ADF 第六篇:Copy Data Activity详解
在Azure 数据工程中,可以使用Copy Data 活动把数据从on-premises 或云中复制到其他存储中。Copy Data 活动必须在一个IR(Integration Runtime)上运行,对于把存储在on-premises中的数据复制到其他存储时,必须创建一个self-hosted Integration Runtime。
一,认识Copy Data Activity
创建一个Pipeline,从Activities列表中找到“Copy data”,拖放到Pipeline画布中,如下图所示:
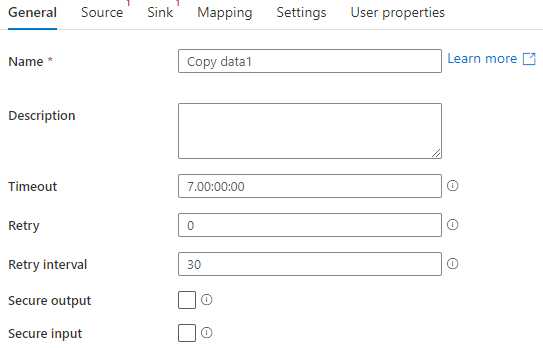
在General选项卡中,设置Activity的常规属性
- Name:为Activity命名
- Timeout:设置Activity的超时时间
- Retry:重试次数
- Retry interval:重试一次间隔的时间,单位是second
- Secure output:安全输出,如果勾选,那么该Activity的输出不会记录
- Secure input:安全入,如果勾选,那么该Activity的输入不会记录
二,设置源属性
Source选项卡用于设置Copy data Activity的源属性,
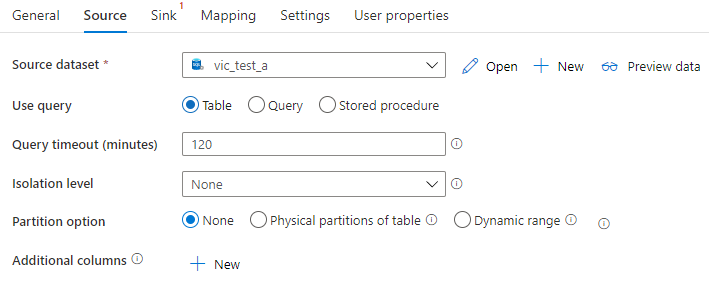
1,Source 的常规设置
Source dataset:设置源的dataset
use query:Table选项表示整个表作为一个数据源,Query或 Store procedure选项表示使用查询语句或存储过程来获取数据源。
Query timeout(minutes):表示查询超时的时间
Isolation level:设置查询隔离级别,作用于数据源。
2,Partition option
指定从SQL Server加载数据的分区选项,当启用分区选项时(不是None),从SQL Server 同时加载数据的并发度由Copy data Activity的Degree of copy parallelism属性设置。Physical Partitions Of Table表示数据工厂根据原始表的分区定义来确定分区列和分区机制;当选择Dynamic range选项时,用户还需要设置Partition column name、Partition upper bound 和Partition lower bound三项,手动设置分区列和分区机制。

3,Additional columns
添加额外的列,Value由三种类型:Add dynamic content、$$COLUMN和Custom。

$$COLUMN:表示把源的指定列复制为另一列
Custom:表示添加一列,列指是常量
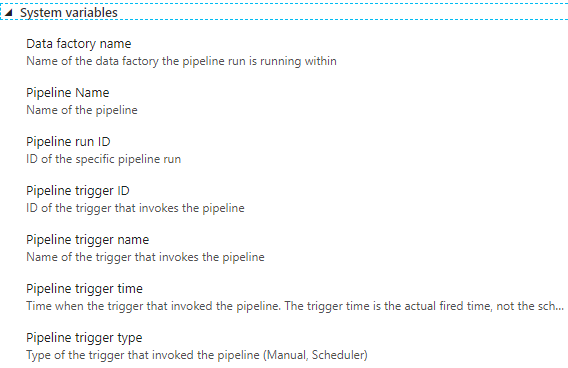
Add dynamic content,表示添加动态上下文(Dynamic Content),动态上下文是指数据工厂的上下文,这些动态上下文由系统变量(System variables)来提供:
三,设置Sink
Sink是Copy Data Activity复制数据的目标数据集,Data Factory 使用 Sink dataset来设置目标。
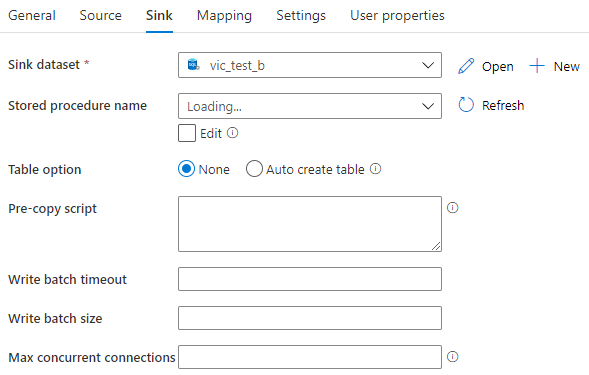
1,Store procedure name
从Sink dataset中选择存储过程,该存储过程定义了如何把元数据应用于目标表。该存储过程每个batch调用一次,对于仅运行一次且与源数据无关的操作,请使用 Pre-copy script 属性。
如果使用Pre-copy script 属性,通常意味着数据是全量更新,重写整个表,比如以下脚本:
truncate table staging_table
Copy data activity的执行过程是:每次执行Copy data activity,数据工厂首先执行Pre-copy script,然后使用最新的数据插入数据到target table。
如果使用存储过程,通常是对数据进行增量更新,要实现增量更新,实际上是把数据集作为参数传递给存储过程,这就意味着存储过程的一个参数必须是表变量类型,存储过程的代码实现如下脚本所示,
CREATE PROCEDURE spOverwriteMarketing
@Marketing [dbo].[MarketingType] READONLY
, @category varchar(256)
AS
BEGIN
MERGE [dbo].[Marketing] AS target
USING @Marketing AS source
ON (target.ProfileID = source.ProfileID and target.Category = @category)
WHEN MATCHED THEN
UPDATE SET State = source.State
WHEN NOT MATCHED THEN
INSERT (ProfileID, State, Category)
VALUES (source.ProfileID, source.State, source.Category);
END
2,Table option
如果设置为Auto create table,那么当目标表不存在时,数据工厂根据Source 的元数据自动创建目标表。
3,常规设置
Write batch timeout:每个batch数据写入的超时时间
Write batch size:每个batch的数据行数量
Max concurrent connections:访问数据存储的最大的并发连接数量
四,设置Mapping
在Mapping选项卡中,主要设置Source 和 Sink之间的列映射
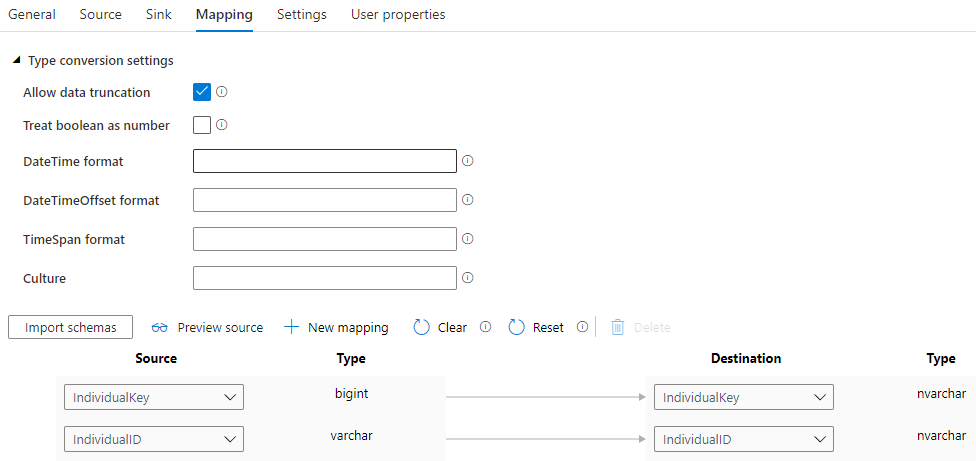
1,Type conversion settings用于设置类型转换
- Allow data truncation: 在把source数据转换到sink时,如果字段的类型不同,允许数据截断。
- Treat boolean as number:把bool值作为数值来看待,把true看作1,把false看作1
- DateTime format:DateTime类型的格式
- DateTimeOffset format:数据间隔的格式
- TimeSpan format:TimeSpan的格式
- Culture:locale
2,列映射
设置列与列之间的映射关系,用户需要点击“Import schemas”来导入架构元数据。
五,设置Settings
配置Copy data Activity的设置
1,常规的设置
- Data integration unit:数据集成的单元
- Degree of copy parallelism:指定数据加载时并发度
- Data consistency verification:当勾选时,Copy data Activity会在数据移动之后,对数据进行一致性检查
- Enable logging:启用日志,记录复制的文件,跳过的数据行和文件
- Enable staging:指定是否要通过临时存储来复制数据
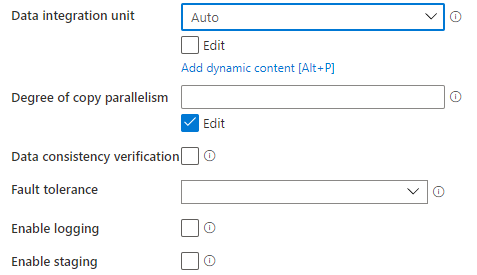
2,设置Fault tolerance
当设置Fault tolerance (错误容忍)之后,用户可以忽略在复制数据过程中出现的一些错误,可以忽略的错误类型主要有三个:
- Skip incompatible rows:跳过不兼容的行
- Skip missing files:跳过缺失的文件
- Skip forbidden files:跳过禁止的文件
六,数据更新的全量更新和增量更新
数据更新的方式主要有:全量更新、追加数据、增量更新。
1,数据的全量更新和追加更新
如果使用Pre-copy script 属性,通常意味着数据是全量更新和追加更新。
在插入数据之前,如果先清空目标表,再向目标表插入数据,这种方式是全量更新;如果不清空目标表,只是向目标表插入新的数据,那么就是追加更新,前提是保证数据是无重复的新数据。
2,通过存储过程来实现Copy data Activity的增量更新
如果Sink属性使用存储过程,那么是对数据进行增量更新。实现数据的增量更新,实际上是把数据集作为参数传递给存储过程,这就意味着存储过程的一个参数必须是表变量类型。
由于存储过程在连接表变量时,性能较差,建议对分batch插入,每个batch进行一次插入操作。
创建一个表类型,作为存储过程的参数,表的架构和输入数据的架构相同:
CREATE TYPE [dbo].[MarketingType] AS TABLE
(
[ProfileID] [varchar](256) NOT NULL,
[State] [varchar](256) NOT NULL,
[Category] [varchar](256) NOT NULL
)
创建存储过程,第一个变量是表变量,该存储过程的作用是把表变量的数据更新到Sink指定的target table中。
CREATE PROCEDURE spOverwriteMarketing
@Marketing [dbo].[MarketingType] READONLY
, @category varchar(256)
AS
BEGIN
MERGE [dbo].[Marketing] AS target
USING @Marketing AS source
ON (target.ProfileID = source.ProfileID and target.Category = @category)
WHEN MATCHED THEN
UPDATE SET State = source.State
WHEN NOT MATCHED THEN
INSERT (ProfileID, State, Category)
VALUES (source.ProfileID, source.State, source.Category);
END
3,使用临时表来实现增量更新
先把数据加载到临时表,通过merge语句把临时数据归并到product table。
参考文档:
Copy data to and from SQL Server by using Azure Data Factory
Copy activity in Azure Data Factory
ADF 第六篇:Copy Data Activity详解的更多相关文章
- EnjoyingSoft之Mule ESB开发教程第六篇:Data Transform - 数据转换
目录 1. 数据转换概念 2. 数据智能感知 - DataSense 3. 简单数据转换组件 3.1 Object to JSON 3.2 JSON to XML 3.3 JSON to Object ...
- 《手把手教你》系列基础篇(九十六)-java+ selenium自动化测试-框架之设计篇-跨浏览器(详解教程)
1.简介 从这一篇开始介绍和分享Java+Selenium+POM的简单自动化测试框架设计.第一个设计点,就是支持跨浏览器测试. 宏哥自己认为的支持跨浏览器测试就是:同一个测试用例,支持用不同浏览器去 ...
- [安卓基础] 009.组件Activity详解
*:first-child { margin-top: 0 !important; } body > *:last-child { margin-bottom: 0 !important; } ...
- SaltStack 入门到精通第二篇:Salt-master配置文件详解
SaltStack 入门到精通第二篇:Salt-master配置文件详解 转自(coocla):http://blog.coocla.org/301.html 原本想要重新翻译salt-mas ...
- Farseer.net轻量级开源框架 入门篇:添加数据详解
导航 目 录:Farseer.net轻量级开源框架 目录 上一篇:Farseer.net轻量级开源框架 入门篇: 分类逻辑层 下一篇:Farseer.net轻量级开源框架 入门篇: 修改数据详解 ...
- Farseer.net轻量级开源框架 入门篇:修改数据详解
导航 目 录:Farseer.net轻量级开源框架 目录 上一篇:Farseer.net轻量级开源框架 入门篇: 添加数据详解 下一篇:Farseer.net轻量级开源框架 入门篇: 删除数据详解 ...
- Farseer.net轻量级开源框架 入门篇:删除数据详解
导航 目 录:Farseer.net轻量级开源框架 目录 上一篇:Farseer.net轻量级开源框架 入门篇: 修改数据详解 下一篇:Farseer.net轻量级开源框架 入门篇: 查询数据详解 ...
- Farseer.net轻量级开源框架 入门篇:查询数据详解
导航 目 录:Farseer.net轻量级开源框架 目录 上一篇:Farseer.net轻量级开源框架 入门篇: 删除数据详解 下一篇:Farseer.net轻量级开源框架 中级篇: Where条 ...
- Mysql高手系列 - 第19篇:mysql游标详解,此技能可用于救火
Mysql系列的目标是:通过这个系列从入门到全面掌握一个高级开发所需要的全部技能. 这是Mysql系列第19篇. 环境:mysql5.7.25,cmd命令中进行演示. 代码中被[]包含的表示可选,|符 ...
随机推荐
- yii2.0 中数据查询中 or、in、between 及session的使用
1 HTML: 2 3 <div> 4 <form class="form-inline " method="get" action=&quo ...
- Django之ModelForm实际操作使用
1.定义model数据库字段如下: class User(models.Model): """ 员工信息表用户.密码.职位.公司名(子.总公司).手机.最后一次登录时间. ...
- 新手上路A4——多JDK环境变量的配置
目录 配置单个JDK的方法 配置2+JDK的方法 方法 补充 检查JDK版本是否切换成功 前面讲了如何选择Java版本. 以及JDK8和JDK11的下载安装配置 有想法的人就开始发动他们优秀的小脑袋瓜 ...
- 软件工程与UML 第一次个人作业
这个作业属于哪个课程 https://edu.cnblogs.com/campus/fzzcxy/2018SE1/ 这个作业要求在哪里 https://edu.cnblogs.com/campus/f ...
- sqlmap工具的简单使用
0x00 sqlmap简介:sqlmap是一款针对sql漏洞的自动化注入工具,有一个非常棒的特性,即对检测与利用的自动化处理(数据库指纹.访问底层文件系统.执行命令). 官方网站下载http://sq ...
- 第4.4节 Python解析与推导:列表解析、字典解析、集合解析
一. 引言 经过前几个章节的介绍,终于把与列表解析的前置内容介绍完了,本节老猿将列表解析.字典解析.集合解析进行统一的介绍. 前面章节老猿好几次说到了要介绍列表解析,但老猿认为涉及知识层面比较多 ...
- Python中import模块时报SyntaxError: (unicode error)utf-8 codec can not decode 错误的解决办法
老猿有个通过UE编辑(其他文本编辑器一样有类似问题)的bmi.py文件,在Python Idle环境打开文件执行时没有问题,但import时报错: SyntaxError: (unicode erro ...
- 第15.19节 PyQt(Python+Qt)入门学习:自定义信号与槽连接
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 一.引言 本文利用中介绍了PyQt中的信号和槽机制,除了使用PyQt组件的已有信号外,PyQt和Qt ...
- XFF SSTI 模板注入 [BJDCTF2020]The mystery of ip
转自https://www.cnblogs.com/wangtanzhi/p/12328083.html SSTI模板注入:之前也写过:https://www.cnblogs.com/wangtanz ...
- CVE申请+挖掘指南
CVE的全称是"Common Vulnerabilities and Exposures"翻译成中文就是"公共漏洞和披露" 可以简单理解跟国内CNVD的通用漏洞 ...