Join 实现 2 表数据联动
最近在做一个简单的报表, 用的工具是帆软报表, 一开始觉得有点low, 现在看看还行, 除了界面真的太丑外, 其它还要, 这种大量要使用 sql 的方式, 我觉得是非常灵活高效的, I like . 这个过程 sql 确实也提高了不少. 其中有个需求, 是要做个数据联动, 报表之间的部分字段的联动变化.
需求
两张表, B 表的某些字段要 跟随 A 表的变化实现级联, 也不是级联,就是完全同步.
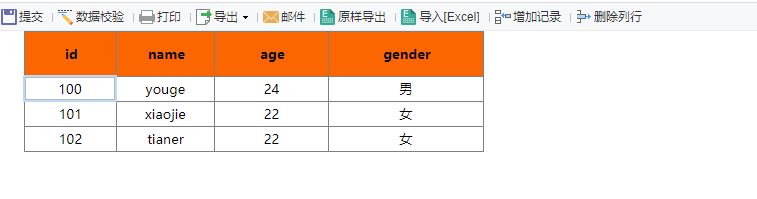
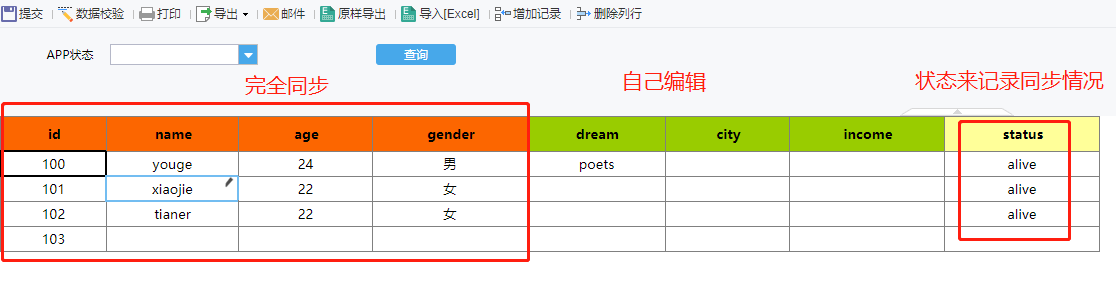
分析了一波, 本以为要做个级联操作, 但一看, 其实就是, join 就能解决的呀.
实现
首先要考虑 B 表原有的数据不能动, 然后再进行联动.. 还是建表等来说明整个原理吧.
数据准备
drop table if exists tb_01;
create table tb_01(
id varchar(20) primary key,
name varchar(20),
age int,
gender varchar(30),
-- 默认值
alive varchar(30) not null default 'alive'
);
insert into tb_01(id, name, age, gender) values ('100', 'youge', 24, '男');
insert into tb_01(id, name, age, gender) values ('101', 'xiaojie', 22, '女');
insert into tb_01(id, name, age, gender) values ('102', 'tianer', 22, '女');
drop table if exists tb_02;
create table tb_02(
id varchar(20) primary key,
name varchar(20),
age int,
gender varchar(30),
dream varchar(20),
city varchar(20),
income int,
-- alive 有值表示同步中, 无值则表示离线状态
status varchar(20) null
);
insert into tb_02(id) values ('100');
insert into tb_02(id) values ('101');
insert into tb_02(id) values ('102');
insert into tb_02(id) values ('103');
初始数据如下:
-- preview
mysql> select * from tb_01;
+-----+---------+------+--------+
| id | name | age | gender |
+-----+---------+------+--------+
| 100 | youge | 24 | 男 |
| 101 | xiaojie | 22 | 女 |
| 102 | tianer | 22 | 女 |
+-----+---------+------+--------+
3 rows in set (0.00 sec)
mysql> select * from tb_02;
+-----+------+------+--------+-------+------+--------+-------+
| id | name | age | gender | dream | city | income | alive |
+-----+------+------+--------+-------+------+--------+-------+
| 100 | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
| 101 | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
| 102 | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
| 103 | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
+-----+------+------+--------+-------+------+--------+-------+
4 rows in set (0.00 sec)
过程细节
先要让 B 表的数据不能动, 初始化的时候.
select
a.id as a_id,
b.id,
b.name,
b.age,
b.gender,
b.dream,
b.city,
b.income,
b.alive
from tb_01 as a
right join tb_02 as b
on a.id = b.id
left join 和 right join 灵活使用需要哦
B 表左连接 A 表 这个结果作为 C 表
+------+-----+------+------+--------+-------+------+--------+-------+
| a_id | id | name | age | gender | dream | city | income | alive |
+------+-----+------+------+--------+-------+------+--------+-------+
| 100 | 100 | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
| 101 | 101 | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
| 102 | 102 | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
| NULL | 103 | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
+------+-----+------+------+--------+-------+------+--------+-------+
A 表再 和 C 表做左连接 (同步新增等情况的的数据)
select
a.id,
a.name,
a.age,
a.gender,
-- c.a_id,
c.dream,
c.city,
c.income,
c.alive
from tb_01 as a
left join (
select
a.id as a_id,
b.id,
b.name,
b.age,
b.gender,
b.dream,
b.city,
b.income,
b.alive
from tb_01 as a
right join tb_02 as b
on a.id = b.id
) as c
on a.id = c.id
-- A 表删减记录, 不会影响 B 表原有的
and c.a_id is not null
-- 左边作为作为联动标准(中间表01)
+-----+---------+------+--------+-------+------+--------+-------+
| id | name | age | gender | dream | city | income | alive |
+-----+---------+------+--------+-------+------+--------+-------+
| 100 | youge | 24 | 男 | NULL | NULL | NULL | NULL |
| 101 | xiaojie | 22 | 女 | NULL | NULL | NULL | NULL |
| 102 | tianer | 22 | 女 | NULL | NULL | NULL | NULL |
+-----+---------+------+--------+-------+------+--------+-------+
3 rows in set (0.00 sec)
将此中间表01, 主键插入到 目标表 tb_02
主键插入: 主键冲突则覆盖, 否则新增,即在帆软的 主键填报
mysql> select * from tb_02;
+-----+---------+------+--------+-------+------+--------+-------+
| id | name | age | gender | dream | city | income | alive |
+-----+---------+------+--------+-------+------+--------+-------+
| 100 | youge | 24 | 男 | NULL | NULL | NULL | NULL |
| 101 | xiaojie | 22 | 女 | NULL | NULL | NULL | NULL |
| 102 | tianer | 22 | 女 | NULL | NULL | NULL | NULL |
| 103 | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
+-----+---------+------+--------+-------+------+--------+-------+
4 rows in set (0.00 sec)
等待提交完后, 还要标记出, 哪些是同步的, 哪些是离线的。
即: 用 A 表 right join 目标表, 能匹配上的, 就是同步的呗。
-- step_02 (木丁就是 给 alive 字段打上标签)
select
b.id,
b.name,
b.age,
b.gender,
b.dream,
b.city,
b.income,
-- 匹配上的 将 alive 填充为 该记录的ID
a.id as alive
from tb_01 as a
right join tb_02 as b
on a.id = b.id
+-----+---------+------+--------+-------+------+--------+-------+-------+
| id | name | age | gender | dream | city | income | alive | alive |
+-----+---------+------+--------+-------+------+--------+-------+-------+
| 100 | youge | 24 | 男 | NULL | NULL | NULL | NULL | 100 |
| 101 | xiaojie | 22 | 女 | NULL | NULL | NULL | NULL | 101 |
| 102 | tianer | 22 | 女 | NULL | NULL | NULL | NULL | 102 |
| 103 | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
+-----+---------+------+--------+-------+------+--------+-------+-------+
4 rows in set (0.00 sec)
=> 再 提交一波 (主键插入) 则是最新的了。
mysql> select * from tb_02;
+-----+---------+------+--------+-------+------+--------+-------+
| id | name | age | gender | dream | city | income | alive |
+-----+---------+------+--------+-------+------+--------+-------+
| 100 | youge | 24 | 男 | NULL | NULL | NULL | NULL |
| 101 | xiaojie | 22 | 女 | NULL | NULL | NULL | NULL |
| 102 | tianer | 22 | 女 | NULL | NULL | NULL | NULL |
| 103 | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
+-----+---------+------+--------+-------+------+--------+-------+
4 rows in set (0.00 sec)
核心过程
就是两步, 先左连接, 再右连接嘛, 中间需要2次主键插入. 虽然看着这里, sql 很多, 其实主要还是多在字段上, 逻辑非常清晰哦.
select
a.id,
a.name,
a.age,
a.gender,
-- c.a_id,
c.dream,
c.city,
c.income,
c.alive
from tb_01 as a
left join (
select
a.id as a_id,
b.id,
b.name,
b.age,
b.gender,
b.dream,
b.city,
b.income,
b.alive
from tb_01 as a
-- 共有的
left join tb_02 as b
on a.id = b.id
) as c
on a.id = c.id
and c.a_id is not null
提交一波哦 !!!
-- step_02 (木丁就是 给 alive 字段打上标签)
select
b.id,
b.name,
b.age,
b.gender,
b.dream,
b.city,
b.income,
-- 匹配上的 将 alive 填充为 该记录的ID
a.id as alive
from tb_01 as a
right join tb_02 as b
on a.id = b.id
简化版(B表跟A表初始一样)
直接就一个左连接, (主键插入), 然后, 再来一个右连接, 匹配上的 id 给作为 行打上一个标签即可.
-- step_01:
select
a.*,
b.dream,
b.city,
b.income,
b.status
from tb_01 as a
left join tb_02 as b
on a.id = b.id
-- step_02:
-- A 表 跟 目标表 右连接, 能匹配上, 就将
-- A表的 id 填到 B 的 alive 字段中.
select
b.id,
b.name,
b.age,
b.gender,
b.dream,
b.city,
b.income,
b.city,
-- A 表的 id (匹配上)
a.alive as status
from tb_01 as a
right join tb_02 as b
on a.id = b.id
实现效果
增改查必然是没有问题的的, 主要来看一波删除操作.

现在呢, 假设 A 表将 102 给删掉, 那最终的结果呢, 是在 B 表中, status 的状态 alive 变为 空 而已, 达到 逻辑删除 的效果, 这样也更能满足业务的回查数据的需要.
先一波 102 删除后, 中间表 step_01 的联动效果:

这时候, 目标表, 一旦 刷新 , 这状态就同步了呀.

小结
- 数据联动 Join 左,右 连接, 就能轻松搞定, 一开始想复杂了, 用主外键级联, 和存储过程, 触发器等复杂方式
- Join 配合这种 "主键更新表" 的方式, 能实现, 标记字段值的回填, 动态插入值, 这种操作还是很强大的
- SQL 配合相应的工具使用, 如之前的 Tableau 和现用帆软报表, 越来发现 SQL 是真的香.
Join 实现 2 表数据联动的更多相关文章
- 【Spark调优】小表join大表数据倾斜解决方案
[使用场景] 对RDD使用join类操作,或者是在Spark SQL中使用join语句时,而且join操作中的一个RDD或表的数据量比较小(例如几百MB或者1~2GB),比较适用此方案. [解决方案] ...
- mysql left join 右表数据不唯一的情况解决方法
mysql left join 右表数据不唯一的情况解决方法 <pre>member 表id username1 fdipzone2 terry member_login_log 表id ...
- BPM配置故事之案例14-数据字典与数据联动
小明遇到了点麻烦,他昨天又收到了行政主管发来的邮件,要求把出差申请单改由H3 BPM进行,表单如下 行政主管的出差申请表 小明对表单进行了调整,设计出了一份适合在系统中使用的表单,但在"出差 ...
- SQL Server 更改跟踪(Chang Tracking)监控表数据
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 主要区别与对比(Compare) 实现监控表数据步骤(Process) 参考文献(Refere ...
- SQL表关联赋值、系统表、表数据删除
1. 表与表的关联赋值(用于表与表之间有关联字段,数据互传) 双表关联赋值 UPDATE #B SET #B.D=#A.B from #B inner join #A on #B.C=#A.A 多表关 ...
- LINQ 联查多表数据并封装到ViewModel的实现
LINQ 联查多表数据并封装到ViewModel的实现 public List<MyTask> GetPagedTaskList(int pageIndex, int pageSize, ...
- SQL Server 的表数据简单操作(表数据查询)
--表数据查询----数据的基本查询-- --数据简单的查询--select * | 字段名[,字段名2, ...] from 数据表名 [where 条件表达式] 例: use 商品管理数据库 go ...
- 利用Sql实现将指定表数据导入到另一个数据库示例
因为工作中经常需要将数据从一个数据库导入到另一个数据库中,所以将这个功能写成一个存储过程,以方便调用.现在粘贴出来供大家参考: 注意:1,以下示例中用到了syscolumns,sysobjects等系 ...
- SOME:收缩数据库日志文件,查看表数据量和空间占用,查看表结构索引修改时间
---收缩数据库日志文件 USE [master]ALTER DATABASE yourdatabasename SET RECOVERY SIMPLE WITH NO_WAITALTER DATAB ...
- 工作随笔——mysql子查询删除原表数据
最近在开发的时候遇到一个mysql的子查询删除原表数据的问题.在网上也看了很多方法,基本也是然并卵(不是写的太乱就是效率太慢). 公司DBA给了一个很好的解决方案,让人耳目一新. DELETE fb. ...
随机推荐
- 简单编写Makefile与使用make工具
简单编写Makefile与使用make工具 在不使用make工具下对c文件的编译 gcc main.c -o out gcc <目标文件> -o <生成执行文件> 编译到执行文 ...
- 升级 element-ui 2.15.7 后遇到 el-date-picker 警告问题
近期把 element-ui 升级到了官网最新的 2.15.7 版本,无意间发现控制台出现了 Prop being mutated: "placement" 警告,完整警告:
- .NET10 - 预览版1新功能体验(一)
.NET 10 首个预览版已经在前两天发布,该版本在 .NET Runtime.SDK.libraries.C#.ASP.NET Core.Blazor 和 .NET MAUI 等多个方面都有重大改进 ...
- Windows 提权-MSSQL
本文通过 Google 翻译 MSSQL – Windows Privilege Escalation 这篇文章所产生,本人仅是对机器翻译中部分表达别扭的字词进行了校正及个别注释补充. 导航 0 前言 ...
- 【Python】尝试切换py版本
失败 问chatgpt,怎么把abaqus python 版本切换到py3.6,结果失败. chatgpt给出的建议: 修改abaqus_v6.env,明显扯淡!我就尝试在custom_v6.env中 ...
- C#语言碎片:Switch-Case语句字符串匹配
Switch case语句在处理字符串类型匹配时候,case条件需要设置为静态常量或者一个具体的字符串: 因为工具类ToolHand.Name 为变量,所以编译不通过. 使用if语句来逐个判断: 看A ...
- Java List和Array之间的转换
import java.util.Arrays; import java.util.List; class Test { //Object数组向List的转换 public static List&l ...
- NumPy学习4
今天学习NumPy相关数组操作 NumPy 中包含了一些处理数组的常用方法,大致可分为以下几类:(1)数组变维操作(2)数组转置操作(3)修改数组维度操作(4)连接与分割数组操作 numpy_test ...
- 出现TypeError: float() argument must be a string or a number, not _NoValueType(机器学习 Win11)
博客地址:https://www.cnblogs.com/zylyehuo/ 如果出现以下报错 则说明是torch.numpy等库的版本不匹配 可以去以下网站寻找匹配的版本 https://mirro ...
- 虚拟机使用ESXi主机物理硬盘的办法
虚拟机使用ESXi主机物理硬盘的办法 weixin_33928137 于 2018-06-19 15:22:06 发布 868 收藏 1文章标签: 运维版权 VMware Workstation的虚拟 ...