DeepMind:所谓SACX学习范式
机器人是否能应用于服务最终还是那两条腿值多少钱,而与人交互,能真正地做“服务”工作,还是看那两条胳膊怎么工作。大脑的智能化还是非常遥远的,还是先把感受器和效应器做好才是王道。
关于强化学习,根据Agent对策略的主动性不同划分为主动强化学习(学习策略:必须自己决定采取什么行动)和被动强化学习(固定的策略决定其行为,为评价学习,即Agent如何从成功与失败中、回报与惩罚中进行学习,学习效用函数)。
被动强化学习:EnforceLearning-被动强化学习
主动强化学习:EnforceLearning-主动强化学习
文章:SACX新范式,训练用于机器人抓取任务
DeepMind提出调度辅助控制(Scheduled Auxiliary Control,SACX),这是强化学习(RL)上下文中一种新型的学习范式。SAC-X能够在存在多个稀疏奖励信号的情况下,从头开始(from scratch)学习复杂行为。为此,智能体配备了一套通用的辅助任务,它试图通过off-policy强化学习同时从中进行学习。
这个长向量的形式化以及优化为论文的亮点。
由四个基本准则组成:状态配备多个稀疏奖惩向量-一个稀疏的长向量;每个奖惩被分配策略-称为意图,通过最大化累计奖惩向量反馈;建立一个高层的选择执行特定意图的机制用以提高Agent的表现;学习是基于off-policy(新策略,Q值更新使用新策略),且意图之间的经验共享增加效率。总体方法可以应用于通用领域,在此我们以典型的机器人任务进行演示。
基于Off-Play的好处:https://www.zhihu.com/question/57159315
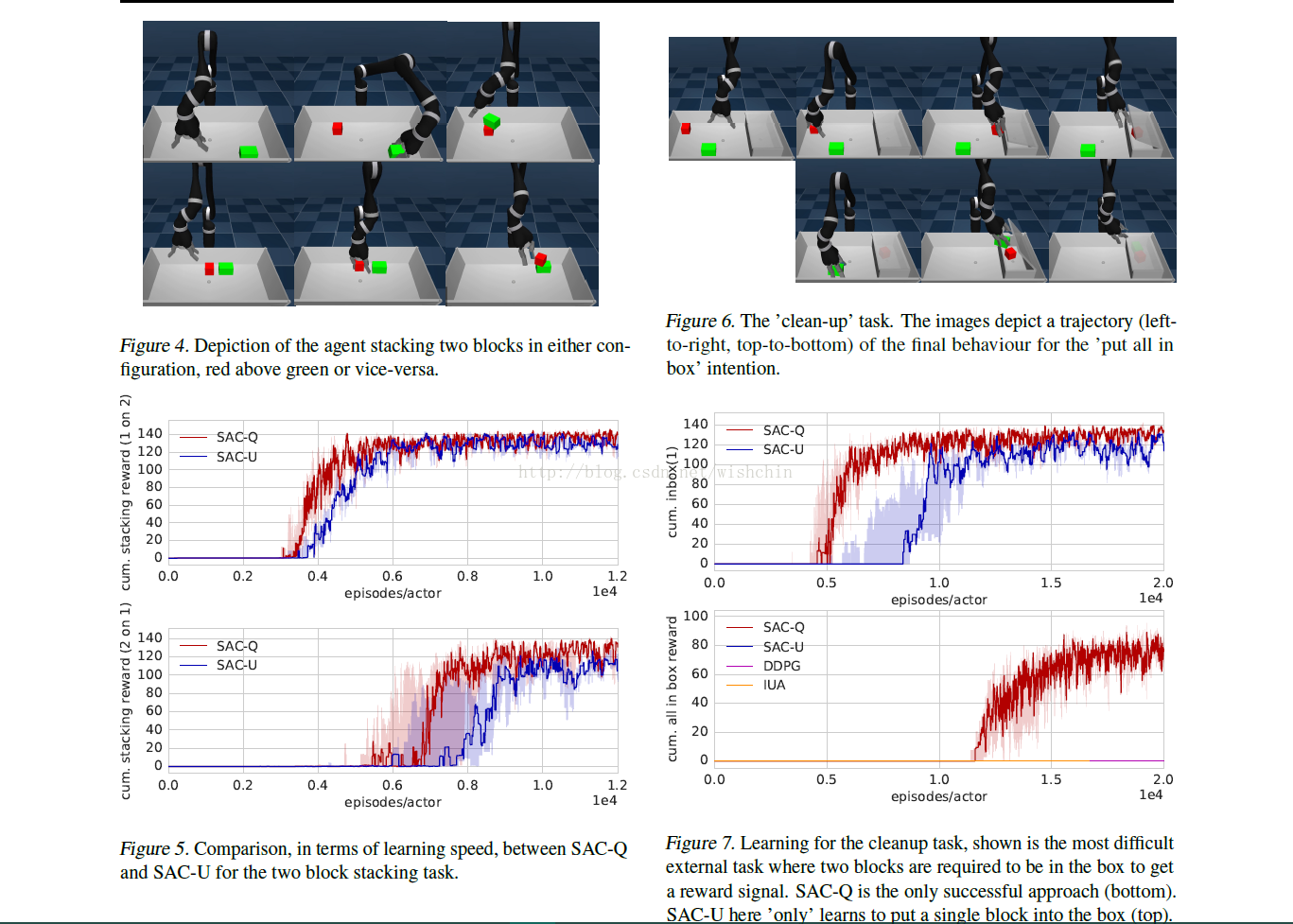
论文:Learning by Playing – Solving Sparse Reward Tasks from Scratch
DeepMind:所谓SACX学习范式的更多相关文章
- 学习世界模型,通向AI的下一步:Yann LeCun在IJCAI 2018上的演讲
https://baijiahao.baidu.com/s?id=1606296521706399213&wfr=spider&for=pc 机器之心整理,机器之心编辑部. 人工智能顶 ...
- 学习笔记TF037:实现强化学习策略网络
强化学习(Reinforcement Learing),机器学习重要分支,解决连续决策问题.强化学习问题三概念,环境状态(Environment State).行动(Action).奖励(Reward ...
- 深度学习在CTR预估中的应用
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由鹅厂优文发表于云+社区专栏 一.前言 二.深度学习模型 1. Factorization-machine(FM) FM = LR+ e ...
- 学界| UC Berkeley提出新型分布式框架Ray:实时动态学习的开端—— AI 应用的系统需求:支持(a)异质、并行计算,(b)动态任务图,(c)高吞吐量和低延迟的调度,以及(d)透明的容错性。
学界| UC Berkeley提出新型分布式框架Ray:实时动态学习的开端 from:https://baijia.baidu.com/s?id=1587367874517247282&wfr ...
- AI面试必备/深度学习100问1-50题答案解析
AI面试必备/深度学习100问1-50题答案解析 2018年09月04日 15:42:07 刀客123 阅读数 2020更多 分类专栏: 机器学习 转载:https://blog.csdn.net ...
- Generalizing from a Few Examples: A Survey on Few-Shot Learning(从几个例子总结经验:少样本学习综述)
摘要:人工智能在数据密集型应用中取得了成功,但它缺乏从有限的示例中学习的能力.为了解决这一问题,提出了少镜头学习(FSL).利用先验知识,可以快速地从有限监督经验的新任务中归纳出来.为了全面了解FSL ...
- 13.深度学习(词嵌入)与自然语言处理--HanLP实现
笔记转载于GitHub项目:https://github.com/NLP-LOVE/Introduction-NLP 13. 深度学习与自然语言处理 13.1 传统方法的局限 前面已经讲过了隐马尔可夫 ...
- Flink + 强化学习 搭建实时推荐系统
如今的推荐系统,对于实时性的要求越来越高,实时推荐的流程大致可以概括为这样: 推荐系统对于用户的请求产生推荐,用户对推荐结果作出反馈 (购买/点击/离开等等),推荐系统再根据用户反馈作出新的推荐.这个 ...
- MySQL数据库基础-2范式
数据库结构设计 范式 设计数据库的规范 第12345范式,凡是之间有依赖关系. 关系模型的发明者埃德加·科德最早提出这一概念,并于1970 年代初定义了第一范式.第二范式和第三范式的概念 设计关系数据 ...
随机推荐
- C#——await与async实现多线程异步编程
曾经,我们也许用过Thread.在主线程运行的时候.新开还有一个新线程,来运行新方法. 今天看别人发给我的一段代码的时候发现了一个不认识的await,可是又感觉非常熟悉的样子,感觉是线程那块儿的东西, ...
- Android进程间通信之内部类作为事件监听器
在Android中,使用内部类能够在当前类里面发用改监听器类,由于监听器类是外部类的内部类.所以能够自由訪问外部类的全部界面组件. 下面是一个调用系统内部类实现短信发送的一个样例: SMS类: pac ...
- Kinect驱动的人脸实时动画
近期几年.realtime的人脸动画開始风声水起.不少图形图像的研究者開始在这个领域不断的在顶级会议siggraph和期刊tog上面发文章. 随着kinect等便宜的三维数据採集设备的运用.以及其功能 ...
- Linux/UNIX之进程环境
进程环境 进程终止 有8种方式使进程终止,当中5中为正常终止,它们是 1) 从main返回 2) 调用exit 3) 调用_exit或_Exit 4) 最后一个 ...
- android菜鸟之路-事件分发机制总结(二)
ViewGroup事件分发机制 自己定义一个LinearLayout,ImageView和Button,小二,上代码 <LinearLayout xmlns:android="http ...
- WWDC笔记:2013 Session 201 Building User Interfaces for iOS 7
Text Dynamic Type Specifies fonts semantically Supports user text sizing Optimized for legibility Su ...
- A program to print Fahrenheit-Celsius table with floating-point values
我的主力博客:半亩方塘 Another program to print Fahrenheit-Celsius table with decimal integer This program is p ...
- 【bzoj1406】[AHOI2007]密码箱
x2 ≡ 1 mod n => x2 = k * n + 1 => n | (x + 1) * (x - 1) 令n = a * b,则 (a | x + 1 且 b | x - 1) 或 ...
- go1
关键字: break default func interface select case defer go map struct chan else goto package switch cons ...
- override (C# Reference)
https://msdn.microsoft.com/en-us/library/ebca9ah3.aspx The override modifier is required to extend o ...