python爬虫框架—Scrapy安装及创建项目
linux版本安装
- pip3 install scrapy
安装完成
windows版本安装
- pip install wheel
- 下载twisted,网址:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted,选择好与系统对应的版本
- cmd切换到twisted文件目录,执行安装命令:pip3 install “twisted文件名”
- pip install pywin32
- pip install scrapy
安装完成
创建scrapy工程项目
1、cmd切换到准备创建的项目目录
2、执行创建命令:scrapy startproject 项目名称
ps:项目名称必须以字母开头,只能包含数字、字母、下划线
创建好后目录如下:
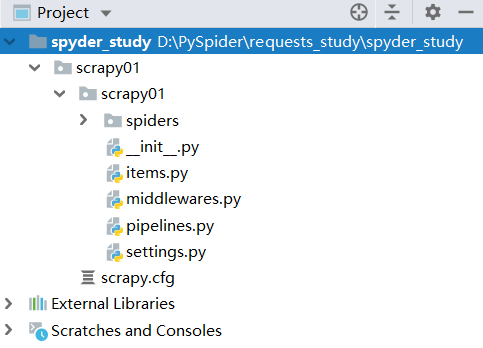
3、cmd目录切换至第四次层spiders,执行命令创建爬虫文件:scrapy genspider "爬虫文件名称" 将要爬取的url (这里的名称和url都可以创建好后更改,所以先简单创一个) ;
4、执行工程,启动爬虫项目:scrapy crawl "爬虫项目名称" (创建的爬虫文件类中的 name 属性值)
over,接下来逐步总结具体使用方式
python爬虫框架—Scrapy安装及创建项目的更多相关文章
- Python爬虫框架Scrapy安装使用步骤
一.爬虫框架Scarpy简介Scrapy 是一个快速的高层次的屏幕抓取和网页爬虫框架,爬取网站,从网站页面得到结构化的数据,它有着广泛的用途,从数据挖掘到监测和自动测试,Scrapy完全用Python ...
- Python爬虫框架--Scrapy安装以及简单实用
scrapy框架 框架 -具有很多功能且具有很强通用性的一个项目模板 环境安装: Linux: pip3 install scrapy Windows: ...
- Linux 安装python爬虫框架 scrapy
Linux 安装python爬虫框架 scrapy http://scrapy.org/ Scrapy是python最好用的一个爬虫框架.要求: python2.7.x. 1. Ubuntu14.04 ...
- 教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http://www.xiaohuar.com/,让你体验爬取校花的成就感. Scr ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Python爬虫框架Scrapy实例(三)数据存储到MongoDB
Python爬虫框架Scrapy实例(三)数据存储到MongoDB任务目标:爬取豆瓣电影top250,将数据存储到MongoDB中. items.py文件复制代码# -*- coding: utf-8 ...
- Python爬虫框架Scrapy教程(1)—入门
最近实验室的项目中有一个需求是这样的,需要爬取若干个(数目不小)网站发布的文章元数据(标题.时间.正文等).问题是这些网站都很老旧和小众,当然也不可能遵守 Microdata 这类标准.这时候所有网页 ...
- 《Python3网络爬虫开发实战》PDF+源代码+《精通Python爬虫框架Scrapy》中英文PDF源代码
下载:https://pan.baidu.com/s/1oejHek3Vmu0ZYvp4w9ZLsw <Python 3网络爬虫开发实战>中文PDF+源代码 下载:https://pan. ...
- 《精通Python爬虫框架Scrapy》学习资料
<精通Python爬虫框架Scrapy>学习资料 百度网盘:https://pan.baidu.com/s/1ACOYulLLpp9J7Q7src2rVA
随机推荐
- (6)css盒子模型(基础下)
一.理解多个盒子模型之间的相互关系 现在大部分的网页都是很复杂的,原因是一个“给人用的”网页中是可能存在着大量的盒子,并且它们以各种关系相互影响着. html与DOM的关系 详情了解“DOM” :ht ...
- 【同步工具类】CountDownLatch
闭锁是一种同步工具类,可以延迟线程的进度直到其达到终止状态. 作用:相当于一扇门,在到达结束状态之前,这扇门一直是关闭的,并且没有任务线程能够通过,当到达结束状态时,这扇门会打开并允许所有的线程通过, ...
- linux 文件查阅 cat、more、less、tail
文件内容查阅1.cat由第一行开始显示文件内容2.tac:从最后一行开始显示,可以看出tac是cat的倒写形式.3.nl:显示的时候,顺便输出行号;4.more:一页一页地显示文件内容5.less:与 ...
- 深入理解Android
http://blog.csdn.net/innost/article/details/47254381
- CMake学习笔记二:cmake 常用变量和常用环境变量
1 cmake 变量引用的方式 使用 ${} 进行变量的引用.在 IF 等语句中,是直接使用变量名而不通过 ${} 取值. 2 cmake 自定义变量的方式 主要有隐式定义和显式定义两种,举一个隐式定 ...
- 1.1.2最小生成树(Kruskal和Prim算法)
部分内容摘自 勿在浮沙筑高台 http://blog.csdn.net/luoshixian099/article/details/51908175 关于图的几个概念定义: 连通图:在无向图中,若任意 ...
- ACM复习专项
资料整理 ACM训练营 邝斌的ACM模板 牛客网哈理工ACM教学视频 视频网盘资料(密码:kntr) 1. 训练阶段 第一阶段:练习经典常用算法 (本周任务) 1. 最短路(Floyd.Dijstra ...
- 题解报告:hdu 1260 Tickets
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1260 Problem Description Jesus, what a great movie! T ...
- 转】用Hadoop构建电影推荐系统
原博文出自于: http://blog.fens.me/hadoop-mapreduce-recommend/ 感谢! 用Hadoop构建电影推荐系统 Hadoop家族系列文章,主要介绍Hadoop家 ...
- ASP.NET Core MVC使用MessagePack配合前端fetch交换数据
1.安装Nuget包 - WebApiContrib.Core.Formatter.MessagePack https://www.nuget.org/packages/WebApiContrib.C ...