深入理解map系列--HashMap(一)
Map系列之HashMap(源码基于java8)
HashMap是我们最常用的map实现之一,这篇文章将会介绍HashMap内部是如何工作的,以及内部的数据结构是怎样的
一、数据结构简图
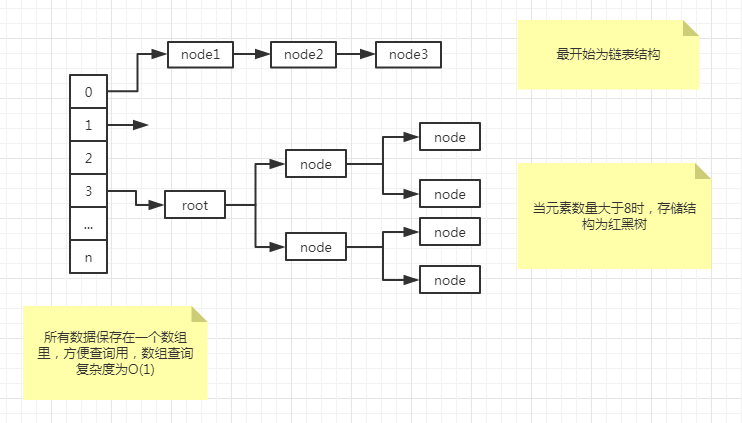
二、源码解析
首先看下Map接口里常用的几个方法:
V put(K key, V value);
V get(Object key);
V remove(Object key);
boolean containsKey(Object key);
上面是常用的主要操作方法,下面来看下map的基本存储单位Entry:
interface Entry<K,V> {
K getKey(); //返回当前存储数据里的key
V getValue(); //返回当前存储数据里的value
V setValue(V value); //给value赋值
boolean equals(Object o); //重写equals方法
int hashCode(); //重写hashCode方法
}然后我们来看下HashMap里对该接口的实现:
// 基本存储结构,可以看出来这是一个简单的链表结构,这里的实现类叫Node
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; //根据key计算出来的哈希值
final K key; //数据键
V value; //数据值
Node<K,V> next; //下一个数据节点
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
// 判等,要求k,v必须满足相等才行
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry e = (Map.Entry)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}我们再来看看hash值的计算,在哈希表中,哈希值取决了散列度,最终插入的数据会分布到哪个数组下标下,hash值起着至关重要的作用:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
下面我们来看看具体插入数据时做的操作,具体解释已经加上注释:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
HashMap.Node<K,V>[] tab; //存储链表的数组结构
HashMap.Node<K,V> p; //被插入的元素链表头部元素
int n, i; //n表示当前哈希表数组长度,i表示本次插入元素被分配的下标
if ((tab = table) == null || (n = tab.length) == 0) { //表示哈希表数组还未被初始化
n = (tab = resize()).length; //初始化,resize用来扩容
}
//表示当前(下标由最大下标值和当前元素哈希值位运算得出)位置还没有任何链表结构,这时直接初始化即可
if ((p = tab[i = (n - 1) & hash]) == null) {
tab[i] = newNode(hash, key, value, null);
} else { // 否则,需要进行链表数据插入的操作,注意现在p已经是计算出来的链表头元素了
HashMap.Node<K,V> e;
K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k)))) {
e = p; // 若发现插入的数据跟p哈希值、key完全一致,则直接让新插入的数据等于p即可
} else if (p instanceof HashMap.TreeNode){ // 结合下面的代码,链表深度大于8后,就是个红黑树结构了,这时启用下面的代码加入新数据
e = ((HashMap.TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
} else { // 说明插入的是新元素
for (int binCount = 0; ; ++binCount) { // 遍历链表
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null); //插入链表尾部
if (binCount >= TREEIFY_THRESHOLD - 1) // java8新引入的概念,当链表深度大于8时,就转换为红黑树结构了
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
break; // 若发现遍历过程中存在与插入值一致的,直接break
}
p = e;
}
}
if (e != null) { // 说明未成功插入
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue; // 返回已存在的旧值
}
}
++modCount;
if (++size > threshold) { //新插入值后,满足扩容条件则进行扩容
resize(); //扩容
}
afterNodeInsertion(evict);
return null;
}由于java8做了根据元素数量,转换成红黑树结构的优化处理,所以上述代码中会掺杂一些相关的代码,这里先不用关心,我们按照最基本的哈希表结构来看就行,下一讲将会分析红黑树结构。
我们接下来来看下get方法:
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}然后getNode方法:
final HashMap.Node<K,V> getNode(int hash, Object key) {
HashMap.Node<K,V>[] tab; //哈希表数组
HashMap.Node<K,V> first, e; //根据hash查找数组内的第一个元素
int n; K k; // n表示数组长度
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) { // 根据下标(下标由最大下标值和当前元素哈希值位运算得出)获取当前对应第一个元素(链表或者红黑树的根元素)
if (first.hash == hash && // 检查第一个节点的key是否等于当前查找的key,若等,直接返回
((k = first.key) == key || (key != null && key.equals(k)))){
return first;
}
// 否则继续遍历查找
if ((e = first.next) != null) {
if (first instanceof HashMap.TreeNode) { //红黑树结构的查询
return ((HashMap.TreeNode<K,V>)first).getTreeNode(hash, key);
}
// 普通链表结构遍历查询,查到直接返回
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))){
return e;
}
} while ((e = e.next) != null);
}
}
return null;
}
ok,上面说完了put和get,现在我们来看下remove,也是先抛开红黑树不谈,只看链表部分,会很容易:
public V remove(Object key) {
HashMap.Node<K, V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
final HashMap.Node<K, V> removeNode(int hash, Object key, Object value, boolean matchValue, boolean movable) {
HashMap.Node<K, V>[] tab; //哈希表数组
HashMap.Node<K, V> p; //需要被移除的元素所属的根元素
int n, index; //n表示数组长度,index表示需要被移除元素根元素位于数组的下标值
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
HashMap.Node<K, V> node = null, e; // node表示最终需要被移除的元素
K k;
V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k)))) {
node = p; // 若根元素就等于需要被移除的元素,则直接将node赋值为p
} else if ((e = p.next) != null) { // 否则继续往下查找,结构依然分为两种,红黑树暂不看
if (p instanceof HashMap.TreeNode) {
node = ((HashMap.TreeNode<K, V>) p).getTreeNode(hash, key);
} else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break; // 找到对应的元素,break
}
p = e; // 找不到对应元素时,让p一直下移(e.next)
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof HashMap.TreeNode) { //红黑树移除
((HashMap.TreeNode<K, V>) node).removeTreeNode(this, tab, movable);
} else if (node == p) { // 待移除元素等于根元素时,直接让对应下标下的数组元素赋值为根元素的下一个值
tab[index] = node.next;
} else { //否则,就进行链表正常删除逻辑,让被移除元素的前一个元素(为什么现在的p是前一个元素呢?因为在上述do while操作时已经重新赋值了)的下一个值指向被移除元素的下一个值
p.next = node.next;
}
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}好了,目前基本上把重要的一些操作给介绍完了,现在再看下containsKay这个方法,这个方法极度简单,直接调用getNode方法判空即可:
public boolean containsKey(Object key) {
return getNode(hash(key), key) != null;
}本篇的侧重点在于HashMap在使用纯链表时的插入、移除、查找方式,下一篇将会介绍HashMap如何扩容数组、以及在启用红黑树结构下,会如何做插入、移除、查找这几种操作方式。
深入理解map系列--HashMap(一)的更多相关文章
- Java 集合系列14之 Map总结(HashMap, Hashtable, TreeMap, WeakHashMap等使用场景)
概要 学完了Map的全部内容,我们再回头开开Map的框架图. 本章内容包括:第1部分 Map概括第2部分 HashMap和Hashtable异同第3部分 HashMap和WeakHashMap异同 转 ...
- Map,HashMap,LinkedHashMap,TreeMap比较和理解
/* * 获取功能: * V get(Object key):根据键获取值 * Set<K> keySet():获取集合中所有键的集合 * Collection<V> valu ...
- Java基础系列--HashMap(JDK1.8)
原创作品,可以转载,但是请标注出处地址:https://www.cnblogs.com/V1haoge/p/10022092.html Java基础系列-HashMap 1.8 概述 HashMap是 ...
- Java Se :Map 系列
之前对Java Se中的线性表作了简单的说明.这一篇就来看看Map. Map系列的类,并不是说所有的类都继承了Map接口,而是说他们的元素都是以<Key, Value>形式设计的. Dic ...
- 【转】java 容器类使用 Collection,Map,HashMap,hashTable,TreeMap,List,Vector,ArrayList的区别
原文网址:http://www.360doc.com/content/15/0427/22/1709014_466468021.shtml java 容器类使用 Collection,Map,Hash ...
- java容器类2:Map及HashMap深入解读
Java的编程过程中经常会和Map打交道,现在我们来一起了解一下Map的底层实现,其中的思想结构对我们平时接口设计和编程也有一定借鉴作用.(以下接口分析都是以jdk1.8源码为参考依据) 1. Map ...
- 深入理解Spring系列之七:web应用自动装配Spring配置
转载 https://mp.weixin.qq.com/s/Lf4akWFmcyn9ZVGUYNi0Lw 在<深入理解Spring系列之一:开篇>的示例代码中使用如下方式去加载Spring ...
- 深入理解Spring系列之三:BeanFactory解析
转载 https://mp.weixin.qq.com/s?__biz=MzI0NjUxNTY5Nw==&mid=2247483824&idx=1&sn=9b7c2603093 ...
- 深入理解JavaScript系列(22):S.O.L.I.D五大原则之依赖倒置原则DIP
前言 本章我们要讲解的是S.O.L.I.D五大原则JavaScript语言实现的第5篇,依赖倒置原则LSP(The Dependency Inversion Principle ). 英文原文:htt ...
随机推荐
- Undo Architecture
[Undo Architecture] NSUndoManager is a general-purpose recorder of operations for undo and redo. NSU ...
- serialVersionUID的作用以及IDEA、Eclipse如何自动生成serialVersionUID
说到serialVersionUID,首先要讲讲序列化. 序列化: 序列化可以将一个java对象以二进制流的方式在网络中传输并且可以被持久化到数据库.文件系统中,反序列化则是可以把之前持久化在数据库或 ...
- WCF Service 配置文件注释(转)
<?xml version="1.0" encoding="utf-8" ?> <configuration> <system.S ...
- [转]WCF体系结构-一张图就是好
本文转自:http://www.cnblogs.com/snakevash/archive/2011/05/02/2034414.html 今天在MSDN上面看到了这么一张图,让我顿时感觉脑袋清醒很多 ...
- 23 DesignPatterns学习笔记:C++语言实现 --- 2.2 Adapter
23 DesignPatterns学习笔记:C++语言实现 --- 2.2 Adapter 2016-07-22 (www.cnblogs.com/icmzn) 模式理解
- Spring IOC 和 AOP概述
IoC(控制反转,(Inversion of Control):本来是由应用程序管理的对象之间的依赖关系,现在交给了容器管理,这就叫控制反转,即交给了IoC容器,Spring的IoC容器主要使用DI方 ...
- 注解Annotation补充介绍
摘抄http://www.cnblogs.com/peida/archive/2013/04/23/3036035.html 什么是注解(Annotation): Annotation(注解)就是Ja ...
- Android-应用安装/替换/卸载/广播监听
在上一篇博客Android-开关机的广播,中介绍了,如何订阅接收者,去接收系统发送的开机/关机广播, 而这篇博客是订阅接收者 去接收应用的(安装/替换/卸载) 三种广播 订阅 接收者 去接收 应用的 ...
- C# 使用ProcessStartInfo调用exe获取不到重定向数据的解决方案
emmmmm,最近在研究WFDB工具箱,C语言写的,无奈本人C语言功底不够,只想直接拿来用,于是打算通过ProcessStartInfo来调取编译出来的exe程序获取输出. 一开始就打算偷懒,从园子里 ...
- Winform窗体改变语言类型的方式
Winform改变语言类型比较复杂,需要根据不同语言应用语言资源.而软件在进行语言切换时,需要将当前的UI文化线程引用对应的语言类型.常用的有三种方式,此处使用两种,对比发现其中的优缺点: /// & ...