反压是分布式处理系统中经常遇到的问题,当消费者速度低于生产者的速度时,则需要消费者将信息反馈给生产者使得生产者的速度能和消费者的速度进行匹配。
Stom 在处理背压问题上简单粗暴,当下游消费者速度跟不上生产者的速度时会直接通知生产者,生产者停止生产数据,这种方式的缺点是不能实现逐级反压,且调优困难。设置的消费速率过小会导致集群吞吐量低下,速率过大会导致消费者 OOM。
Spark Streaming 为了实现反压这个功能,在原来的架构基础上构造了一个“速率控制器”,这个“速率控制器”会根据几个属性,如任务的结束时间、处理时长、处理消息的条数等计算一个速率。在实现控制数据的接收速率中用到了一个经典的算法,即“PID 算法”。
Flink 没有使用任何复杂的机制来解决反压问题,Flink 在数据传输过程中使用了分布式阻塞队列。我们知道在一个阻塞队列中,当队列满了以后发送者会被天然阻塞住,这种阻塞功能相当于给这个阻塞队列提供了反压的能力。
Flink学习(五) Flink 的核心语义和架构模型的更多相关文章
- Flink学习笔记:Flink开发环境搭建
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- flink学习笔记-flink实战
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- SpringBoot学习(五)-->SpringBoot的核心
SpringBoot的核心 1.入口类和@SpringBootApplication Spring Boot的项目一般都会有*Application的入口类,入口类中会有main方法,这是一个标准的J ...
- TCP/IP协议学习(五) 基于C# Socket的C/S模型
TCP/IP协议作为现代网络通讯的基石,内容包罗万象,直接去理解理论是比较困难的:然而通过实践先理解网络通讯的理解,在反过来理解学习TCP/IP协议栈就相对简单很多.C#通过提供的Socket API ...
- Flink学习笔记-新一代Flink计算引擎
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- flink学习笔记-各种Time
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- 《从0到1学习Flink》—— Apache Flink 介绍
前言 Flink 是一种流式计算框架,为什么我会接触到 Flink 呢?因为我目前在负责的是监控平台的告警部分,负责采集到的监控数据会直接往 kafka 里塞,然后告警这边需要从 kafka topi ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
- flink学习总结
flink学习总结 1.Flink是什么? Apache Flink 是一个框架和分布式处理引擎,用于处理无界和有界数据流的状态计算. 2.为什么选择Flink? 1.流数据更加真实的反映了我们的生活 ...
- flink学习笔记-快速生成Flink项目
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
随机推荐
- vue3版本下element-plus和antd-vue选哪个更好一些?
Vue 3 发布后,各家第三方库开始陆续重构并支持 Vue 3 ,国内两大知名框架 Element Plus 和 Ant Design Vue 也相续发布新版支持 Vue 3.到底应该怎么选择呢? E ...
- LocalLLaMA 客户端试验
LM Studio. 可以直接下 hg 模型(实际使用需要自己修改成中国镜像). 有 local server, 符合 openai api 规范. 遗憾的是不支持选择显卡导致无法使用. Farada ...
- Mac下如何添加User到group中
原因: 使用mac的时候需要像linux一样对用户和群组进行操作,但是linux使用的gpasswd和usermod在mac上都不可以使用,mac使用dscl来对group和user操作. 介绍: $ ...
- Qt/C++编写超精美自定义控件(历时9年更新迭代/超202个控件/祖传原创)
一.前言 无论是哪一门开发框架,如果涉及到UI这块,肯定需要用到自定义控件,越复杂功能越多的项目,自定义控件的数量就越多,最开始的时候可能每个自定义控件都针对特定的应用场景,甚至里面带了特定的场景的一 ...
- Qt开发经验小技巧121-130
QLineEdit除了单纯的文本框以外,还可以做很多特殊的处理用途. 限制输入只能输入IP地址. 限制输入范围,强烈推荐使用 QRegExpValidator 正则表达式来处理. //正在表达式限制输 ...
- Pelco-D控制协议
1. 通令参数: 标准速率为4800bps,无校验, 8位数据位,1位停止位 2.命令串格式: 一个PTZ控制命令为7字节的十六进制代码,格式如下: Word 1 Word2 Word 3 Wor ...
- 即时通讯技术文集(第43期):直播技术合集(Part3) [共13篇]
为了更好地分类阅读 52im.net 总计1000多篇精编文章,我将在每周三推送新的一期技术文集,本次是第 43 期. [-1-] 直播系统聊天技术(一):百万在线的美拍直播弹幕系统的实时推送技术实践 ...
- Elasticsearch的分享
一.生活中的数据 搜索引擎是对数据的检索,所以我们先从生活中的数据说起.我们生活中的数据总体分为两种: 结构化数据 非结构化数据 结构化数据: 也称作行数据,是由二维表结构来逻辑表达和实现的数据,严格 ...
- ClickHouse-5操作
ClickHouse操作手册由以下主要部分组成: 安装要求 监控 故障排除 使用建议 更新程序 访问权限 数据备份 配置文件 配额 系统表 服务器配置参数 如何用ClickHouse测试你的硬件 设置 ...
- Eclipse中的快捷键:批量修改指定的变量名、方法名、类名等:alt + shift + r
/* * Eclipse中的快捷键: * 1.补全代码的声明:alt + / * 2.快速修复: ctrl + 1 * 3.批量导包:ctrl + shift + o * 4.使用单行注释:ctrl ...