linux平台 spark standalone集群 使用 start-all,stop-all 管理集群的启动和退出
一、配置/etc/profile:
文件尾部增加以下内容:
export SPARK_HOME=/home/spark/spark-2.2.0-bin-hadoop2.7
export PATH=$PATH:${SPARK_HOME}/bin
export SPARK_EXAMPLES_JAR=$SPARK_HOME/examples/jars/spark-examples_2.11-2.2.0.jar
二、配置spark环境变量
在spark的conf文件夹中复制 spark-env.sh.template生成 spark-env.sh文件,在尾部添加如下代码:
export JAVA_HOME=/home/java/jdk1.8.0_161
export PATH=$PATH:$JAVA_HOME/bin
export SPARK_MASTER_HOST="10.217.2.240"
第三行的变量指定的是master的IP,我的机器上面worker节点不能直接根据hostname找到master,所以必须要在这里声明masterIP,worker才能连接到master
三、配置worker节点ip:
在spark的conf文件夹中复制 slaves.template生成 slaves文件,在尾部添加如下代码:
localhost
10.217.2.241
10.217.2.242
这里配置的是worker的ip,我这里的意思就是在本地和后面两个节点都启动worker,一共3个worker。
以上三点配置必须在所有节点上同步
四、配置ssh:
运行start-all.sh脚本的机器必须要有所有worker节点的访问权,所以要么是在环境变量中配置各个节点的登陆密码,要么就配置ssh密钥登陆,ssh更方便些。在本节点生成密钥 ,ssh-keygen -t rsa,
然后将密钥拷贝到所有worker节点的authorized_keys中,注意由于这里我把本机也设为worker节点,所以在本机的 authorized_keys 文件中也要放公钥。
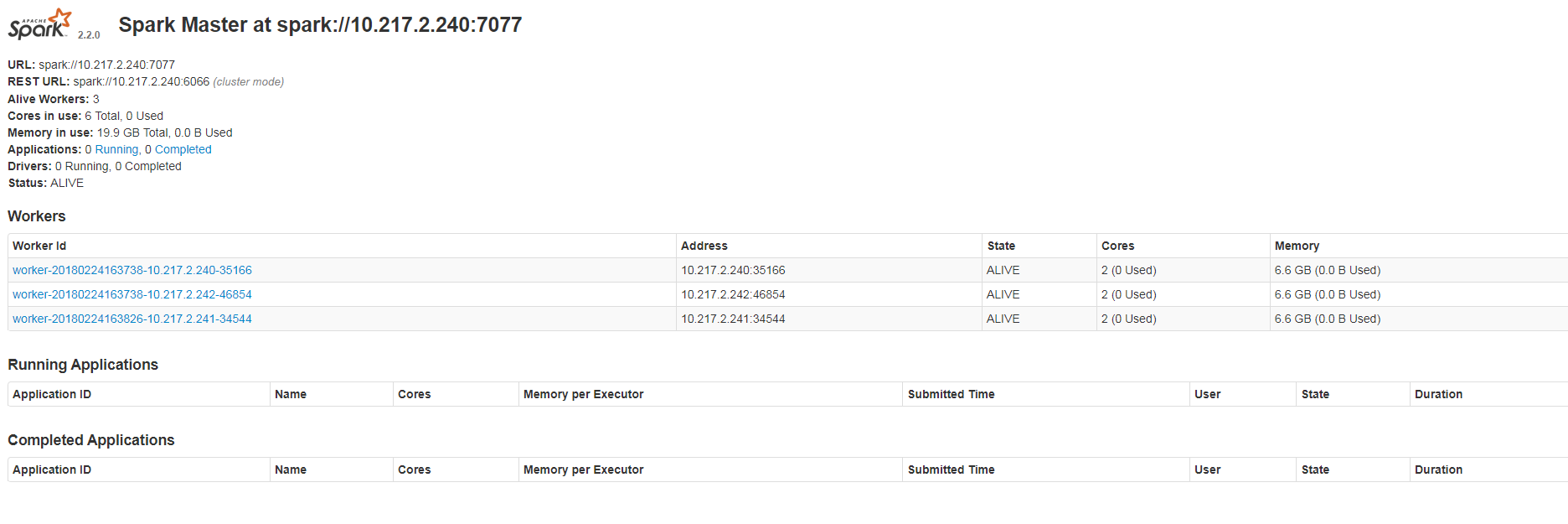
五、运行start-all.sh,稍等一会,然后就可以在masterUI中看到启动成功了.
linux平台 spark standalone集群 使用 start-all,stop-all 管理集群的启动和退出的更多相关文章
- linux 平台实现 web 服务器的自动化发布 (纯shell 版本,存在ssh 不能自动退出问题,待解决)
转至:https://www.cnblogs.com/vmsky/p/13824172.html 背景说明 1.集团OA系统上线,web App 部署在6台服务器中,因项目初期,每次更新都需要进行大量 ...
- 【原】Spark Standalone模式
Spark Standalone模式 安装Spark Standalone集群 手动启动集群 集群创建脚本 提交应用到集群 创建Spark应用 资源调度及分配 监控与日志 与Hadoop共存 配置网络 ...
- 大数据学习day18----第三阶段spark01--------0.前言(分布式运算框架的核心思想,MR与Spark的比较,spark可以怎么运行,spark提交到spark集群的方式)1. spark(standalone模式)的安装 2. Spark各个角色的功能 3.SparkShell的使用,spark编程入门(wordcount案例)
0.前言 0.1 分布式运算框架的核心思想(此处以MR运行在yarn上为例) 提交job时,resourcemanager(图中写成了master)会根据数据的量以及工作的复杂度,解析工作量,从而 ...
- (二)win7下用Intelij IDEA 远程调试spark standalone 集群
关于这个spark的环境搭建了好久,踩了一堆坑,今天 环境: WIN7笔记本 spark 集群(4个虚拟机搭建的) Intelij IDEA15 scala-2.10.4 java-1.7.0 版本 ...
- Spark standalone安装(最小化集群部署)
Spark standalone安装-最小化集群部署(Spark官方建议使用Standalone模式) 集群规划: 主机 IP ...
- 04、Spark Standalone集群搭建
04.Spark Standalone集群搭建 4.1 集群概述 独立模式是Spark集群模式之一,需要在多台节点上安装spark软件包,并分别启动master节点和worker节点.master节点 ...
- Linux平台上搭建apache+tomcat负载均衡集群
传统的Java Web项目是通过tomcat来运行和发布的.但在实际的企业应用环境中,采用单一的tomcat来维持项目的运行是不现实的.tomcat 处理能力低,效率低,承受并发小(1000左右).当 ...
- 高性能Linux服务器 第11章 构建高可用的LVS负载均衡集群
高性能Linux服务器 第11章 构建高可用的LVS负载均衡集群 libnet软件包<-依赖-heartbeat(包含ldirectord插件(需要perl-MailTools的rpm包)) l ...
- spark集群搭建(三台虚拟机)——kafka集群搭建(4)
!!!该系列使用三台虚拟机搭建一个完整的spark集群,集群环境如下: virtualBox5.2.Ubuntu14.04.securecrt7.3.6_x64英文版(连接虚拟机) jdk1.7.0. ...
随机推荐
- python random模块(随机数)详解
使用前要先导入random模块 import random random.randomrandom.random()用于生成一个0到1的随机符点数: 0 <= n < 1.0 random ...
- 【白银组】codevs_1160 蛇形矩阵
#include <iostream> using namespace std; #define M 100 int a[M][M]; void pt( int n ) { for ( i ...
- ELF文件和BIN文件
文件的内容:1. BIN文件是 raw binary 文件,这种文件只包含机器码.2. ELF文件除了机器码外,还包含其它额外的信息,如段的加载地址,运行地址,重定位表,符号表等. 所以ELF文件的体 ...
- emacs之配置symbol浏览界面
由于ecb的method-buffer不能更新,因此抛弃ecb,speedbar的method也不能更新,换imenu-tree 使用el-get install安装imenu-tree imenu- ...
- node使用JsonWebToken 生成token,完成用户登录、登录检测
最近在用node做后台的登录,检测登录功能.在本地使用session可以成功,但是放服务器后发现session失效了,每次请求session都会变化,着了很久原因.原来,自己项目是前后端分离的,前端调 ...
- Python格式化输出%s和%d
python print格式化输出. 1. 打印字符串 print ("His name is %s"%("Aviad")) 效果: 2.打印整数 print ...
- 关于Selenium HTMLTestRunner 无法生成测试报告
解决方法 1: filename = ‘E:\testresult.html’,如果是在windows环境,文件名要使用以下几种格式. ①filename = 'E:\\testresult.html ...
- sql 存储过程返回值 变量名
return 语句返回值,前台调用的参数名称为 @RETURN_VALUE
- socket & pipe note
[socket & pipe note] 1.socket类型 2.大小端 3.socketpair 如何创建全双工管道? 直接的办法当然是pipe两次,创建两组管道,但是有没有更简单的呢? ...
- Spring分配置文件开发
---------------------siwuxie095 Spring 分配置文件开发 Spring 分配置文件开 ...