第8讲、Multi-Head Attention 的核心机制与实现细节
为什么要有 Multi-Head Attention?
单个 Attention 机制虽然可以捕捉句子中不同词之间的关系,但它只能关注一种角度或模式。
Multi-Head 的作用是:
多个头 = 多个视角同时观察序列的不同关系。
例如:
- 一个头可能专注主语和动词的关系;
- 另一个头可能专注宾语和介词;
- 还有的可能学习句法结构或时态变化。
这些头的表示最终会被拼接(concatenate)后再线性变换整合成更丰富的上下文表示。
技术深入:Multi-Head Attention 计算过程
Multi-Head Attention 的计算过程如下:
- 对输入 X 进行线性变换得到 Q、K、V 矩阵
- 将 Q、K、V 分割成 h 个头
- 每个头独立计算 Attention
- 拼接所有头的输出
- 最后进行一次线性变换
# 伪代码实现
def multi_head_attention(X, h=8):
# 线性变换获得 Q, K, V
Q = X @ W_q # [batch_size, seq_len, d_model]
K = X @ W_k
V = X @ W_v
# 分割成多头
Q_heads = split_heads(Q, h) # [batch_size, h, seq_len, d_k]
K_heads = split_heads(K, h)
V_heads = split_heads(V, h)
# 每个头独立计算 attention
attn_outputs = []
for i in range(h):
attn_output = scaled_dot_product_attention(
Q_heads[:, i], K_heads[:, i], V_heads[:, i]
)
attn_outputs.append(attn_output)
# 拼接所有头的输出
concat_output = concatenate(attn_outputs) # [batch_size, seq_len, d_model]
# 最后的线性变换
output = concat_output @ W_o
return output
如何判断多少个头(h)?
Transformer 默认将 d_model(模型维度)均分给每个头。
设:
d_model = 512:模型的总嵌入维度h = 8:头数
那么每个头的维度为:
d_k = d_model // h = 512 // 8 = 64
一般要求:
️
d_model必须能被h整除。
参数计算
Multi-Head Attention 中的参数量:
- 输入投影矩阵:3 × (d_model × d_model) = 3d_model²
- 输出投影矩阵:d_model × d_model = d_model²
总参数量:4 × d_model²
例如,当 d_model = 512 时,参数量约为 100 万。
头的数量怎么选?
头数 h |
每头维度 d_k |
适用情境 |
|---|---|---|
| 1 | 全部 | 基线,最弱(没多视角) |
| 4 | 中等 | 小模型,如 tiny Transformer |
| 8 | 64 | 标准配置,如原始 Transformer |
| 16 | 更细粒度 | 大模型中常见,如 BERT-large |
实际训练中:
- 小任务(toy 或翻译教学):用 2 或 4 个头就够了。
- 真实 NLP 任务:建议使用 8 个头(Transformer-base 规范)。
- 太多头而模型参数不足时,效果可能反而下降(每头维度太小)。
头数与性能关系
研究表明,头数与模型性能并非简单的线性关系:
- 头数过少:无法捕捉多种语言模式
- 头数适中:性能最佳
- 头数过多:每个头的维度变小,表达能力下降

实验发现
Michel et al. (2019) 的研究《Are Sixteen Heads Really Better than One?》发现:
- 在训练好的模型中,并非所有头都同等重要
- 大多数情况下,可以剪枝掉一部分头而不显著影响性能
- 不同层的头有不同的作用,底层头和顶层头往往更为重要
Multi-Head Attention 的优势
- 并行计算:所有头可以并行计算,提高训练效率
- 多角度表示:捕捉不同类型的依赖关系
- 信息冗余:多头提供冗余信息,增强模型鲁棒性
- 注意力分散:防止单一头过度关注某些模式
总结一句话
Multi-Head 的本质是多角度捕捉词与词的关系,提升模型对上下文的理解能力。头数越多,观察角度越多,但每个头的维度会减小,需注意平衡。
Attention 可视化
不同头学习到的注意力模式各不相同。以下是一个英语句子在 8 头注意力机制下的可视化示例:

可以看到:
- 头1:关注相邻词的关系
- 头2:捕捉主语-谓语关系
- 头3:识别句法结构
- 头4:连接相关实体
- 其他头:各自专注于不同的语言特征
这种多角度的观察使得 Transformer 能够全面理解文本的语义和结构。
️ Streamlit 交互式可视化案例
想要直观地理解 Multi-Head Attention?以下是一个使用 Streamlit 构建的交互式可视化案例,让你可以实时探索不同头的注意力模式:
import streamlit as st
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import seaborn as sns
from transformers import BertTokenizer, BertModel
# 页面设置
st.set_page_config(page_title="Multi-Head Attention 可视化", layout="wide")
st.title("Multi-Head Attention 可视化工具")
# 加载预训练模型
@st.cache_resource
def load_model():
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertModel.from_pretrained('bert-base-chinese', output_attentions=True)
return tokenizer, model
tokenizer, model = load_model()
# 用户输入
user_input = st.text_area("请输入一段文本进行分析:",
"Transformer是一种强大的神经网络架构,它使用了Multi-Head Attention机制。",
height=100)
# 处理文本
if user_input:
# 分词并获取注意力权重
inputs = tokenizer(user_input, return_tensors="pt")
outputs = model(**inputs)
# 获取所有层的注意力权重
attentions = outputs.attentions # tuple of tensors, one per layer
# 选择层
layer_idx = st.slider("选择Transformer层:", 0, len(attentions)-1, 0)
# 获取选定层的注意力权重
layer_attentions = attentions[layer_idx].detach().numpy()
# 获取头数
num_heads = layer_attentions.shape[1]
# 选择头
head_idx = st.slider("选择注意力头:", 0, num_heads-1, 0)
# 获取选定头的注意力权重
head_attention = layer_attentions[0, head_idx]
# 获取标记
tokens = tokenizer.convert_ids_to_tokens(inputs["input_ids"][0])
# 可视化
fig, ax = plt.subplots(figsize=(10, 8))
sns.heatmap(head_attention,
xticklabels=tokens,
yticklabels=tokens,
cmap="YlGnBu",
ax=ax)
plt.title(f"第 {layer_idx+1} 层,第 {head_idx+1} 个头的注意力权重")
st.pyplot(fig)
# 显示注意力模式分析
st.subheader("注意力模式分析")
# 计算每个词的平均注意力
avg_attention = head_attention.mean(axis=0)
top_indices = np.argsort(avg_attention)[-3:][::-1]
st.write("这个注意力头主要关注的词:")
for idx in top_indices:
st.write(f"- {tokens[idx]}: {avg_attention[idx]:.4f}")
# 添加交互式功能
if st.checkbox("显示所有头的对比"):
st.subheader("所有头的注意力对比")
# 为每个头创建一个小型热力图
# 计算行列数以适应任意数量的头
num_cols = 4
num_rows = (num_heads + num_cols - 1) // num_cols # 向上取整
fig, axes = plt.subplots(num_rows, num_cols, figsize=(15, 3*num_rows))
axes = axes.flatten()
for h in range(num_heads):
sns.heatmap(layer_attentions[0, h],
xticklabels=[] if h < (num_heads-num_cols) else tokens,
yticklabels=[] if h % num_cols != 0 else tokens,
cmap="YlGnBu",
ax=axes[h])
axes[h].set_title(f"头 {h+1}")
# 隐藏未使用的子图
for h in range(num_heads, len(axes)):
axes[h].axis('off')
plt.tight_layout()
st.pyplot(fig)
# 添加解释
st.markdown("""
### 如何解读这个可视化:
- 颜色越深表示注意力权重越高
- 纵轴代表查询词(当前词)
- 横轴代表键词(被关注的词)
- 每个头学习不同的关注模式
通过调整滑块,你可以探索不同层和不同头的注意力模式,观察模型如何理解文本中的关系。
""")
# 运行说明
st.sidebar.markdown("""
## 使用说明
1. 在文本框中输入你想分析的文本
2. 使用滑块选择要查看的层和注意力头
3. 查看热力图了解词与词之间的注意力关系
4. 勾选"显示所有头的对比"可以同时查看所有头的模式
这个工具帮助你直观理解 Multi-Head Attention 的工作原理和不同头的功能分工。
""")
# 代码说明
with st.expander("查看完整代码实现"):
st.code("""
import streamlit as st
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import seaborn as sns
from transformers import BertTokenizer, BertModel
# 页面设置
st.set_page_config(page_title="Multi-Head Attention 可视化", layout="wide")
st.title("Multi-Head Attention 可视化工具")
# 加载预训练模型
@st.cache_resource
def load_model():
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertModel.from_pretrained('bert-base-chinese', output_attentions=True)
return tokenizer, model
tokenizer, model = load_model()
# 用户输入和可视化逻辑
# ...此处省略,与上面代码相同
""")
### 如何运行这个可视化工具
1. 安装必要的依赖:
```bash
pip install streamlit torch transformers matplotlib seaborn
将上面的代码保存为
attention_viz.py运行 Streamlit 应用:
streamlit run attention_viz.py
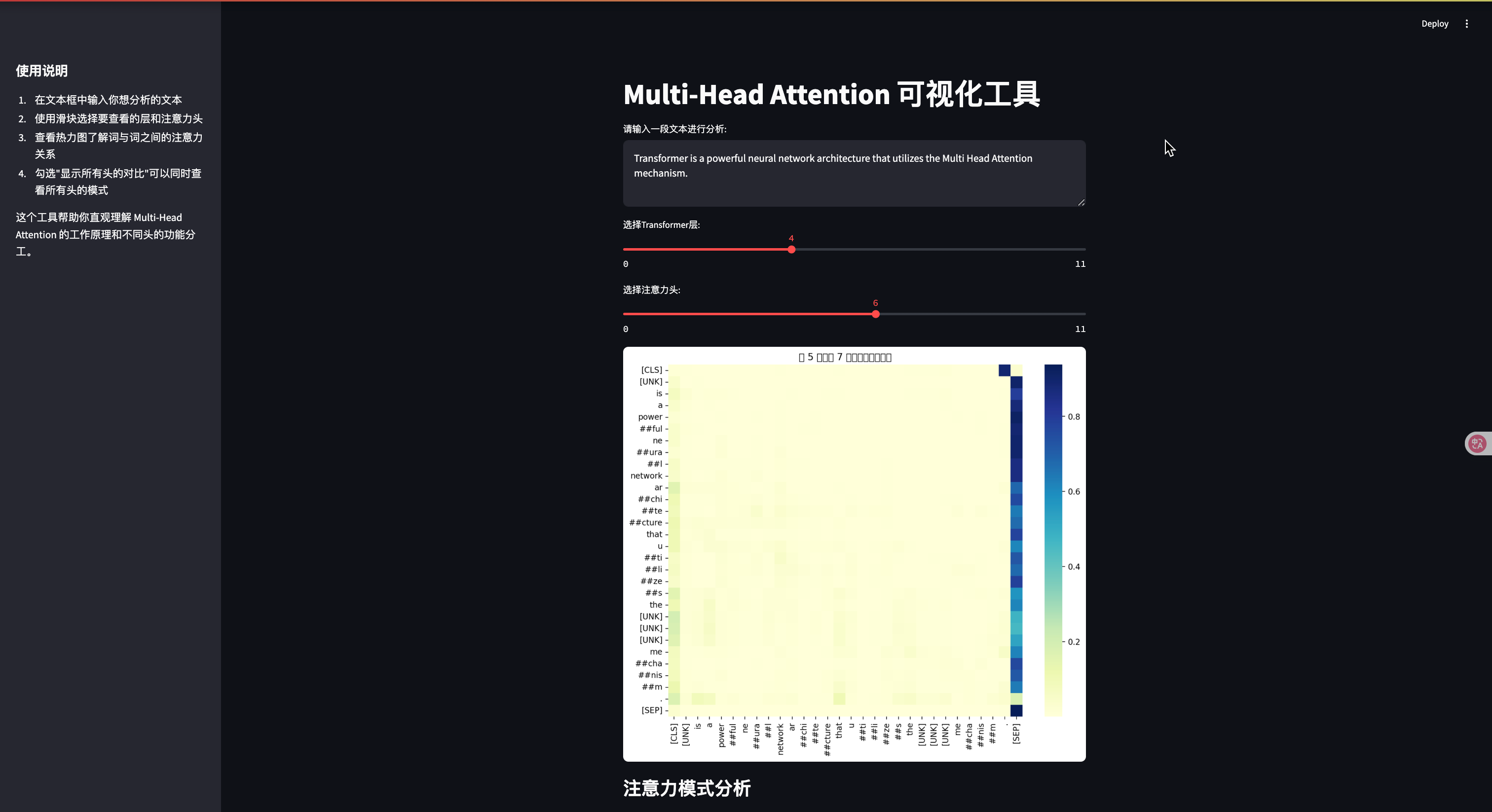

这个交互式工具让你可以:
- 输入任意文本并查看注意力分布
- 选择不同的 Transformer 层和注意力头
- 直观对比不同头学习到的不同模式
- 分析哪些词获得了最高的注意力权重
通过这个可视化工具,你可以亲自探索 Multi-Head Attention 的工作原理,加深对这一机制的理解。
第8讲、Multi-Head Attention 的核心机制与实现细节的更多相关文章
- MFC六大核心机制之二:运行时类型识别(RTTI)
上一节讲的是MFC六大核心机制之一:MFC程序的初始化,本节继续讲解MFC六大核心机制之二:运行时类型识别(RTTI). typeid运算子 运行时类型识别(RTTI)即是程序执行过程中知道某个对象属 ...
- multi lstm attention 坑一个
multi lstm attention时序之间,inputs维度是1024,加上attention之后维度是2018,输出1024,时序之间下次再转成2048的inputs 但是如果使用multi ...
- MFC六大核心机制之一:MFC程序的初始化
很多做软件开发的人都有一种对事情刨根问底的精神,例如我们一直在用的MFC,很方便,不用学太多原理性的知识就可以做出各种窗口程序,但喜欢钻研的朋友肯定想知道,到底微软帮我们做了些什么,让我们在它的框架下 ...
- Qt核心机制与原理
转: https://blog.csdn.net/light_in_dark/article/details/64125085 ★了解Qt和C++的关系 ★掌握Qt的信号/槽机制的原理和使用方法 ★ ...
- Spark大数据处理 之 从WordCount看Spark大数据处理的核心机制(1)
大数据处理肯定是分布式的了,那就面临着几个核心问题:可扩展性,负载均衡,容错处理.Spark是如何处理这些问题的呢?接着上一篇的"动手写WordCount",今天要做的就是透过这个 ...
- Qt核心机制和原理
转:http://blog.csdn.net/light_in_dark/article/details/64125085 ★了解Qt和C++的关系 ★掌握Qt的信号/槽机制的原理和使用方法 ★了解Q ...
- Spark大数据处理 之 从WordCount看Spark大数据处理的核心机制(2)
在上一篇文章中,我们讲了Spark大数据处理的可扩展性和负载均衡,今天要讲的是更为重点的容错处理,这涉及到Spark的应用场景和RDD的设计来源. Spark的应用场景 Spark主要针对两种场景: ...
- 如何优雅的写UI——(1)MFC六大核心机制-程序初始化
很多做软件开发的人都有一种对事情刨根问底的精神,例如我们一直在用的MFC,很方便,不用学太多原理性的知识就可以做出各种窗口程序,但喜欢钻研的朋友肯定想知道,到底微软帮我们做了些什么,让我们在它的框架下 ...
- MFC六大核心机制
MFC六大核心机制概述 我们选择了C++,主要是因为它够艺术.够自由,使用它我们可以实现各种想法,而MFC将多种可灵活使用的功能封装起来,我们岂能忍受这种“黑盒”操作?于是研究分析MFC的核心机制成为 ...
- JAVA基础之两种核心机制
突然之间需要学习Java,学校里学的东西早就忘记了,得用最短的时间把Java知识理顺,重点还是J2EE,毕竟所有的ava项目中95%都是J2EE,还是先从基础的J2SE学起吧....... 首先是了解 ...
随机推荐
- 目标检测 | Farthest Point Sampling 及其 CUDA 实现
Farthest Point Sampling 及其 CUDA 实现 目录 Farthest Point Sampling 及其 CUDA 实现 概述 均匀随机采样 Farthest Point Sa ...
- 基于标签值分布的强化学习推荐算法(Reinforcement Learning Recommendation Algorithm Based on Label Value Distribution)
前言 看论文的第三天,坚持下去. 慢慢来,比较快. -- 唐迟 本文基于2023年6月28日发表在MATHEMATICS上的一篇名为"基于标签值分布的强化学习推荐算法"(Reinf ...
- deepseek: php测试代码执行用时
在 PHP 中,你可以使用 microtime() 函数来测量代码的执行时间.microtime() 函数返回当前 Unix 时间戳的微秒数.你可以在代码的开始和结束处分别调用 microtime() ...
- 经由同个文件多次压缩的文件MD5都不一样问题排查,感慨AI的强大!
开心一刻 今天点了个外卖:牛肉炒饭 外卖到了后,发现并没有牛肉,我找商家理论 我:老板,这个牛肉炒饭的配菜是哪些? 商家:青菜 豆芽 火腿 鸡蛋 葱花 我:没有牛肉? 商家:亲,没有的哦 我:我点的牛 ...
- C/C++显示类型转换的位拓展方式
最近用verilator写模块的tb,在这里卡了好久(测半天都是C++写的问题) 要点 变量从小位宽到大位宽显示类型转换(explicit cast)时的位拓展方式,取决于转换前变量的符号性. 倘若转 ...
- AXUI前端框架v3版本已经发布,底层完全改写,基于原生技术标准,想走得更远!
AXUI的v3版本已经发布! AXUI框架已经经历了第一代和第二代的迭代,充分认识到纯CSS和HTML的局限性,也意识到过多手动编写代码会影响用户体验.因此,AXUI的目标是:既满足原生前端的标准,又 ...
- 数据库MVCC详解
MVCC 1.基本介绍 数据库:MySQL.[很多主流数据库都使用了MVCC,比如MySQL的InnoDB引擎.PostgreSQL.Oracle] MVCC,全称Multi-Version Conc ...
- 3.14 + 1e10 - 1e10 = 0 ? ——浮点数的本质
3.14 + 1e10 - 1e10 = 0 ? --浮点数的本质 我们先看这样一个例子: #include <iostream> int main(int argc, char **ar ...
- Python的日志
Python的日志,看上去啰啰嗦嗦的.请大神写了个通俗易懂简单方便通用的日志: import logging # 配置日志记录级别和输出方式 logging.basicConfig(level=log ...
- Web前端入门第 27 问:你知道 CSS 被浏览器分为了几大类吗?
埋头苦写多年的 CSS,从没注意到 CSS 被浏览器分了类,直到偶然的一次翻阅开发者工具,才发现原来 CSS 属性也被浏览器归类收纳了. Chrome 下面是 Chrome 的开发者工具中 CSS 的 ...