seq2seq(1)- EncoderDecoder架构
零
seq2seq是从序列到序列的学习过程,最重要的是输入序列和输出序列是可变长的,这种方式就非常灵活了,典型的机器翻译就是这样一个过程。
一
最基本的seq2seq网络架构如下所示:
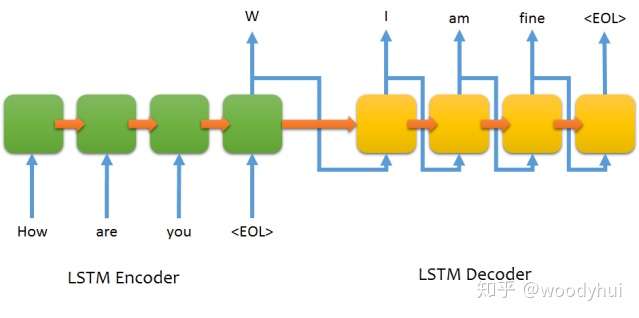
可以看到,encoder构成一个RNN的网络,decoder也是一个RNN的网络。训练过程和推断过程有一些不太一样的地方,介绍如下。
训练过程:
- encoder构成一个RNN网络,输入为源语言的文本,输出最后一个timestep的hidden state,同时不需要output,将最后一个hidden state作为decoder的初始化state;
- decoder也构成一个RNN网络,输入为目标语言的文本,这个地方要注意的是输入需要往后lag一个位置,输出就是正常的目标语言文本即可,选用categorical cross entropy进行多分类训练。
# input sentence
How are you
# output sentence
I am fine
# encoder input
["How", "are", "you"]
# decoder input
["<start tag>", "I", "am", "fine"]
# decoder target
["I", "am", "fine", "<end tag>"]推断过程:
推断过程只有encoder input了,所以有个greedy/sampling/beam-search等decoding的方法,下面讨论最简单的greedy方法。
- 将源语言的输入经过encoder编码成最后timestep的hidden state;
- 目标语言的输入设定成一个单词<start tag>,喂给decoder,产出一个目标单词;
- 将上一步的目标的单词作为目标语言新的输入,继续2的步骤,直到遇到<end tag>,或者产生的预测sequence长度超过阈值。
二
以上就是最基本的seq2seq架构,优点就是简单,缺点也很明显,我们人类一般翻译文本的时候,目标语言单词往往只和源语言文本其中有限一两个单词有关,而上面的做法,将源语言文本编码成一个固定长度的hidden state,导致decoder过程中每个单词都是受固定state的影响,而没有差异化和重点,由此下一篇会介绍seq2seq优化的比较重要的一个机制 - Attention Mechanism。
seq2seq(1)- EncoderDecoder架构的更多相关文章
- 6. 从Encoder-Decoder(Seq2Seq)理解Attention的本质
1. 语言模型 2. Attention Is All You Need(Transformer)算法原理解析 3. ELMo算法原理解析 4. OpenAI GPT算法原理解析 5. BERT算法原 ...
- 深度学习的seq2seq模型——本质是LSTM,训练过程是使得所有样本的p(y1,...,yT‘|x1,...,xT)概率之和最大
from:https://baijiahao.baidu.com/s?id=1584177164196579663&wfr=spider&for=pc seq2seq模型是以编码(En ...
- RNN/LSTM/GRU/seq2seq公式推导
概括:RNN 适用于处理序列数据用于预测,但却受到短时记忆的制约.LSTM 和 GRU 采用门结构来克服短时记忆的影响.门结构可以调节流经序列链的信息流.LSTM 和 GRU 被广泛地应用到语音识别. ...
- seq2seq和attention应用到文档自动摘要
一.摘要种类 抽取式摘要 直接从原文中抽取一些句子组成摘要.本质上就是个排序问题,给每个句子打分,将高分句子摘出来,再做一些去冗余(方法是MMR)等.这种方式应用最广泛,因为比较简单.经典方法有Lex ...
- seq2seq模型以及其tensorflow的简化代码实现
本文内容: 什么是seq2seq模型 Encoder-Decoder结构 常用的四种结构 带attention的seq2seq 模型的输出 seq2seq简单序列生成实现代码 一.什么是seq2seq ...
- NMT 机器翻译
本文近期学习NMT相关知识,学习大佬资料,汇总便于后期复习用,有问题,欢迎斧正. 目录 RNN Seq2Seq Attention Seq2Seq + Attention Transformer Tr ...
- TACOTRON:端到端的语音合成
tacotron主要是将文本转化为语音,采用的结构为基于encoder-decoder的Seq2Seq的结构.其中还引入了注意机制(attention mechanism).在对模型的结构进行介绍之前 ...
- CNN卷积神经网络的改进(15年最新paper)
回归正题,今天要跟大家分享的是一些 Convolutional Neural Networks(CNN)的工作. 大家都知道,CNN 最早提出时,是以一定的人眼生理结构为基础,然后逐渐定下来了一些经典 ...
- Google工程师亲授 Tensorflow2.0-入门到进阶
第1章 Tensorfow简介与环境搭建 本门课程的入门章节,简要介绍了tensorflow是什么,详细介绍了Tensorflow历史版本变迁以及tensorflow的架构和强大特性.并在Tensor ...
随机推荐
- (unix domain socket)使用udp发送>=128K的消息会报ENOBUFS的错误
一个困扰我两天的问题, Google和Baidu没有找到解决方法! 此文为记录这个问题,并给出原因和解决方法. 1.Unix domain socket简介 unix域协议并不是一个实际的协议族,而是 ...
- 从0开始学习Hadoop(1) 环境准备 Win7环境+VirtureBox+Ubuntu
虚拟机:VirtureBox 3.18 下载地址: https://www.virtualbox.org/ 操作系统:Ubuntu 版本:ubuntu-15.04-desktop-amd64.iso ...
- EF通过反射追踪修改记录.适合记录变更系统
private static void IsUpdate<T>(T old, T current, string id) { Model.PerFileHistory history = ...
- C++实现用两个栈实现队列
/* * 用两个栈实现队列.cpp * * Created on: 2018年4月7日 * Author: soyo */ #include<iostream> #include<s ...
- docker 端口被占用问题解决
启动容器A, A的端口映射是 80:8080 外部的25000端口映射到服务内部的8080端口:有时候将容器关闭,重新构建镜像及启动容器时会出现一些报错, 比如端口被占用的报错,但通过docker p ...
- Python生成器实现斐波那契数列
比如,斐波那契数列:1,1,2,3,5,8,13,21,34.... 用列表生成式写不出来,但是我们可以用函数把它打印出来: def fib(number): n, a, b = 0, 0, 1 wh ...
- bzoj1233 [Usaco2009Open]干草堆tower 【单调队列dp】
传送门:http://www.lydsy.com/JudgeOnline/problem.php?id=1233 单调队列优化的第一题,搞了好久啊,跟一开始入手斜率优化时感觉差不多... 这一题想通了 ...
- C# 基础知识和VS2010的小技巧总汇(2)[转]
1.使用关键字readonly ,表示这个字段只能在执行构造函数的过程中赋值,或者由初始化语句赋值 2..net4.0新增一个 Tuple 类,代表一个有序的N元组.可以调用Tuple.Create ...
- this关键字的构造方法的使用
package com.wh.Object3; public class this_Demo { private String name; private double price; private ...
- java数组实现买彩票(二个一维数组的比较思想)
/** 设计一个程序,模拟从彩球池里随机抽取5个彩球(彩球池里一共有11个彩球,编号为1~11), 要求在控制台打印出这5个被取出来的彩球的编号(注意编号不能重复). 思路: 1.创建一个int类型的 ...