MySQL 16“order by”是怎么工作的?
假设要查询城市是“杭州”的所有人名字,并且按照姓名排序返回前1000个人的姓名与年龄。那么SQL语句可以写为:
select city,name,age from t where city='杭州' order by name limit 1000;
本文主要想讨论这个语句是如何执行的,以及有什么参数会影响执行的行为。
全字段排序
在上面的查询语句中,为了避免全表扫描,需要在city字段加上索引。用explain命令检查语句的执行情况:

其中,Extra字段的Using filesort表示需要排序,MySQL会给每个线程分配一块内存用于排序,称为sort_buffer。
为了说明该语句的执行过程,先看一下city索引的示意图:
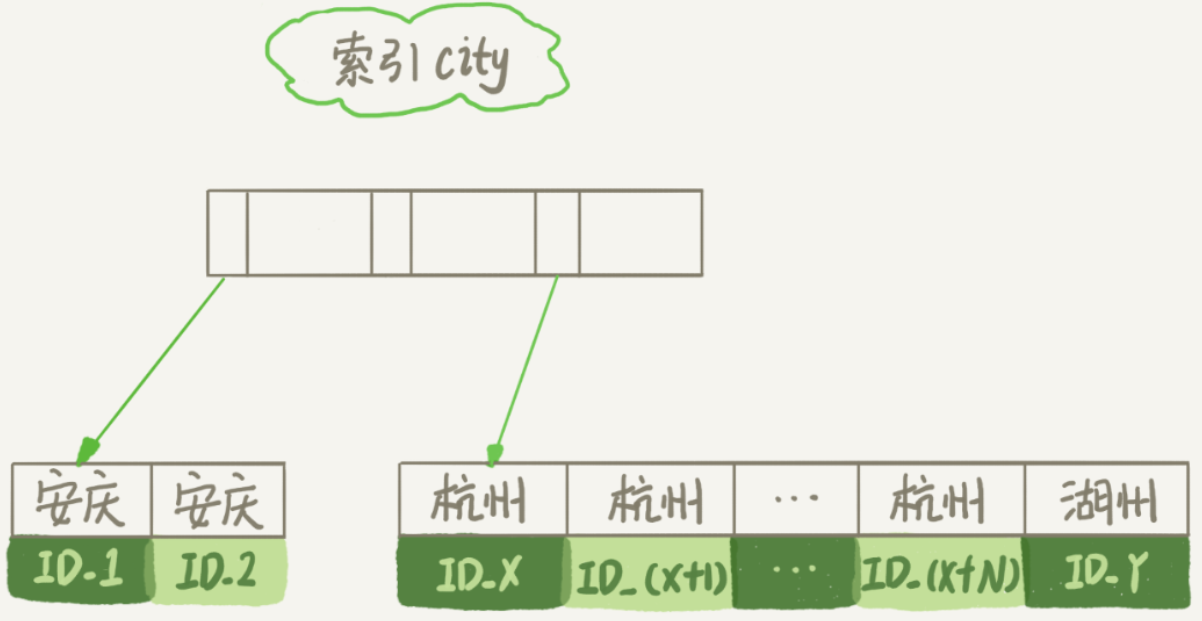
从图中看到,满足city='杭州'条件的行的id是从X到X+N。
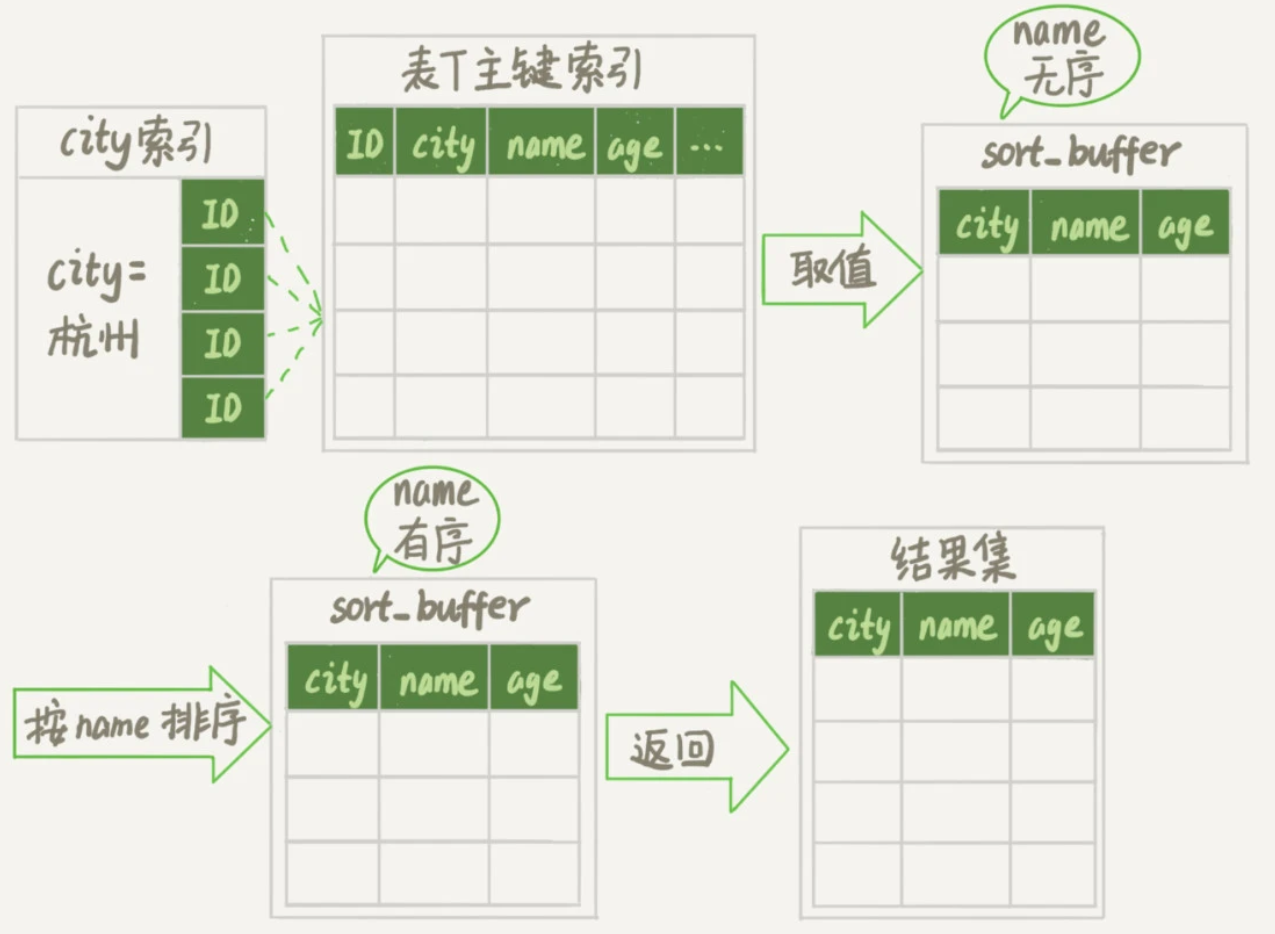
通常情况下,这个语句的执行流程为:
初始化sort_buffer,确定放入name、city、age三个字段;
从city索引中找到第一个满足
city='杭州'条件的主键id为ID_X;到主键id的索引中取出整行,取name、city、age三个字段的值,存入sort_buffer;
从city索引取下一个记录的主键id;
重复上面两个步骤直到city值不满足查询条件,即找到了图中的ID_Y;
对sort_buffer中的数据按照字段name做快速排序;
按照排序结果取前1000行返回给客户端。
我们把这个排序过程称为全字段排序,执行流程示意图如下:
其中,排序过程可能在内存完成,也可能需要使用外部排序,这取决于排序所需的内存和参数sort_buffer_size。sort_buffer_size是MySQL为排序开辟的sort_buffer的大小。如果要排序的数据量小于这个参数,排序就在内存中完成;如果排序数据量太大,内存放不下,则不得不利用磁盘临时文件辅助排序。
对于排序语句是否使用了临时文件,可以通过下面的方法确认:
/* 打开optimizer_trace,只对本线程有效 */
SET optimizer_trace='enabled=on';
/* @a保存Innodb_rows_read的初始值 */
select VARIABLE_VALUE into @a from performance_schema.session_status where variable_name = 'Innodb_rows_read';
/* 执行语句 */
select city, name,age from t where city='杭州' order by name limit 1000;
/* 查看 OPTIMIZER_TRACE 输出 */
SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`\G
/* @b保存Innodb_rows_read的当前值 */
select VARIABLE_VALUE into @b from performance_schema.session_status where variable_name = 'Innodb_rows_read';
/* 计算Innodb_rows_read差值 */
select @b-@a;
该方法通过查看information_schema数据库下的OPTIMIZER_TRACE表查看,用number_of_tmp_files字段查看:
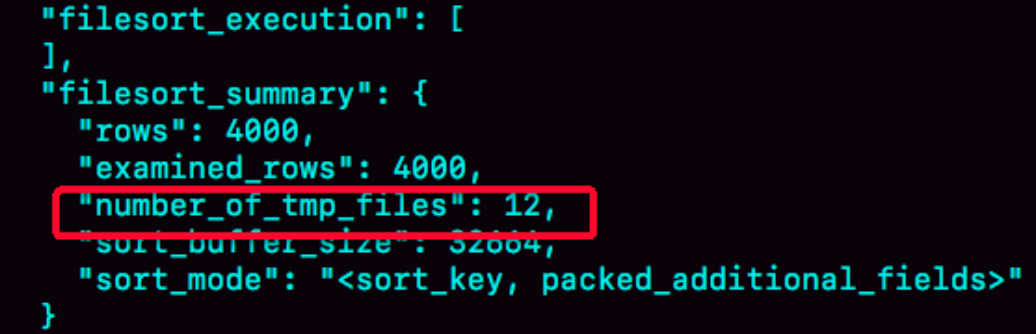
图中结果表示的就是使用了12个临时文件。外部排序一般使用归并排序算法,12个临时文件可以理解为:MySQL将需要排序的数据分成12份,每一份单独排序后放在这些临时文件中,然后把这12个有序文件再合并成一个有序的大文件。
而如果sort_buffer_size超过了需要排序的数据量的大小,number_of_tmp_files就会是0。sort_buffer_size越小,number_of_tmp_files的值会越大。
再解释下上面结果中的其他一些字段:
examined_rows=4000,表示参与排序的行数是4000行;sort_mode里的packed_additional_fields意思是排序过程对字符串做了“紧凑”处理,即使name字段定义为varchar(16),在实际排序过程中是按照实际长度来分配空间。
同时,查询语句select @b-@a的返回结果是4000,表示整个执行过程只扫描了4000 行。
rowid排序
在全字段排序过程中,只对原表的数据读了一遍,剩下的操作都是在sort_buffer和临时文件中执行的。如果查询要返回的字段很多,那么sort_buffer里能存的行数会变得很少,可能会需要很多临时文件,排序的性能变得很差。
这里介绍一个参数:
set max_length_for_sort_data = 16;
这是MySQL中专门控制用于排序的行数据的长度的一个参数。当单行的长度超过这个值,MySQL会认为排序的单行长度太大,需要换一个算法。
假设在t表中,city字段和name为varchar(16),主键id和age字段为int(11)。那么city、name、age三个字段的定义总长度为36,大于了设置的参数值16,此时计算过程会发生改变:
新算法放入sort_buffer的字段只有要排序的列name和主键id,由于排序结果缺少部分字段,不能直接返回,整个执行流程变为:
初始化sort_buffer,确定放入两个字段name和id;
从city索引找到第一个满足
city='杭州'条件的主键id为ID_X;到主键id的索引中取出整行,取name、city、age三个字段的值,存入sort_buffer;
从city索引取下一个记录的主键id;
重复上面两个步骤直到city值不满足查询条件,即找到了图中的ID_Y;
对sort_buffer中的数据按照字段name进行排序;
遍历排序结果,取前1000行并按照id值回到原表取city、name和age三个字段返回给客户端。
我们把这个排序过程称为rowid排序,执行流程示意图如下:
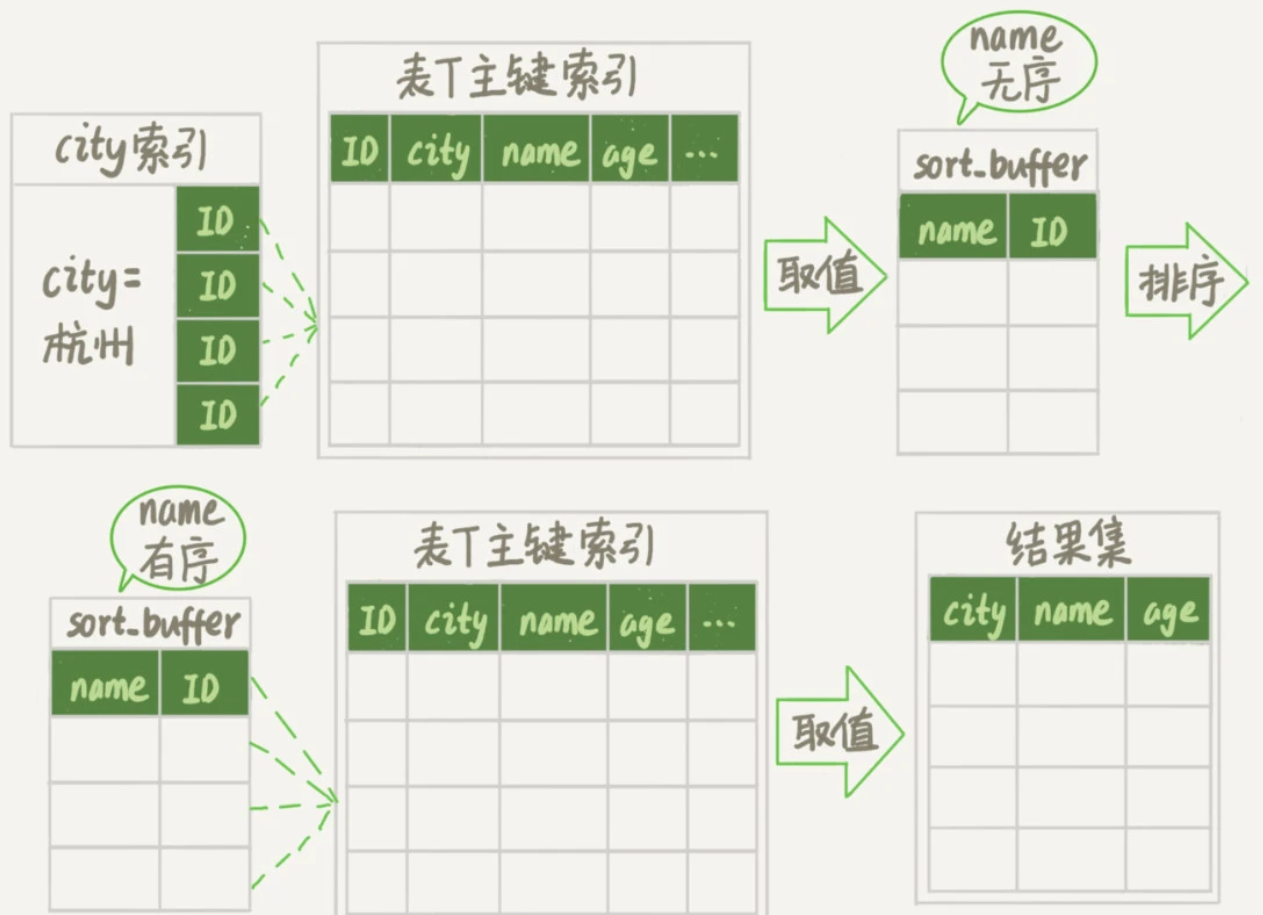
可以发现,rowid排序多访问了一次表的主键索引。
另外,图里的“结果集”是一个逻辑概念,实际上MySQL服务端获得结果后是直接返回给客户端的,而不是还在服务端耗费内存存储结果。
如果对上述过程查看OPTIMIZER_TRACE表,得到的结果如下:
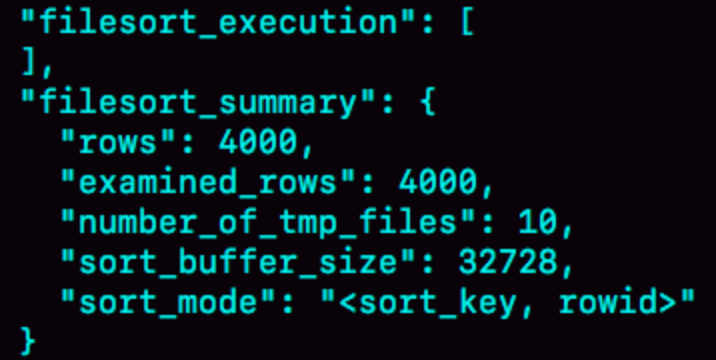
其中:
examined_rows=4000,表示用于排序的数据是4000行;number_of_tmp_files=10,是因为每一行都变小了,需要排序的总数据量就变小,需要的临时文件也减少了;sort_mode里变为rowid,表示参与排序的只有name和id两个字段。
此时,查询语句select @b-@a的返回结果是5000,因为在根据id去原表取值的过程需要多扫描1000行。
全字段排序 VS rowid排序
从上面两种排序方法,可以看出,如果MySQL认为内存足够大,会优先选择全字段排序;如果MySQL认为内存太小,会采用rowid排序。这体现了MySQL的一个设计思想:如果内存够,就多利用内存,尽量减少磁盘访问。
对于InnoDB表,rowid排序回表会增加磁盘读,因此不会被优先选择。
那么是不是所有的order by都需要排序操作呢?不是的,就像在本文的例子中,如果从city索引上取出的行天热按照name递增排序,就可以不用再排序。所以可以对city和name创建联合索引,对应的示意图为:
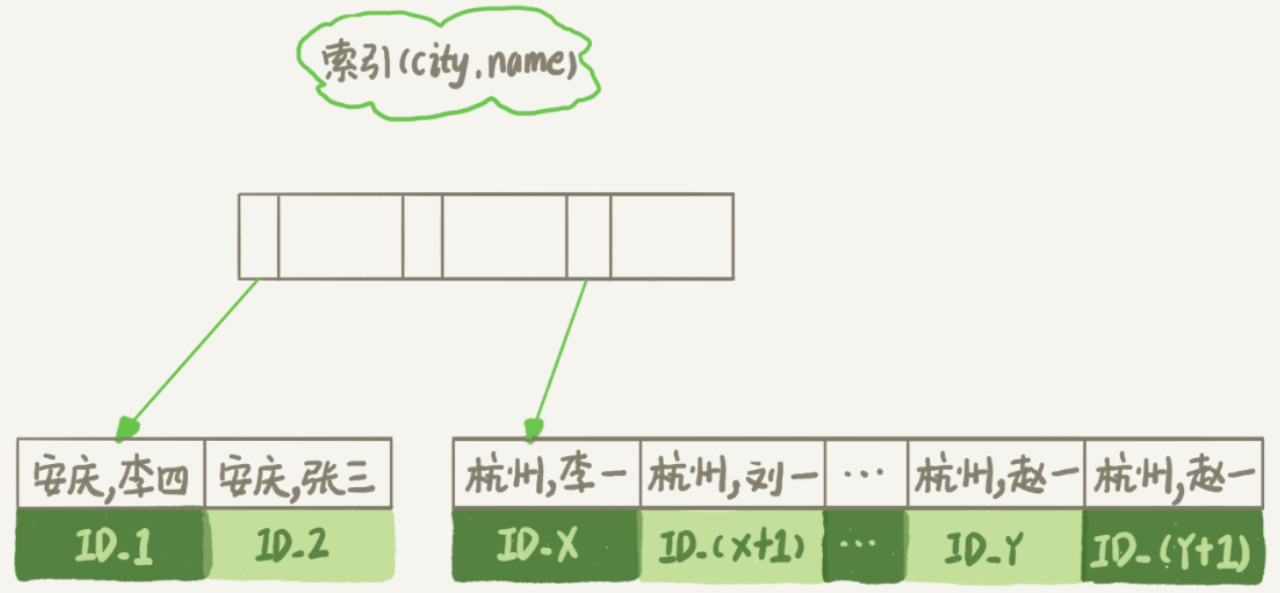
整个查询流程变为:
从索引(city,name)找到第一个满足
city='杭州'的主键id;到主键id索引取出整行,取name、city、age字段的值作为结果集的一部分直接返回;
从索引(city,name)取下一个满足条件的主键id;
重复以上两步,直到查到第1000条记录或不满足条件
city='杭州'。
该过程不需要临时表,也不需要排序,用explain进行验证:

可以看到,Extra里没有Using filesort了。
那么这个语句能否进一步简化呢?是能的,由于最后要返回三个字段,可以考虑覆盖索引,对三个字段建立联合索引。此时整个查询流程变为:
从索引(city,name,age)找到第一个满足
city='杭州'的记录,取name、city、age字段的值作为结果集的一部分直接返回;从索引(city,name,age)取下一个记录,同样取出三个字段并返回;
重复上面一步,直到查到第1000条记录或不满足条件
city='杭州'。
其流程和验证如下:
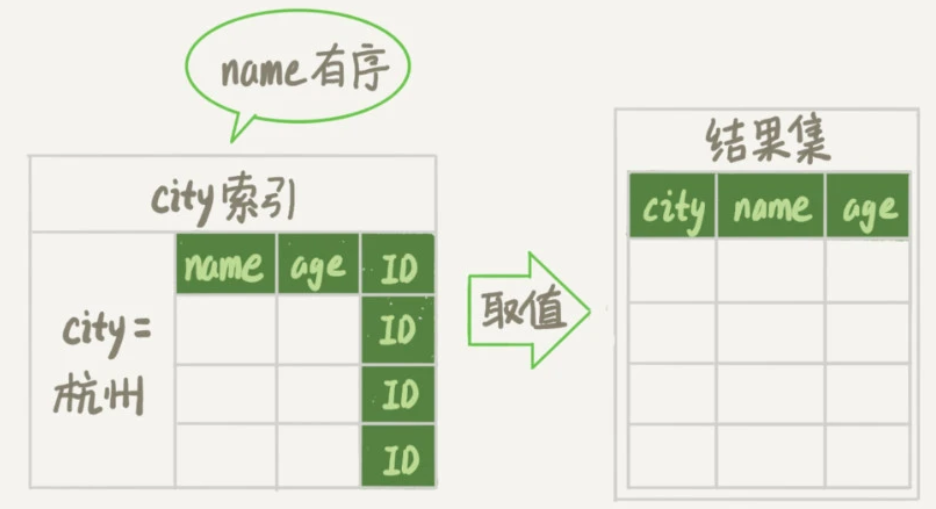

不过并不是说为了查询索引能用上覆盖索引就需要把涉及的字段都建立联合索引,索引有一定代价,这需要权衡。
MySQL 16“order by”是怎么工作的?的更多相关文章
- 16 | “order by”是怎么工作的? 学习记录
<MySQL实战45讲>16 | “order by”是怎么工作的? 学习记录http://naotu.baidu.com/file/0be0e0acdf751def1c0ce66215e ...
- 16 | “order by”是怎么工作的?
在你开发应用的时候,一定会经常碰到需要根据指定的字段排序来显示结果的需求.还是以我们前面举例用过的市民表为例,假设你要查询城市是“杭州”的所有人名字,并且按照姓名排序返回前1000个人的姓名.年龄. ...
- MySQL 笔记整理(16) --“order by”是怎么工作的?
笔记记录自林晓斌(丁奇)老师的<MySQL实战45讲> (本篇内图片均来自丁奇老师的讲解,如有侵权,请联系我删除) 16) --“order by”是怎么工作的? 在林老师的课程中,第15 ...
- order by是怎么工作的?
order by是怎么工作的? 在你开发应用的时候,一定会经常碰到需要根据指定的字段排序来显示结果的需求.还是以我们前面举例用过的市民表为例,假设你要查询城市是"杭州"的所有人名字 ...
- MySQL中order by中关于NULL值的排序问题
MySQL中order by 排序遇到NULL值的问题 MySQL数据库,在order by排序的时候,如果存在NULL值,那么NULL是最小的,ASC正序排序的话,NULL值是在最前面的. 如果我们 ...
- Mysql Order By 字符串排序,mysql 字符串order by
Mysql Order By 字符串排序,mysql 字符串order by ============================== ©Copyright 蕃薯耀 2017年9月30日 http ...
- mysql 中order by 与group by的顺序
mysql 中order by 与group by的顺序 是: select from where group by order by 注意:group by 比order by先执行,order b ...
- MySQL之ORDER BY 详细解析
1 概述 MySQL有两种方式可以实现ORDER BY: 1.通过索引扫描生成有序的结果 2.使用文件排序(filesort) 围绕着这两种排序方式,我们试着理解一下ORDER BY的执行过程以及回答 ...
- mysql 使用order by
1.mysql 使用order by field() 自定义排序 order by field(value,str1,str2,str3,str4......strn) 例如:select * fro ...
- mysql order by是怎么工作的?
假设我们要查询一个市民表中城市=杭州的所有人的名字,并且按照名字排序 CREATE TABLE `t` ( `id` ) NOT NULL, `city` ) NOT NULL, `name` ) N ...
随机推荐
- vue属性/子属性监听watch的几种方法
特殊字符法 特殊字符+deep法 直接deep法 常规法 直接用如下代码示例吧: data(){ return { goBackHeader:'添加排班', scheduleForm:{ schedu ...
- Windows 身份验证协议
本文中的图文内容均取自<域渗透攻防指南>,本人仅对感兴趣的内容做了汇总及附注. 导航 0 前言 1 NTLM 协议 1.1 控制台 1.2 工作组环境 1.3 域环境 1.4 NTLM 协 ...
- 【完结】【一本通提高】2025dsfzB哈希和哈希表做题笔记
2025年dsfz - 上学期B层字符串哈希专题做题笔记 笔记部分请看我的字符串哈希学习笔记 题目编号 标题 估分 正确 提交 Y 2066 Problem A [一本通提高篇哈希和哈希表]乌力波( ...
- base的含义及使用及与this的区别
C#中base关键字的几种用法 - bobob - 博客园 (cnblogs.com) C#构造函数里的base和this的区别 - 傲世狂枫 - 博客园 (cnblogs.com) 我的理解 1.在 ...
- C/S客户端渗透_Proxifier+burpsuite代理客户端http协议数据包+reGeorg构建HTTP隧道代理
C/S客户端渗透_Proxifier+burpsuite代理客户端https协议数据包 一个月没发文章了实在太忙了,不过学习还是不能落下的,最近要做几个CS客户端的站,需要在终端装个北信源的煞笔内网安 ...
- K8s新手系列之Secret资源
概述 官方文档:https://kubernetes.io/zh-cn/docs/concepts/configuration/secret/ 在Kubernetes(k8s)中,Secret是一种用 ...
- 工具:Prisms:漏洞扫描器,棱镜开源版
Prism X 集资产发现.指纹识别.弱密码检测.漏洞验证于一体,采用模块化 YAML 插件策略配置,实现与真实攻击链高度相似的 PoC 验证机制. 跨平台和轻量级设计:支持多种操作系统,易于部署和使 ...
- 操作系统 -- linux初始化(上):GRUB与vmlinuz的结构
本节树立启动的整体流程,重点解读Linux上GRUB是怎样启动,以及内核里的"实权人物"-- vmlinuz内核文件是如何产生和运转的. 全局流程 在机器加电后,BIOS会进行自检 ...
- C# AggreateException
在 C# 中,AggregateException 是一种特殊类型的异常,它允许在多个异步任务中捕获并组合多个异常.当在一个异步任务中同时执行多个子任务时,如果其中任何一个子任务抛出了异常,那么父任务 ...
- WPF学习问题汇集:
WPF中ItemsSource改变,DataGrid中不更新 需要将ItemsSource先赋值为null,而后再赋值为新的值. 例如: gridBeamInfo.ItemsSource = null ...