Towards Accurate Alignment in Real-time 3D Hand-Mesh Reconstruction论文解读
Towards Accurate Alignment in Real-time 3D Hand-Mesh Reconstruction论文解读
这是发表在ICCV2021的一篇文章,主要的工作内容是RGB图像人手重建。

Introduction
单目下的3D人手重建是计算机视觉中一个非常具有挑战性的任务,并且在人机交互,以及增强现实领域有着很高的应用价值;紧接着作者提出如果想要把一个人手重建的方法应用在AR中,要满足以下三个需要:
- 重建要具有实时性;
- 重建出的手的三维形状和姿态要与用户的手匹配(3D -3D alignment);
- 重建出的手投影到图像空间时也要与用户的RGB手部图像对齐(2D -2D alignment)。
同时,论文指出现有的方法也许能够很好的满足前两点,但是第三点却会出现一些misaligned的情况,稍后会提到论文方法针对第三点做的优化。
Related Work
在这之前我先介绍几篇人手重建的相关工作,论文中的一些思想和方法也借鉴了前面的工作.
- 3D Hand Shape and Pose from Images in the Wild CVPR2019[3]
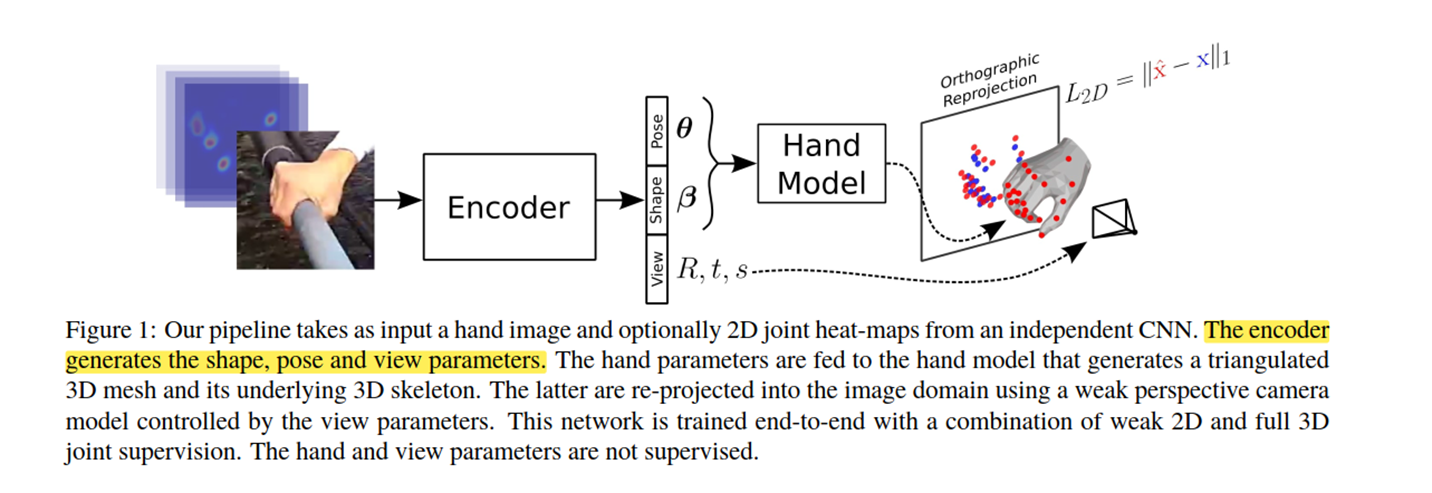
这篇论文使用了在人手的Mesh重建中使用的投影监督,就是把预测人手的关节点投影到像素空间,然后与ground truth 2D hand joint计算一个loss。
额外提一下在人手重建中经常会见到MANO[8]这个词,这是一个手的参数化模型,由pose \(\theta\) 和 shape $\beta $ 两部分组成,这两个参数经过一定的变换,可以得到人手的三维Mesh,使用MANO表示人手参数更少,也不容易出现一些很抽象的手部姿态。
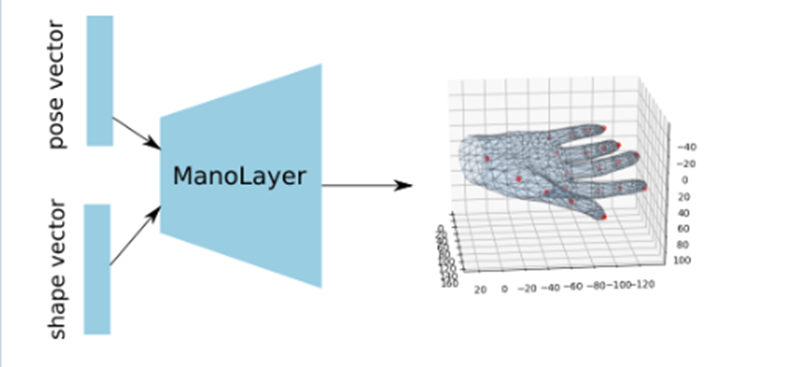
3D Hand Shape and Pose Estimation from a Single RGB Image CVPR2019 [4]
这篇文章引入的手的3D hand pose来指导mesh的重建,注意这里的Pose和位姿估计里的Pose(R,t)不是一个概念,在这里pose指的是关节点的组合,有点类似于Gesture。本篇论文介绍的方法也使用3D hand pose来指导Mesh的重建。
FreiHAND: A Dataset for Markerless Capture of Hand Pose and Shape from Single RGB Images[5]
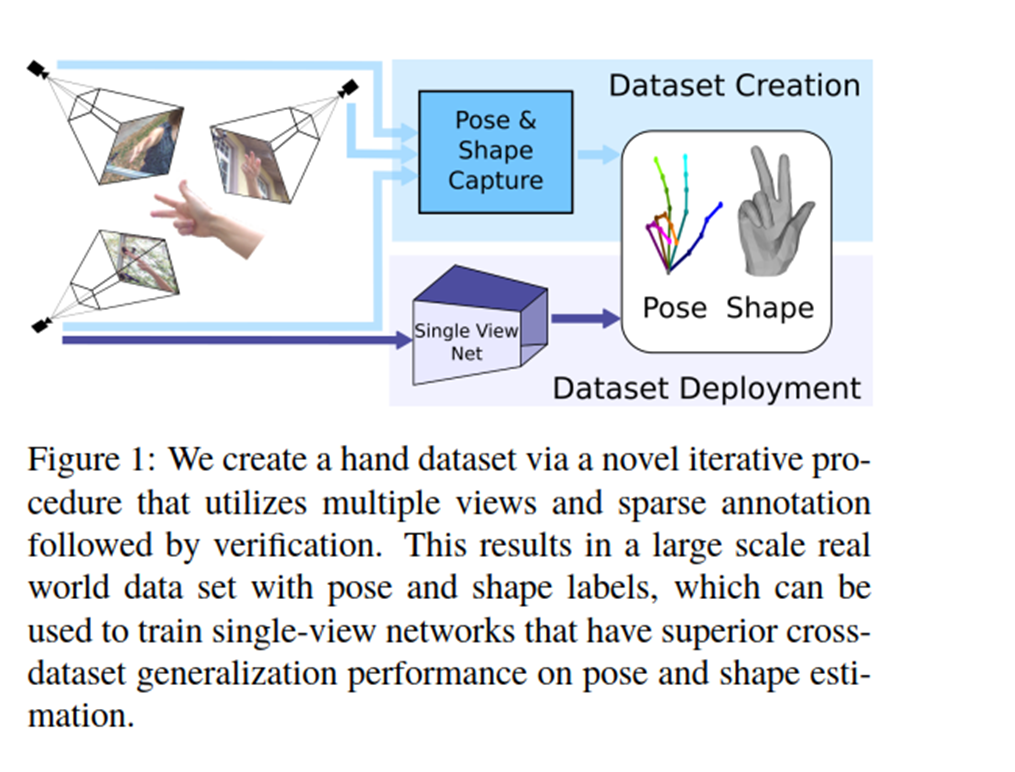
这篇文章的主要贡献是贡献了一个较大规模的数据集FreiHAND,包括人手的RGB图像,Mask,Mesh,Mano参数等信息,也是本篇论文训练时的主力数据集。
SeqHAND: RGB-Sequence-Based 3D Hand Pose and Shape Estimation ECCV2019 [6]
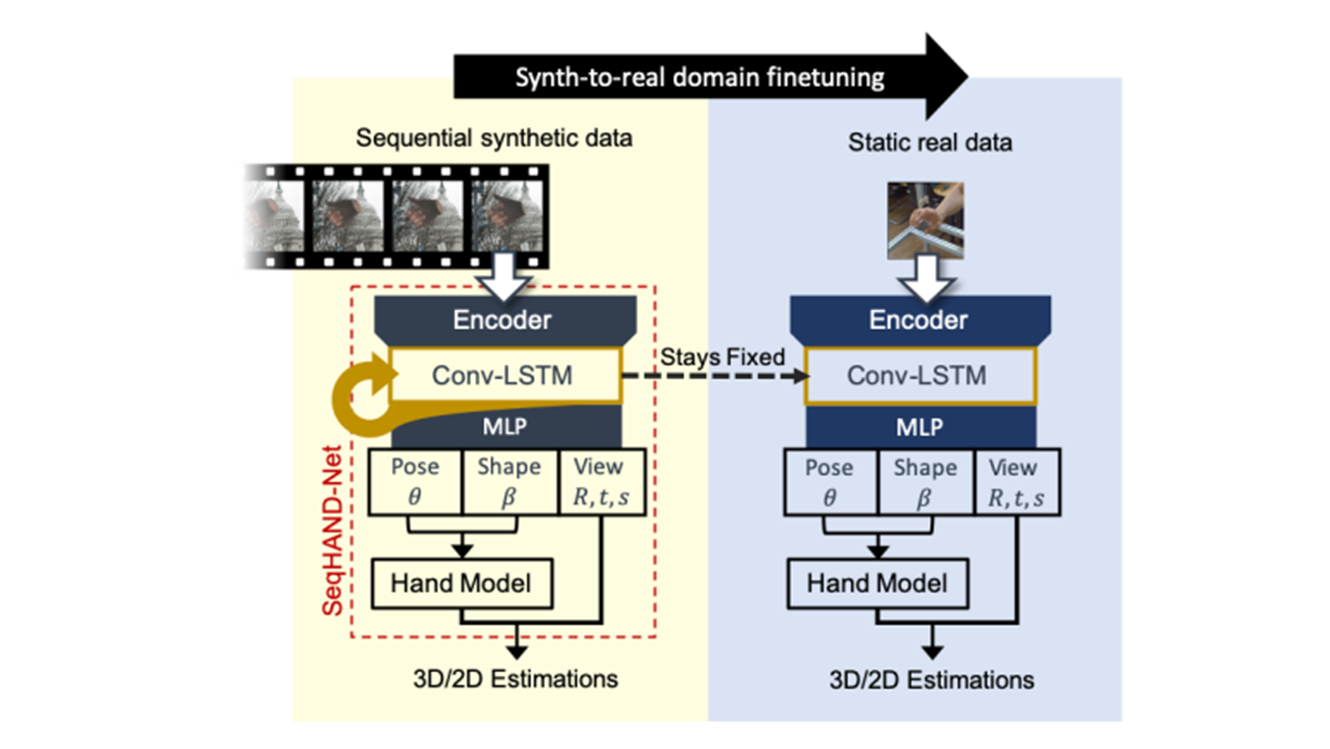
这篇文章提出了一种更好地利用时序信息进行人手重建的思路,先是渲染生成了一些时序的虚拟数据,然后使用这些数据进行模型的训练,最后再在真实数据上进行微调。
Method
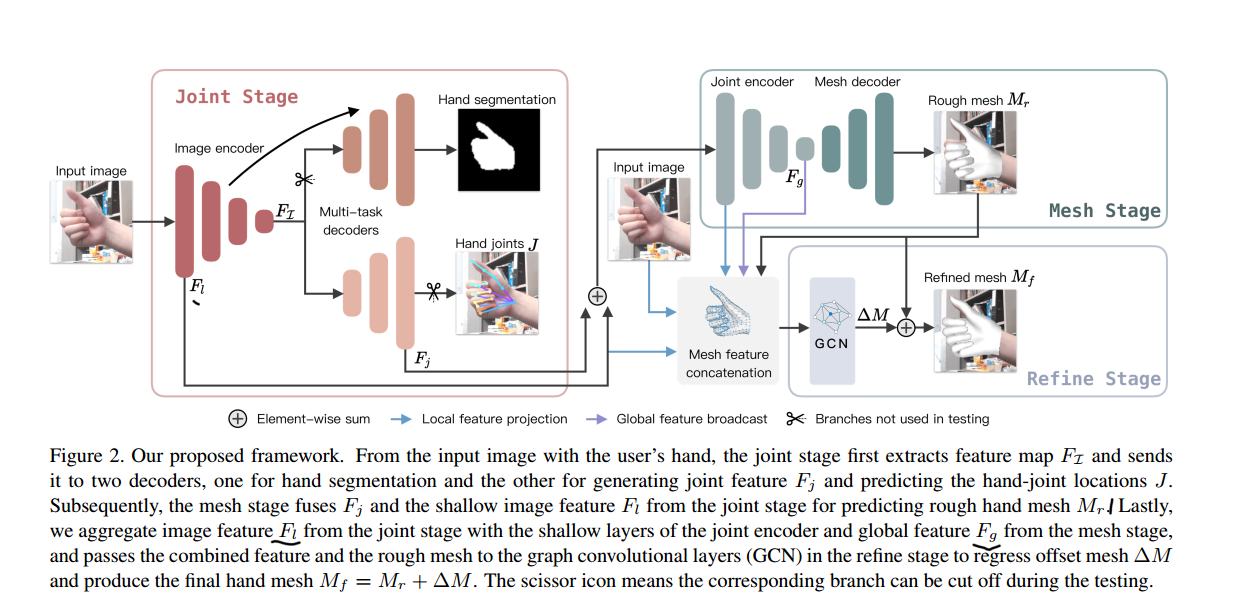
论文的方法,如上图所示,分为三个阶段:
The joint stage将输入图像编码然后预测手的Mask以及hand joints(手部关节点)。The mesh stage将前一个阶段图像encoder的浅层特征\(F_l\),以及Joints Decoder的特征\(F_j\)通过一个网络得到一个初始的Mesh。The Refine stage主要是使用了一个图神经网络,通过一个Local feature projection和Global feature projection预测出Rough Mesh \(M_r\)的一个偏置。
Joint stage
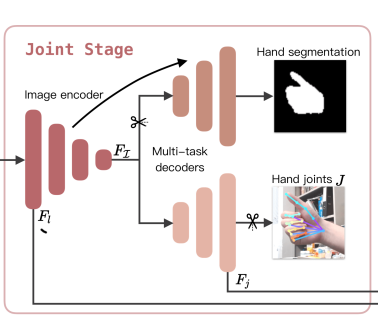
这个阶段的内容比较好理解,一张输入图片先通过一个Image encoder,然后经过一个decoder得到hand segmentation,再通过另一个decoder得到得到手部的关节点预测。在这里Hand segmentation分支发挥的作用主要是为了使得Image encoder在训练时,能够更好地捕获手的细节,尤其是边界。
Mesh stage
这一步作者把Image encoder的浅层特征\(F_l\)和Joint decoder的特征\(F_j\)加在一送入到下游网络,得到一个Rough Mesh\(M_r\)。
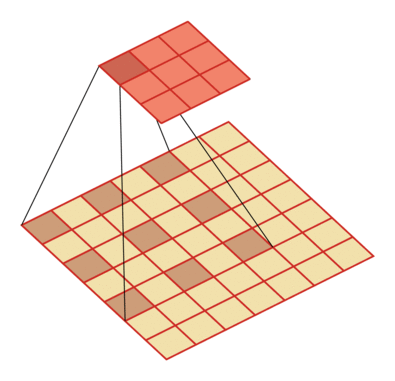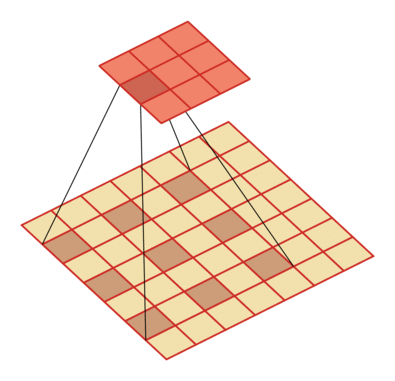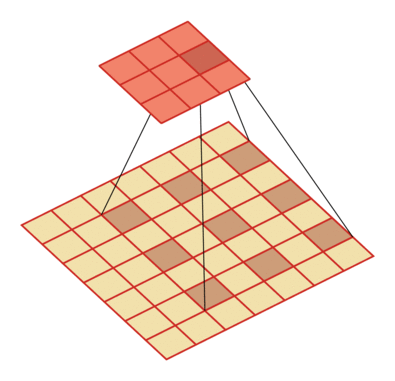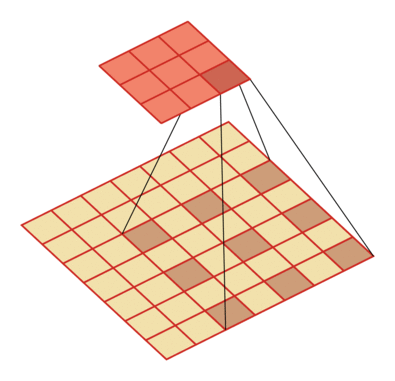
有一个知识点,这里的encoder, decoder使用的是扩张卷积(dilated convolution)[1],扩张卷积又名空洞卷积,相比原来的标准卷积,扩张卷积 多了一个称之为dilation rate(扩张率)的超参数,指的是kernel各点之间的间隔数量,正常的convolution 的 dilatation rate为 1。
| \(l = 1\) | \(l=2\) | \(l=3\) |
|---|---|---|
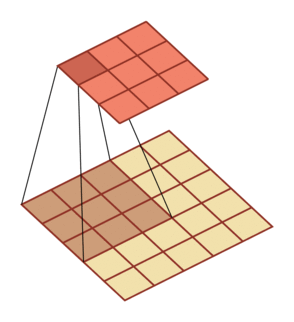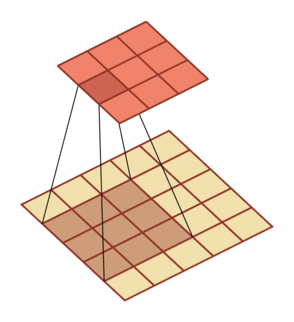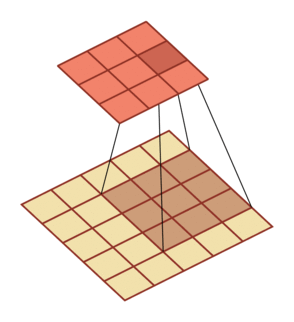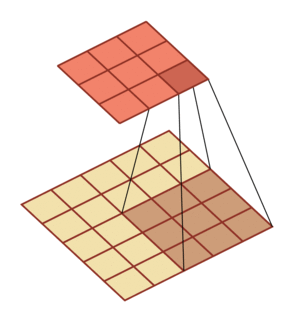 |
 |
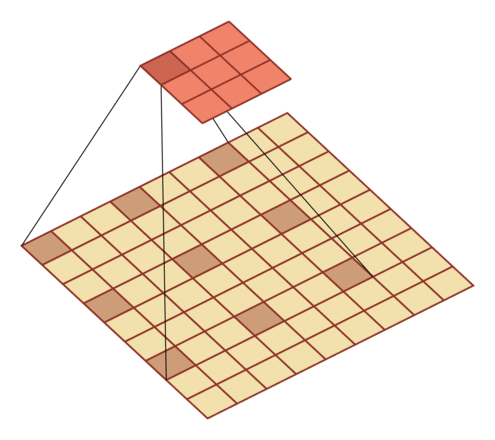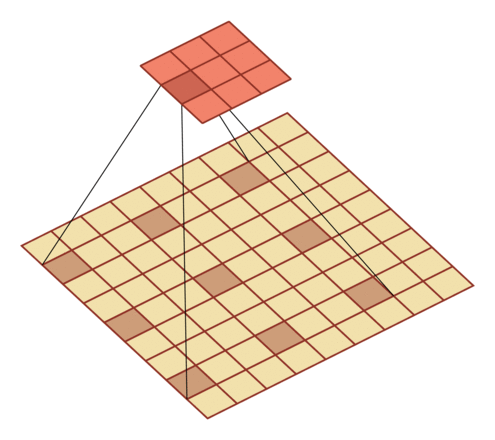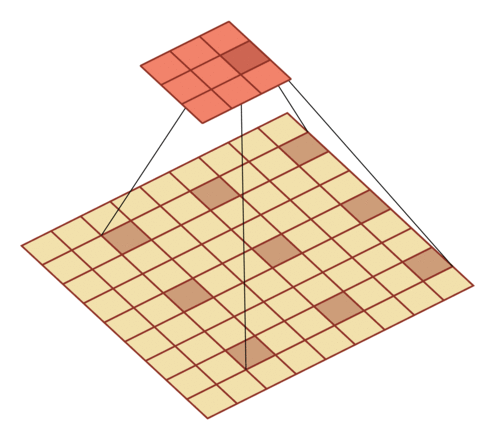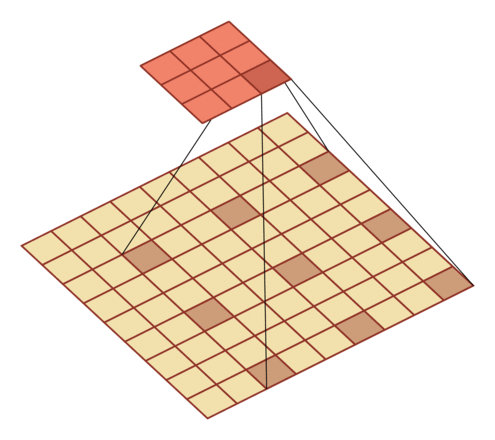 |
扩张卷积的主要目标是增大感受野,在目标检测和语义分割领域经常会看到此方法。
由于\(F_g\)最终是一个低维度的全局特征,由于扩张卷积核的存在,丢失了很多的局部特征。所以mesh stage预测出的mesh在图像空间里并不一定能与用户的手对齐(align),但是这个阶段却可以快速的得到手的一个大致的轮廓,然后在接下来的refine stage可以通过学习出mesh的偏置向量来对结果进行微调。
Refine stage
Mesh stage的核心是使用了一个图神经网络(GIN)来预测Mesh的偏置:
\]
\(x_i\)是图的第\(i\)个节点(对应的也就是rough mesh 里的第\(i\)个Mesh顶点)的特征;\(x_i^{\prime}\)是预测出的这个顶点的偏置;\(\mathcal{N}(i)\)是这个第\(i\)节点的邻居向量集合。
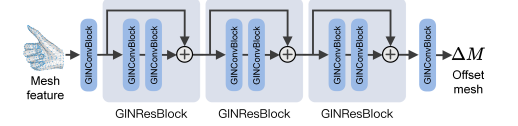
用通俗一点的语言描述就是,这里把手的一个mesh网格看做是一张图,每个节点的特征是由它自己和其邻居节点的特征求和得到,然后将这些特征输入到多层的MLP中去预测出节点的偏置。
下面,我们就去解读每个节点(等同于每个Mesh顶点)的特征如何得到的。
Local feature projection
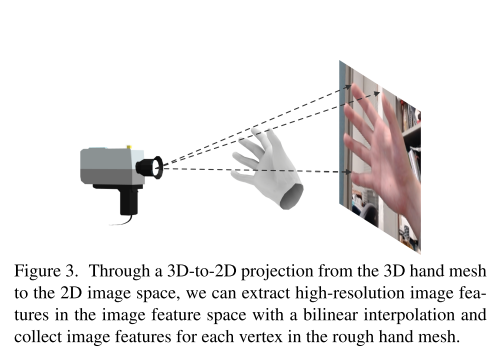
首先是将每个顶点(vertex)投影到输入图像的像素空间,然后使用得到的像素空间坐标,在输入图像,Image encoder的浅层feature map\(F_l\),Joint encoder得到的浅层Feature map上进行双线性插值,将这三者得到的特征组合成每个顶点的特征向量。
Global feature projection
局部特征有助于处理细节,但它们并不足够。这是因为它们不能提供有关整体手部网格结构的全局信息。针对这一问题,作者引入了Global feature projection,将网格的全局特征广播到每个网格顶点。使用Mesh stage的Joint encoder中获取深层特征\(Fg\),对其进行全局平均池化,得到一个一维向量,并使用全连接层将其通道维度减少1/4。最后,我们将这个全局特征向量再附加到每个顶点的特征向量上。正如方法大图中的紫色箭头表示的一样。
Refine stage的最终流程如下:

Training
这里我们主要是看一下这个模型的损失函数:
- Mesh loss && joint loss

normal loss && edge-length loss
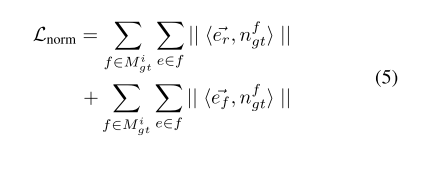
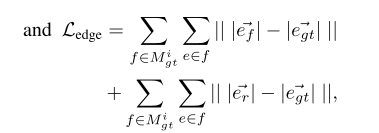
Hand segmentation loss

render loss

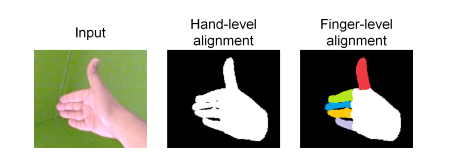
这里是把预测到的Hand mesh投影到2D空间里,然后得到一个二值Mask,使用它来监督模型的投影。不过作者在这里做的更加细化了,叫做finger-level,具体就是作者把 ground truth Hand mesh的手指标注了不同的颜色,然后使用投影得到的像素点颜色进行更加严格细致的监督。
最终的Loss
\]
根据经验设置
\]
Experiments
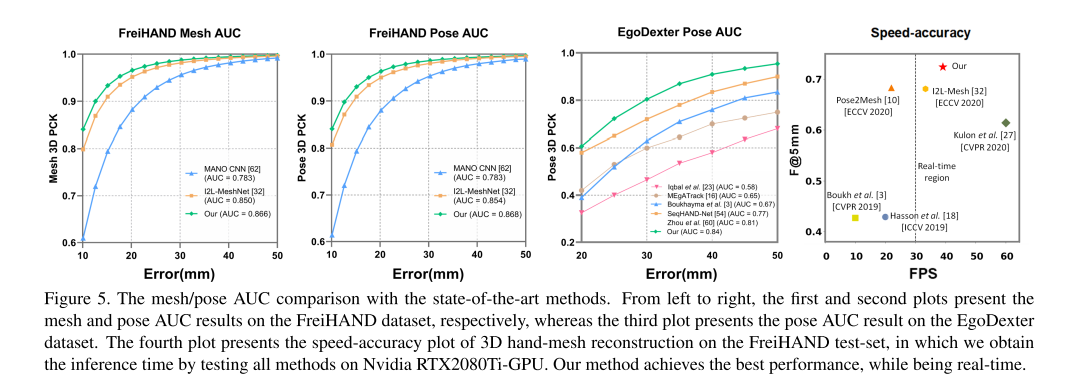

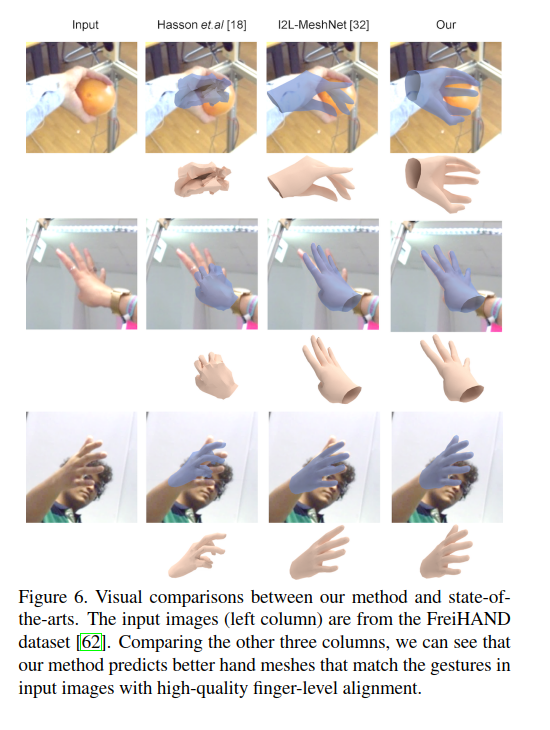
在这篇论文之前其实已经有好多手的几何重建工作了,但是不清楚为什么作者要和I2L-MeshNet[7]比,后者更加关注的是人体重建。
然后看一下对应的消融实验:
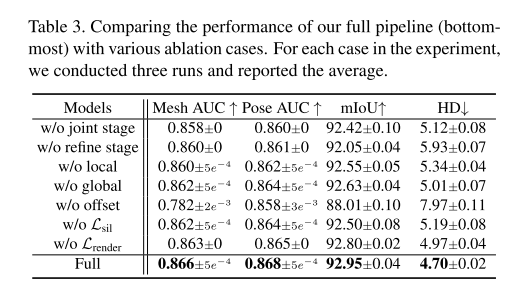
第二行是去掉最后的refine stage,将\(M_r\)作为最终模型的输出;
第三行是去掉vertex从Local projection unit得到的局部特征;
第四行是去掉vertex从Global projection unit得到的全局特征;
第五行是直接使用Graph-CNN预测最终的Hand Mesh而不是偏置向量,(可以看到这个对结果影响比较大,作者的解释是这个比较小的网络结构是设计用来regress small values;)
第六第七行则是去掉Mask segmentation Loss 还有 render loss的影响;
最后一行是 full pipeline。
Code
模型是在Nvidia RTX 2080ti 上进行训练的,不过作者在其代码主页没有给出对应的cuda和pytorch版本,我前期在这里因为版本问题踩了一些坑。最后经过推测得到的版本是 torch1.6 + cuda10.2,需要的朋友可以据此配置一下。

Summary
最后我想从真实的AR应用里谈一谈我对目前人手重建方法的理解,在这个应用里我觉得最重要的一个信息就是人手的viewpoint(R,t),只有通过这个信息,我们才能描述出人手与摄像机在三维世界里的位置关系,目前的人手重建方法一类是预测Mesh vertex在输入图像的相机坐标系下的位姿;一类是预测Mesh vertex在世界坐标系下的位置,往往还会再估计出一个相对于输入图像相机坐标系的viewpoint(R,t)。接下来的工作我准备在恢复人手viewpoint任务上进行测试,未完待续....
Refer
[1] 如何理解空洞卷积(dilated convolution)?
[2] Towards Accurate Alignment in Real-time 3D Hand-Mesh Reconstruction
[3] 3D Hand Shape and Pose from Images in the Wild
[4] 3D Hand Shape and Pose Estimation from a Single RGB Image
[5] FreiHAND: A Dataset for Markerless Capture of Hand Pose and Shape from Single RGB Images
[6] SeqHAND:RGB-Sequence-Based 3D Hand Pose and Shape Estimation
[8] Embodied hands: modeling and capturing hands and bodies together
Towards Accurate Alignment in Real-time 3D Hand-Mesh Reconstruction论文解读的更多相关文章
- 《Stereo R-CNN based 3D Object Detection for Autonomous Driving》论文解读
论文链接:https://arxiv.org/pdf/1902.09738v2.pdf 这两个月忙着做实验 博客都有些荒废了,写篇用于3D检测的论文解读吧,有理解错误的地方,烦请有心人指正). 博客原 ...
- 论文解读:3D Hand Shape and Pose Estimation from a Singl RGB Image
本文链接:https://blog.csdn.net/williamyi96/article/details/89207640由于最近做到了一些 3D Hand Pose Estimation 相关的 ...
- CVPR2020论文解读:三维语义分割3D Semantic Segmentation
CVPR2020论文解读:三维语义分割3D Semantic Segmentation xMUDA: Cross-Modal Unsupervised Domain Adaptation for 3 ...
- CVPR2020论文解读:3D Object Detection三维目标检测
CVPR2020论文解读:3D Object Detection三维目标检测 PV-RCNN:Point-Voxel Feature Se tAbstraction for 3D Object Det ...
- Fauce:Fast and Accurate Deep Ensembles with Uncertainty for Cardinality Estimation 论文解读(VLDB 2021)
Fauce:Fast and Accurate Deep Ensembles with Uncertainty for Cardinality Estimation 论文解读(VLDB 2021) 本 ...
- 论文解读(GMT)《Accurate Learning of Graph Representations with Graph Multiset Pooling》
论文信息 论文标题:Accurate Learning of Graph Representations with Graph Multiset Pooling论文作者:Jinheon Baek, M ...
- A Blind Watermarking for 3-D Dynamic Mesh Model Using Distribution of Temporal Wavelet Coefficients
这周看了一篇动态网格序列水印的论文,由于目前在网格序列上做水印的工作特别少,加之我所看的这篇论文中的叙述相对简洁,理解起来颇为困难.好在请教了博士师兄,思路明朗了许多,也就把这思路整理在此了. 论文作 ...
- 论文解读(ToAlign)《ToAlign: Task-oriented Alignment for Unsupervised Domain Adaptation》
论文信息 论文标题:ToAlign: Task-oriented Alignment for Unsupervised Domain Adaptation论文作者:Guoqiang Wei, Cuil ...
- 目标检测论文解读1——Rich feature hierarchies for accurate object detection and semantic segmentation
背景 在2012 Imagenet LSVRC比赛中,Alexnet以15.3%的top-5 错误率轻松拔得头筹(第二名top-5错误率为26.2%).由此,ConvNet的潜力受到广泛认可,一炮而红 ...
- Computer Graphics Research Software
Computer Graphics Research Software Helping you avoid re-inventing the wheel since 2009! Last update ...
随机推荐
- [炼丹术]YOLOR目标检测训练模型学习总结
YOLOR目标检测训练模型学习总结 性能测试 python test.py --data data/cocoaml --img 320 --batch 8 --conf 0.001 --iou 0.6 ...
- 字节二面:你怎么理解信道是golang中的顶级公民
1. 信道是golang中的顶级公民 goroutine结合信道channel是golang中实现并发编程的标配. 信道给出了一种不同于传统共享内存并发通信的新思路,以一种通道复制的思想解耦了并发编程 ...
- 关于动态使用keepAlive不生效的问题
首先,我想实现在返回页面时,页面不进行刷新,比如我原先选择的第四页,返回后显示了第一页 想到使用keepAlive缓存组件,大部分推荐的方法为这样,但是不生效 <keep-alive v-if= ...
- Solution Set - “女孩是瑰宝我心动一丝不苟”
目录 0.「NOI Simu.」静态顶树 1.「NOI Simu.」祖先 2.「NOI Simu.」睡眠 3.「JLOI 2008」「洛谷 P3881」CODES 4.「ARC 163A」Divide ...
- Java 链表API
Java 链表 1.什么是链表? 链表是一种物理存储单元上非连续.非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针连接次序实现的. 每一个链表都包含多个节点,节点又包含两个部分: 1)一个是数据 ...
- biancheng-Spring Cloud Alibaba Seata
随着业务的不断发展,单体架构已经无法满足我们的需求,分布式微服务架构逐渐成为大型互联网平台的首选,但所有使用分布式微服务架构的应用都必须面临一个十分棘手的问题,那就是"分布式事务" ...
- CentOS 7 MongoDB 重装启动失败
诊断过程 1. 错误提示: > journalctl -xe 提示: .... ERROR: child process failed, exited with error number 14 ...
- 调试存储过程中出现 [Microsoft][ODBC SQL Server Driver]对于造型说明无效的字符值
调试存储时如果有日期类型的参数,传入格式为:2020-07-13 12:00:00 ,无需用引号括起来. 否则会提示[Microsoft][ODBC SQL Server Driver]对于造型说明无 ...
- Oracle如何查找指定字符串所出现的表
declare v_sql varchar2(2000); v_count number; begin for cur in(select t.owner, t.table_name, t.colum ...
- 云内GSLB技术及应用场景
本文分享自天翼云开发者社区<云内GSLB技术及应用场景>,作者:c****n 云业务容灾建设节奏一般是同城双活-异地双活-两地三中心(同城双活+异地多活),因为要解决的问题的复杂度和难度也 ...