Word2vector原理
词向量:
用一个向量的形式表示一个词
词向量的一种表示方式是one-hot的表示形式:首先,统计出语料中的所有词汇,然后对每个词汇编号,针对每个词建立V维的向量,向量的每个维度表示一个词,所以,对应编号位置上的维度数值为1,其他维度全为0。这种方式存在问题并且引发新的质疑:1)无法衡量相关词之间的距离 2)V维表示语义空间是否有必要
词向量获取方式:
1)基于奇异值分解的方法
a、单词-文档矩阵
基于的假设:相关词往往出现在同一文档中,例如,banks 和 bonds, stocks,money 更相关且常出现在一篇文档中,而 banks 和 octous, banana, hockey 不太可能同时出现在一起。因此,可以建立词和文档的矩阵,通过对此矩阵做奇异值分解,可以获取词的向量表示。
b、单词-单词矩阵
基于的假设:一个词的含义由上下文信息决定,那么两个词之间的上下文相似,是否可推测二者非常相似。设定上下文窗口,统计建立词和词之间的共现矩阵,通过对矩阵做奇异值分解获得词向量。
2)基于迭代的方法
目前基于迭代的方法获取词向量大多是基于语言模型的训练得到的,对于一个合理的句子,希望语言模型能够给予一个较大的概率,同理,对于一个不合理的句子,给予较小的概率评估。具体的形式化表示如下:


第一个公式:一元语言模型,假设当前词的概率只和自己有关;第二个公式:二元语言模型,假设当前词的概率和前一个词有关。那么问题来了,如何从语料库中学习给定上下文预测当前词的概率值呢?
a、Continuous Bag of Words Model(CBOW)
给定上下文预测目标词的概率分布,例如,给定{The,cat,(),over,the,puddle}预测中心词是jumped的概率,模型的结构如下:

如何训练该模型呢?首先定义目标函数,随后通过梯度下降法,优化此神经网络。目标函数可以采用交叉熵函数:

由于yj是one-hot的表示方式,只有当yj=i 时,目标函数才不为0,因此,目标函数变为:

代入预测值的计算公式,目标函数可转化为:

b、Skip-Gram Model
skip-gram模型是给定目标词预测上下文的概率值,模型的结构如下:

同理,对于skip-ngram模型也需要设定一个目标函数,随后采用优化方法找到该model的最佳参数解,目标函数如下:

分析上述model发现,预概率时的softmax操作,需要计算隐藏层和输出层所有V中单词之间的概率,这是一个非常耗时的操作,因此,为了优化模型的训练,minkov文中提到Hierarchical softmax 和 Negative sampling 两种方法对上述模型进行训练,具体详细的推导可以参考文献1和文献2。
word2vec中用到两个重要模型:CBOW模型和Skip-gram模型。
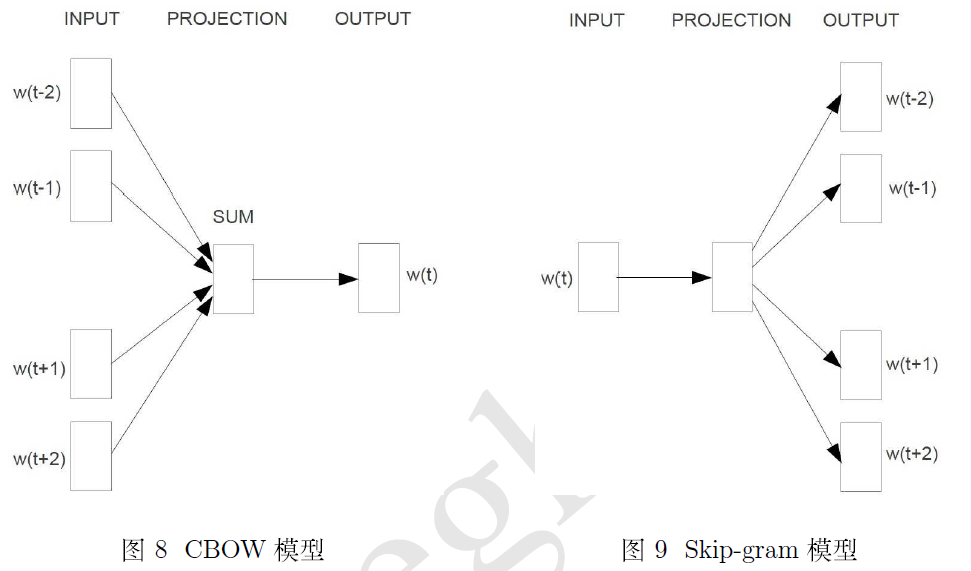
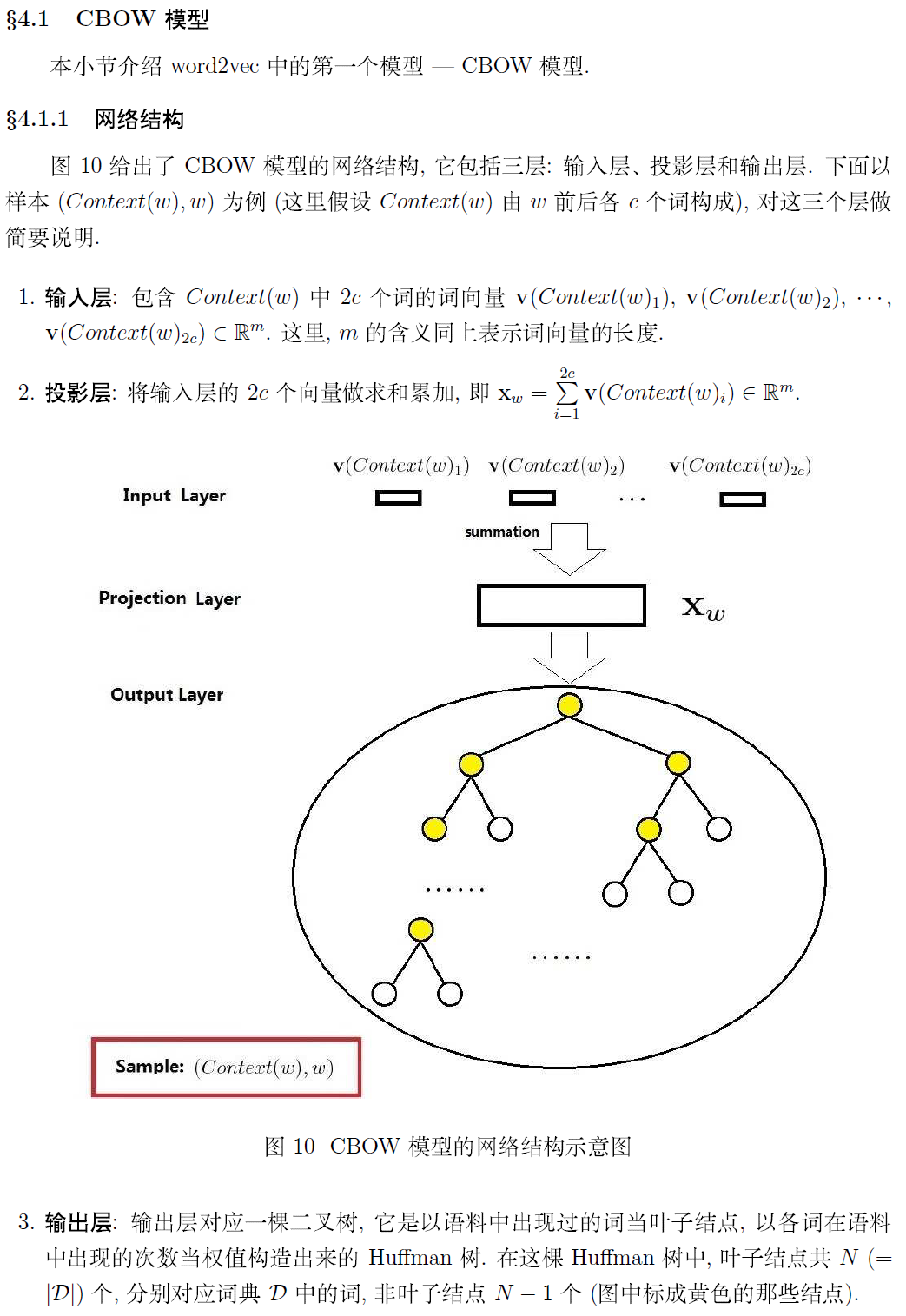
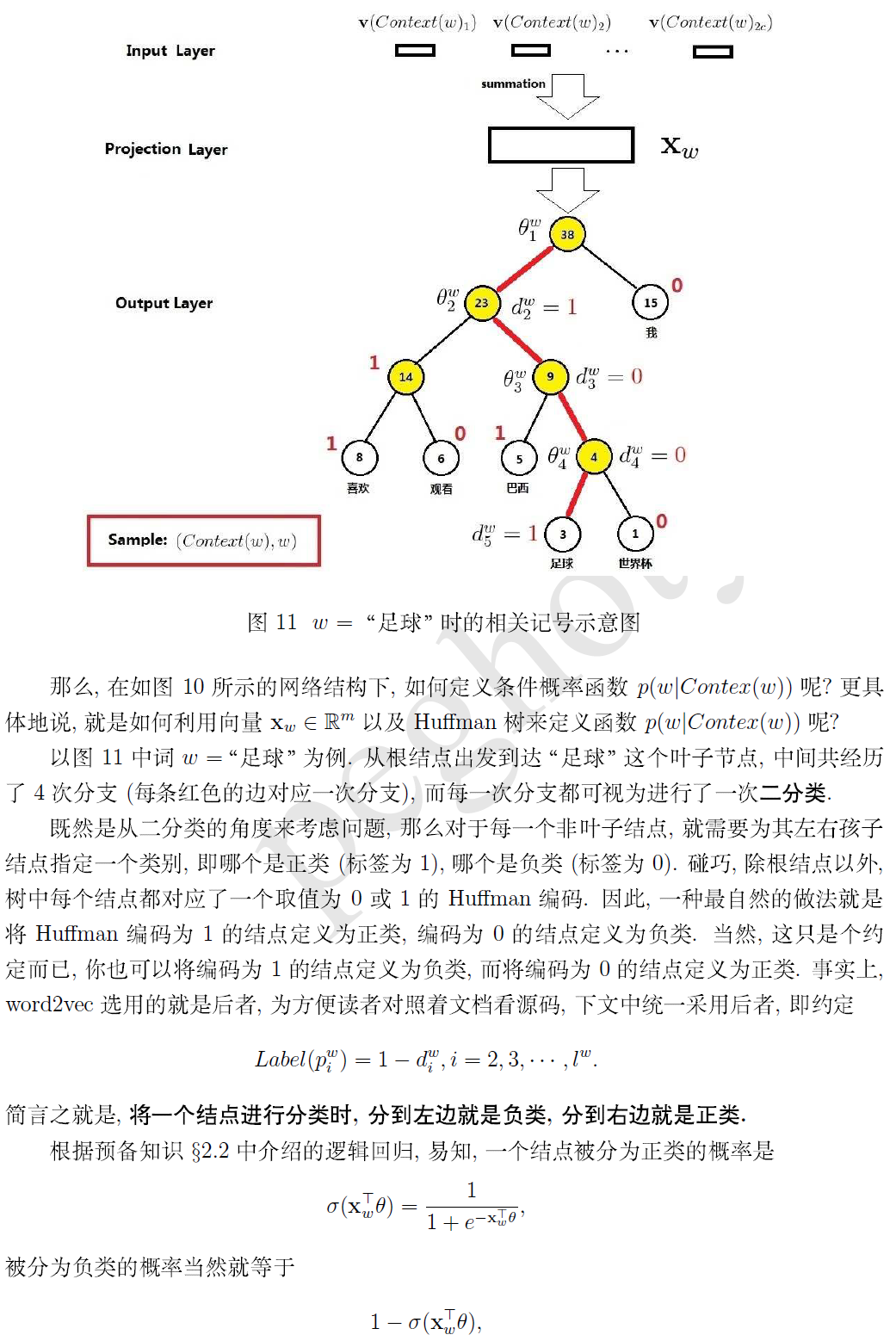
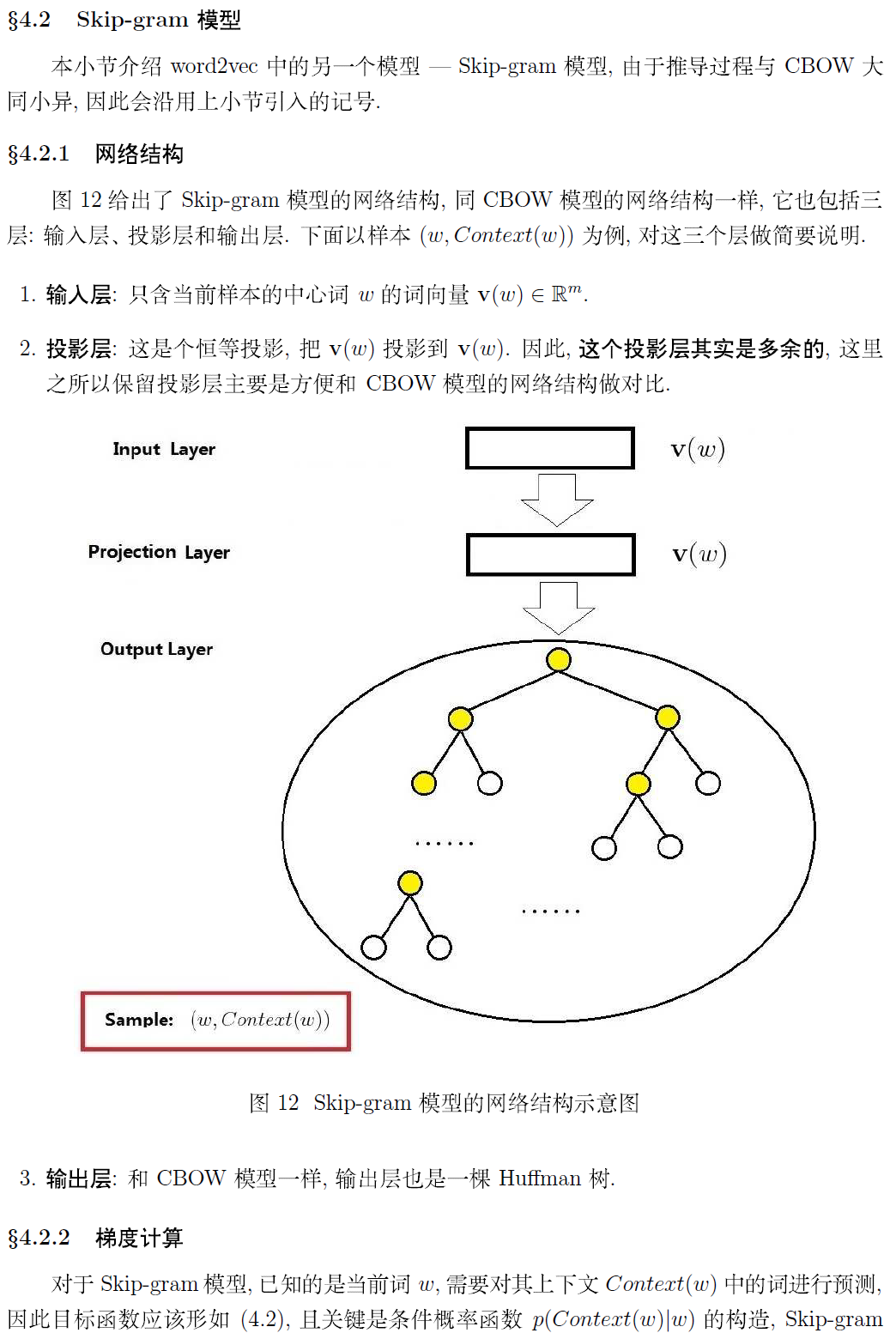
对于CBOW和Skip-gram两个模型,Word2Vec给出了两套框架,它们分别基于Hier-archical Softmax 和Negative Sampling来进行设计。本文介绍基于Hierarchical Softmax的CBOW和Skip-gram模型。






Word2vector原理的更多相关文章
- 词向量之Word2vector原理浅析
原文地址:https://www.jianshu.com/p/b2da4d94a122 一.概述 本文主要是从deep learning for nlp课程的讲义中学习.总结google word2v ...
- word2vector 理解入门
1.什么是word2vector? 我们先来看一个问题,假如有一个句子 " the dog bark at the mailman". 假如用向量来表示每个单词,我们最先想到的是用 ...
- word2vector代码实践
引子 在上次的 <word2vector论文笔记>中大致介绍了两种词向量训练方法的原理及优劣,这篇咱们以skip-gram算法为例来代码实践一把. 当前教程参考:A Word2Vec Ke ...
- 奇异值分解(SVD)原理与在降维中的应用
奇异值分解(Singular Value Decomposition,以下简称SVD)是在机器学习领域广泛应用的算法,它不光可以用于降维算法中的特征分解,还可以用于推荐系统,以及自然语言处理等领域.是 ...
- node.js学习(三)简单的node程序&&模块简单使用&&commonJS规范&&深入理解模块原理
一.一个简单的node程序 1.新建一个txt文件 2.修改后缀 修改之后会弹出这个,点击"是" 3.运行test.js 源文件 使用node.js运行之后的. 如果该路径下没有该 ...
- 线性判别分析LDA原理总结
在主成分分析(PCA)原理总结中,我们对降维算法PCA做了总结.这里我们就对另外一种经典的降维方法线性判别分析(Linear Discriminant Analysis, 以下简称LDA)做一个总结. ...
- [原] KVM 虚拟化原理探究(1)— overview
KVM 虚拟化原理探究- overview 标签(空格分隔): KVM 写在前面的话 本文不介绍kvm和qemu的基本安装操作,希望读者具有一定的KVM实践经验.同时希望借此系列博客,能够对KVM底层 ...
- H5单页面手势滑屏切换原理
H5单页面手势滑屏切换是采用HTML5 触摸事件(Touch) 和 CSS3动画(Transform,Transition)来实现的,效果图如下所示,本文简单说一下其实现原理和主要思路. 1.实现原理 ...
- .NET Core中间件的注册和管道的构建(1)---- 注册和构建原理
.NET Core中间件的注册和管道的构建(1)---- 注册和构建原理 0x00 问题的产生 管道是.NET Core中非常关键的一个概念,很多重要的组件都以中间件的形式存在,包括权限管理.会话管理 ...
随机推荐
- windows 使用git上传代码至github
1. 首先创建github账户 2. 创建github项目 3. windows安装git工具 ·下载地址:https://git-for-windows.github.io/ ,下载直接安装即可, ...
- GIMP中的新建Layer与更改Layer大小
这边可以直接New Layer,新建一个Layer,还可以New from Visible,第二种是将当前的状态下图像复制出来. 改变Layer的大小,一般的方法两种: Crop to Selecti ...
- verilog behavioral modeling--overview
1.verilog behavioral models contain procedural statements that control the simulation and manipulate ...
- python--初识html前端
一.HTML文档结构 最基本的HTML文档: <!DOCTYPE html> <html lang="zh-CN"> #这个lang表示语言,zh-CN是中 ...
- spring-boot-mustach-template
spring模板引擎mustache https://www.baeldung.com/spring-boot-mustache 这篇文章文件的名字都是.html结尾自己试了下并不行 需要将.html ...
- jmeter压力测试入门
http://www.51testing.com/html/80/n-853680.html http://blog.csdn.net/vincy_zhao/article/details/70238 ...
- 一丶Python模块之getpass模块
Python模块之getpass模块 Python 模块(Module),是一个 Python 文件,以 .py 结尾,包含了 Python 对象定义和Python语句. getpass模块提供了可移 ...
- Appium+python自动化-appium元素定位
前言 appium定位app上的元素,可以通过id,name.class这些属性定位到 一.id定位 1.appium的id属性也就是通过UI Automator工具查看的resource-id属性
- Sort a linked list in O(n log n) time using constant space complexity.
因为题目要求复杂度为O(nlogn),故可以考虑归并排序的思想. 归并排序的一般步骤为: 1)将待排序数组(链表)取中点并一分为二: 2)递归地对左半部分进行归并排序: 3)递归地对右半部分进行归并排 ...
- Linux 文件/文件夹重命名
mv命令既可以重命名,又可以移动文件或文件夹. 例子:将目录A重命名为Bmv A B 例子:将/a目录移动到/b下,并重命名为cmv /a /b/c 其实在文本模式中要重命名文件或目录,只需要使用mv ...