AnytimeCL:难度加大,支持任意持续学习场景的新方案 | ECCV'24
来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: Anytime Continual Learning for Open Vocabulary Classification

创新点
- 在线训练时,每个批次由新训练样本和类别平衡的存储样本组成。
- 在线学习每个标签的准确性,以有效对原始模型和调整后模型的预测进行加权。
- 损失修改以支持“以上皆非”(不在预设标签内)的预测,这也使开放词汇训练更加稳定。
- 中间层特征压缩,减少训练样本的存储并提高速度,同时对准确性的影响不大。
内容概述
论文提出了针对开放词汇图像分类的任意持续学习(AnytimeCL)方法,旨在突破批量训练和严格模型的限制,要求系统能够在任何时间预测任何一组标签,并在任何时间接收到一个或多个训练样本时高效地更新和改进。
AnytimeCL基于一种动态加权机制,结合了部分微调的模型的预测与原始的模型的预测。当有新训练样本时,用存储的样本填充一个类别平衡的批次更新微调模型最后的Transformer块,然后更新对给定标签的调优和原始模型准确度的估计,最后根据它们对每个标签的预期准确度对调优模型和原始模型的预测进行加权。
此外,论文还提出了一种基于注意力加权的主成分分析(PCA)的训练特征压缩方法,这减少了存储和计算的需求,对模型准确度几乎没有影响。
AnytimeCL
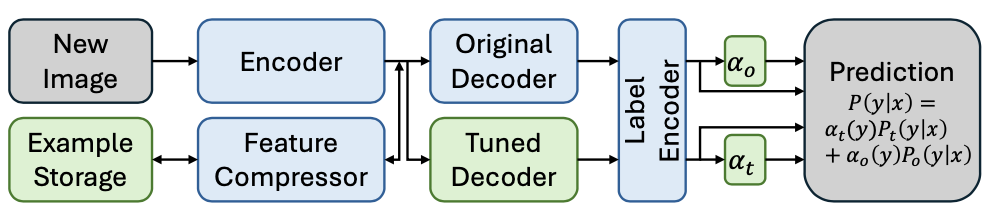
论文旨在通过将微调模型与原始模型相结合来增强开放词汇图像分类器以学习目标任务。调优后的模型使用与原始模型相同的编码器,但包含一个可训练的解码器。
对于一幅图像 \(x\) ,调优模型和原始模型都生成所有候选标签的概率,分别表示为 \(P_t(y|x)\) 和 \(P_o(y|x)\) ,最终概率通过在线类别加权(OCW)进行加权:
\label{eq:our_weighting}
P(y|x) = \alpha_o(y) P_t(y|x) + \alpha_t(y) P_o(y|x),
\end{equation}
\]
在训练过程中,新样本被编码为中间特征(图像块的特征向量加上一个CLS标记),可以选择进行压缩并存储,以便在未来重复使用。
模型
原始模型
原始模型是公开可用的CLIP ViT模型,该模型基于图像嵌入 \(e_{x}\) (CLS标记)与文本嵌入 \(e_{y}\) 的点积,为图像 \(x\) 生成给定一组候选文本标签 \(\mathcal{Y}\) 的标签 \(y\) 的概率:
\label{eq:class_wise_probability}
P_o(y|x) = \frac{\exp(100 \cdot \cos(e_{x}, e_{y}))}{\sum_{y_k\in\mathcal{Y}} \exp(100 \cdot \cos(e_{x}, e_{y_k}))}.
\end{equation}
\]
调优模型
调优模型仅调优最后的图像Transformer块,同时保持标签嵌入固定。这有助于特征与文本模态保持相关,并减少对接收标签的过拟合。
给定一个新样本,构造一个包含该样本的批次以及经过类平衡采样的存储训练样本。此外,使用一种正则化损失来帮助提高性能。如果真实标签不在候选标签中,那么每个候选标签都应该预测一个较低的分数。通过在候选集中添加一个“其他”选项来实现这一点,但由于“其他”没有具体的表现,仅用一个可学习的偏差项来对其建模。因此,训练调优模型的综合损失为:
\label{eq:final_loss}
\mathcal{L}(x, y, \mathcal{Y}) =\mathcal{L}_{\text{ce}}(x,y,\mathcal{Y} \cup \text{other}) + \beta \mathcal{L}_{\text{ce}}(x,\text{other},(\mathcal{Y} \cup \text{other}) \setminus y),
\end{equation}
\]
在线类别加权(OCW)
在更新之前使用每个训练样本,根据调优和原始预测来更新对其标签正确性的可能性估计,从而对给定标签正确的模型分配更高的权重。应用指数滑动平均(EMA)更新方法在线估计它们,符合随时持续学习的目标。假设EMA衰减设置为 \(\eta\) (默认为 \(0.99\) ),当前步骤调优模型的估计准确性为:
c_t(y) = \eta \hat{c}_t(y) + (1 - \eta) \mathbb{1}[y_t(x)=y].
\end{equation}
\]
这里, \(\hat{c}_t(y)\) 是前一步骤中标签 \(y\) 的估计准确性; \(y_t(x)\) 表示调优模型对 \(x\) 的预测标签。由于指数滑动平均依赖于过去的值,将 \(c_t(y)\) 计算为前 \(\lfloor \frac{1}{1-\eta} \rfloor\) 个样本的平均准确性。 \(c_o(y)\) 也是以相同的方式更新的。
在获得 \(c_t(y)\) 和 \(c_o(y)\) 之后,两个模型的权重为:
\label{eq:final_alpha}
\alpha_t(y)= \frac{c_t(y)}{c_t(y) + c_o(y) + \epsilon}, \qquad \alpha_o(y)= 1 - \alpha_t(y).
\end{equation}
\]
这里, \(\epsilon\) 是一个非常小的数(1e-8),用于防止除以零。对于调优模型未见过的标签,设置 \(\alpha_t(y)=0\) ,因此 \(\alpha_o(y)=1\) 。
存储的高效性与隐私性
模型的调优需要存储每个图像或者存储输入到调优部分的特征(或标记)。存储图像存在缺乏隐私和在空间和计算上低效的缺点,因为在训练中需要重新编码。存储特征可以缓解其中一些问题,但仍然使用大量内存或存储空间。
训练良好的网络学习到的数据高效表示往往难以压缩,如果尝试使用在某个数据集上训练的VQ-VAE或PCA(主成分分析)来压缩特征向量,将无法在不大幅损失训练性能的情况下实现任何有意义的压缩。然而,每幅图像中的特征包含许多冗余。因此,计算每幅图像中特征的PCA向量,并将这些向量与每个特征向量的系数一起存储。
此外,并非所有标记在预测中都是同等重要的。因此,可以训练一个逐图像的注意力加权PCA,通过每个标记与CLS标记之间的注意力加权。最后,可以通过存储每个向量及其系数的最小/最大浮点值,并将它们量化为8位或16位无符号整数来进一步压缩。通过以这种方式仅存储五个PCA向量及其系数,可以将50个768维标记( \(7\times 7\) patch 标记 +CLS标记)的存储从153K字节减少到5K字节,同时预测准确度的差异不到1%。
主要实验
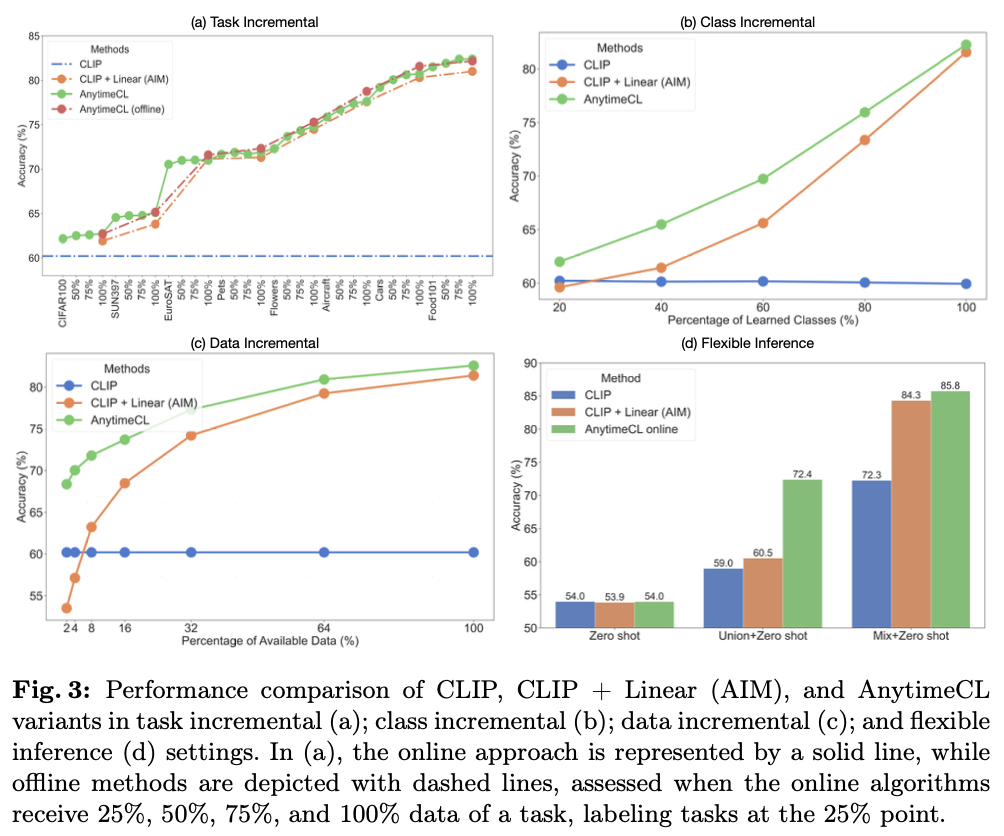
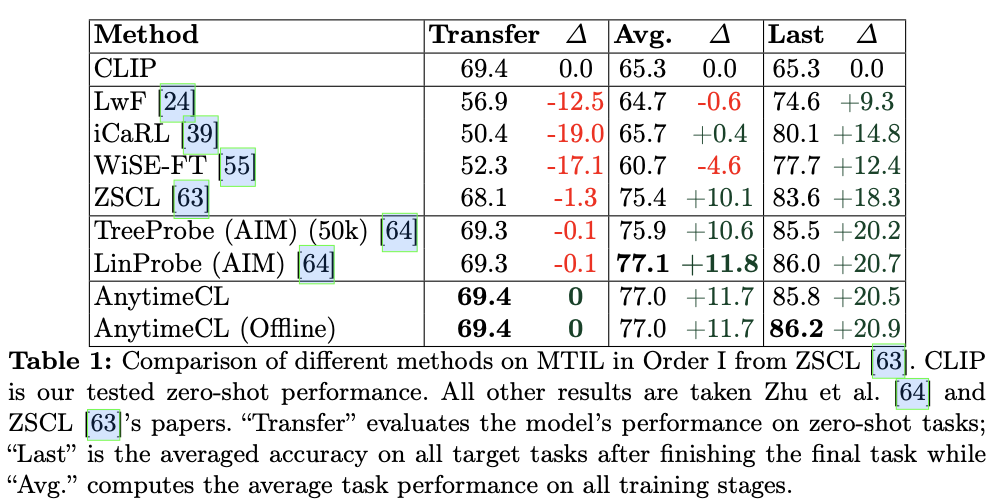
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

AnytimeCL:难度加大,支持任意持续学习场景的新方案 | ECCV'24的更多相关文章
- 【OpenGL(SharpGL)】支持任意相机可平移缩放的轨迹球实现
[OpenGL(SharpGL)]支持任意相机可平移缩放的轨迹球 (本文PDF版在这里.) 在3D程序中,轨迹球(ArcBall)可以让你只用鼠标来控制模型(旋转),便于观察.在这里(http://w ...
- 如何在MQ中实现支持任意延迟的消息?
什么是定时消息和延迟消息? 定时消息:Producer 将消息发送到 MQ 服务端,但并不期望这条消息立马投递,而是推迟到在当前时间点之后的某一个时间投递到 Consumer 进行消费,该消息即定时消 ...
- 【一】ERNIE:飞桨开源开发套件,入门学习,看看行业顶尖持续学习语义理解框架,如何取得世界多个实战的SOTA效果?
参考文章: 深度剖析知识增强语义表示模型--ERNIE_财神Childe的博客-CSDN博客_ernie模型 ERNIE_ERNIE开源开发套件_飞桨 https://github.com/Pad ...
- Devrama Slider - 支持任意 HTML 的内容滑块
Devrama Slider 是一个图片滑块,支持很多特色功能.除了支持图片滑动,其它的 HTML 内容也支持.主要特色:响应式.图片预加载.图片延迟加载.进度条.自定义导航栏和控制按钮等等. 在线演 ...
- 4位或者5位led数码显示,485通信modbus,支持任意小数点写入,工业标准设置,可和plc,dcs,组态完美对接,支持定制修改
MRD-5030具有4位8段数码管,支持通过工业标注协议Modbus(Modbus-RTU)控制显示,支持任意小数点的显示.数据以半双工方式通信.电源端口和通信端口都具有防浪涌,防雷600W保护,能够 ...
- APS高级计划排程系统应该支持的企业应用场景
APS高级计划排程系统应该支持的企业应用场景 面对工业4.0智能制造的挑战,很多企业希望能够引进APS高级计划排程系统,全自动的.快速的制定精细化的生产计划,准确的计算产线/设备上各种产品型号的加工顺 ...
- 论文:利用深度强化学习模型定位新物体(VISUAL SEMANTIC NAVIGATION USING SCENE PRIORS)
这是一篇被ICLR 2019 接收的论文.论文讨论了如何利用场景先验知识 (scene priors)来定位一个新场景(novel scene)中未曾见过的物体(unseen objects).举例来 ...
- 《HTML5秘籍》学习总结--2016年7月24日
前段时间因为工作中看到同事使用了一个type为date的<input>元素,直接就形成了一个日期选择的表单控件,当时觉得很神奇,以为是什么插件,就问了同事是怎么做出来的,同事告诉我这是HT ...
- Web开发者应当开始学习HTML5的新功能
据国外媒体报道,谷歌开发者业务部门高管马克·皮尔格雷姆(Mark Pilgrim)在WWW2010会议上表示,尽管还需要进一步完善,HTML5已经获得大多数平台支持,适合完成大多数任务. 但并非所有人 ...
- 可能是最早的学习Android N新特性的文章
可能是最早的学习Android N新特性的文章 Google在今天放出了Android N开发者预览版.Android N支持Nexus6及以上的设备.5太子Nexus5不再得到更新. Android ...
随机推荐
- python模块xlsxwriter使用
1.安装 pip install XlsxWriter 2.使用 # -*- coding: utf-8 -*- from io import BytesIO import qrcode # impo ...
- c# 复制文件夹内所有文件到另外一个文件夹
/// <summary> /// 开始转移 /// </summary> /// <param name="sender"></para ...
- Make 使用
GNU Make 参考:Make 命令教程 | 阮一峰的网络日志 Makefile 文件的格式 Makefile 文件由一系列 规则(rules)构成.每条 规则 的形式如下. <target& ...
- Go plan9 汇编: 打通应用到底层的任督二脉
原创文章,欢迎转载,转载请注明出处,谢谢. 0. 前言 作为一个严肃的 Gopher,了解汇编是必须的.本汇编系列文章会围绕基本的 Go 程序介绍汇编的基础知识. 1. Go 程序到汇编 首先看一个简 ...
- js玩儿爬虫
前言 提到爬虫可能大多都会想到python,其实爬虫的实现并不限制任何语言. 下面我们就使用js来实现,后端为express,前端为vue3. 实现功能 话不多说,先看结果: 这是项目链接:https ...
- [OI] Kruskal 重构树
算法介绍 Kruskal 重构树用于快速判断节点的连通性. 考虑到,假如两个节点是联通的,则他们之间总会有一条边被选入最小生成树内,因此他们在最小生成树内也是联通的. 也就是说,我们可以通过求最小生成 ...
- Qt构建cmake工程方法总结
由于工作需要,最近打算统一将所有C/C++项目都改成使用cmake编译.传统后台业务问题不大,但是有些牵涉到跨平台的Qt项目还是折腾了一阵.下面对这段时间的收获做一个总结,也希望帮助看到本文的朋友少走 ...
- std::stod:“123.456”-> 123.456
std::stod 是 C++ 标准库中一个用于将字符串转换为 double 类型的函数.它属于 <string> 头文件中的函数,通常用于将包含数字的字符串转换为相应的浮点数值. 函数原 ...
- 在windows下安装Composer(转载)
在windows下安装Composer Composer是 PHP 用来管理依赖(dependency)关系的工具.你可以在自己的项目中声明所依赖的外部工具库(libraries),Composer ...
- USB2.0 DP DM VBUS
在USB 2.0中,设备成功枚举的标志可以通过观察 D+ (dp).D- (dm) 和 VBUS 引脚的电压波形来判断.以下是这些信号在USB 2.0枚举过程中常见的状态: VBUS (5V供电): ...